저는 이번에 Anomaly Detection 관련 논문으로 리뷰를 써보고자 합니다. Anomaly Detection에 대해 접하면서새롭게 알아보는 것이기 때문에, 최대한 다양한 방법론을 접해보고 것도 좋을 것 같아, 기존 김지원, 김형준 연구원이 리뷰한 Unsupervised 기반이 아닌 다른 방법론의 논문을 가져왔습니다. ☺
Background
본 논문에서는 Out-of-Distribution Detection 방법론을 제안합니다. 그렇다면 먼저 Out-of-Distribution이 무엇인지 알아야겠죠. 아래 그림은 Out-of-Distribution Detection sample의 예시입니다. (그림과 내용은 이호성님의 블로그 중 Anomaly Detection 개요 [1] 에서 참고하였습니다.)
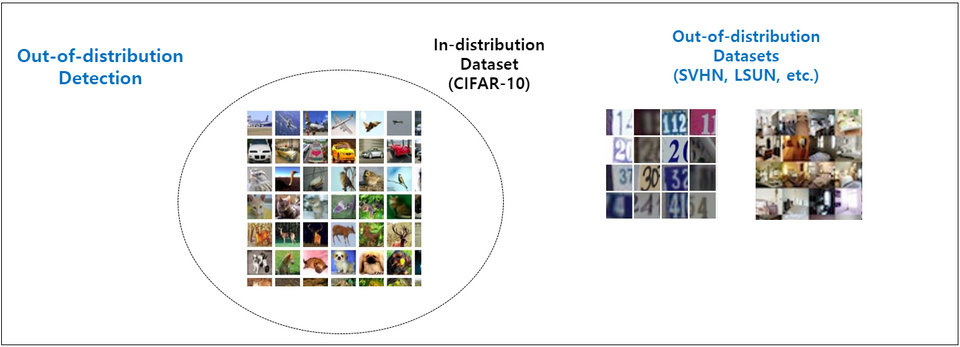
일반적인 Classification의 관점에서 Out-of-Distribution이란 학습 데이터(In-distribution)에서 정의된 class가 아닌 그 이외의 class를 의미합니다. 다시 말해 Out-of-Distribution Detection이란, 현재 보유하고 있는 In-distribution 데이터셋을 이용하여 Multi-class classification network를 학습시킨 뒤, test 단계에서 In-distribution test set은 정확하게 예측하면서 Out-of-distribution 데이터셋은 걸러내는 것을 목표로 하는 task 입니다. 위에서 보여지는 그림처럼 CIFAR-10으로 학습된 모델이라면, 학습에 사용하지 않은 숫자 관련 데이터셋인 SVHN이나 실내 이미지 데이터셋인 LSUN 등의 데이터가 바로 Out-of-Distribution 입니다.
다들 아시다시피 Classification에서는 Sofrmax 기반으로 Class 의 개수를 정해놓고, 확률이 가장 높은 Class를 결과로 출력하는 방식을 사용합니다. 이 방법론을 바탕으로 초기 Out-of-Distribution Detection을 처음 정의한 논문에서는 softmax로 Out-of-Distribution score를 구해서 Out-of-Distribution 를 걸러내는 방법으로 시작되었다고 합니다.
그렇다면 논문 제목에 있는 Outlier Exposure이란 무엇일까요? 말 그대로 OOD에 해당하는 데이터(Outlier)를 학습에 사용(Exposure)하는 것입니다. 지금까지 Out-of-Distribution (이하 OOD) 와 Outlier Exposure (이하 OE) 에 대해 알아보았으니, 이제 본격적인 논문 리뷰를 시작하겠습니다.
DEEP ANOMALY DETECTION WITH OUTLIER EXPOSURE – [ 논문 바로가기 ]

Intro
본 논문에서는 먼저 알려지지 않은 새로운 질병의 발견, 혹은 새로운 천문학 현상, 센서 고장 탐지 같은 현상을 언급하며 Anomaly Detection이 필요한 이유에 대해 설명합니다. 기존 시스템은 학습과 테스트 데이터가 유사하지만, 완전 새로운 데이터가 테스트로 들어오거나 혹은 학습 데이터와 전혀 맞지 않는 분포의 test가 들어올 경우, anomalous test examples 임에도 불구하고 high confidence prediction을 주는 경향이 있기 때문에 abnormal한 데이터를 판단하는 데에는 기존 시스템으로는 어려움이 있다고 합니다. 이를 극복하기 위해 기존 연구에서는 입력에 대한 anomaly score를 할당하는 방법으로 문제를 해결하려고 하였습니다. 다시 말해 in-distribution 데이터만 사용하여 학습시킴으로써 unmodeled한 현상을 detect를 하는 방법이 많이 사용되고 있습니다.
본 논문에서는 기존 방법론에서 auxiliary 데이터셋을 활용하여 OOD detection 성능을 높이는 방법을 제안합니다. 다시말해, OE라는 방법(모델에 OOD 일부를 학습)으로 분포가 다양하면서 현실적인 데이터셋을 활용할 수 있는 방법을 제안합니다. 뿐만아니라 다양한 실험을 통해 OE의 광범위한 활용가능성(Computer Vision 뿐만 아니라 NLP에서도 가능함을)과 일반화를 보입니다. (논문에서는 이미지 뿐만 아니라 텍스트에서도 적용 가능함을 보이지만 저는 이미지에 대한 실험에 대해서만 리뷰에 다루도록 하겠습니다)
Related Work
본 방법론을 처음 공부하기 때문에 간단하게나마 OOD Detection의 큰 흐름을 짚어가려고 합니다.
- “A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks”
- OOD Detection을 처음으로 다룬 논문이며, 본 논문의 저자와 동일한 저자이기도 합니다. (지금 리뷰하는 논문이 이 논문의 후속 논문인것이죠 ) 본 논문에서는 In-distribution 데이터 셋으로 학습시키고, test 단계에서 in-distribution 데이터와 out-of-distribution 데이터를 test 사용합니다. 이후 test에 대하여 class 개수만큼 softmax 값이 계산되는데, 이 값을 OOD score로 사용합니다. 대개 anomalous examples이 in-distribution보다 maximum softmax probability이 낮은 것을 이용하여, softmax로 나온 값중 가장 큰 값(maximum softmax probability)을 threshold로 사용합니다. 그리고 일정 threshold를 기준으로 maximum softmax probability가 threshold보다 작으면 OOD로 분류하는 방법입니다.
- “Learning confidence for out-of-distribution detection in neural networks“
- 위 Baseline 논문을 바탕으로 사전 학습된 classifier에 Confidence Branch를 추가하고 이 branch에서 새로운 OOD score인 confidence score를 산출하는 방법을 제안합니다.
- “Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks”
- ODIN이라고 불리며 input preprocessing을 통해 anomalies과 in-distribution examples 사이의 maximum softmax probability를 더욱 구별할 수 있도록 제안한 것이 main idea 입니다.
- “Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples”
- 기존 논문들과 달리 가장 큰 특징은 GAN을 사용한다는 것입니다. GAN을 사용하여 in-distribution과 유사한 OOD를 생성하고, 이를 활용하여 모델을 재학습함으로써 OOD를 탐지하는 방법을 제안하였습니다. 뿐만아니라 OOD가 덜 confident하도록 학습되도록 KL divergence 기반의 손실 함수를 제안하였습니다.
Outlier Exposure
Outlier Exposure는 기존 방법에 추가할 수 있는 새로운 방법론으로, OOD에 해당하는 데이터를 학습에 사용하여 각 방법론에서의 detection 성능을 높일 수 있었습니다. 사실 저렇게 설명하면, 예를 들어 고양이와 강아지를 분류하기 위해 사용되는 데이터에 토끼 사진 일부를 학습시키고, test로 토끼 사진을 넣었을 때 outlier로 분류할 수 있어 성능 향상을 가져왔다고 생각할 수 있지만, 그렇지 않습니다. 먼저 OE를 적용하기 위한 데이터셋은 [ D_{in}, D_{out-oe}, D_{out-test}] 로 구성되어 있으며, 여기서 D_{out-oe}, D_{out-test}는 완전 다른 데이터셋으로 구성됩니다. 이 때, D_{in}는 in-distribution, D_{out}은 out-of-distribution입니다.
Experiments
먼저 광범위한 데이터셋에서 OE를 추가하였을 때 성능이 얼마나 향상되는지를 확인하기 위해 실험을 진행합니다. 각 평가는 초기 모델을 학습하는데에 필요한 in-distribution 데이터셋인 D_{in}, anomalous examples 데이터셋인 D_{out-oe}, 그리고 OE를 적용할 baseline detector로 구성됩니다. 구체적인 데이터셋에 대해서는 4.2장에서 서술하도록 하겠습니다.
4.1 EVALUATING OUT-OF-DISTRIBUTION DETECTION METHODS
먼저 OOD point를 감지하는 것에 대한 OOD detection 방법론에 대해 평가합니다. 이를 위해 먼저 OOD example을 positive class라고 하고, 세 가지 평가 지표를 사용합니다. 1) area under the receiver operating characteristic curve (AUROC), 2) area under the precision-recall curve (AUPR) 3) the false positive rate at N% true positive rate (FPRN).
AUROC과 AUPR은 여러 threshold에 대한 detection 성능을 나타내는 평가지표입니다. AUROC는 anomalous example이 in-distribution보다 더 높은 OOD score를 받을 확률이라고 할 수 있기 때문에 높을수록 탐지가 잘 되는것이라고 할 수 있습니다. ROC 커브는 positive class와 negative class의 sample 개수가 다른 경우에 이를 반영하지 못하기 때문에 추가로 Precision-Recall 커브의 면적인 AUPR을 사용했다고 합니다. 즉, AUPR은 anomalous exapmle이 드물게 발생할 경우(positive와 negative class 개수가 많이 차이날 때) 유용하다고 합니다. 또한 모든 실험에서 D_{test-out}:D_{test-in} 의 비율은 1:5입니다.
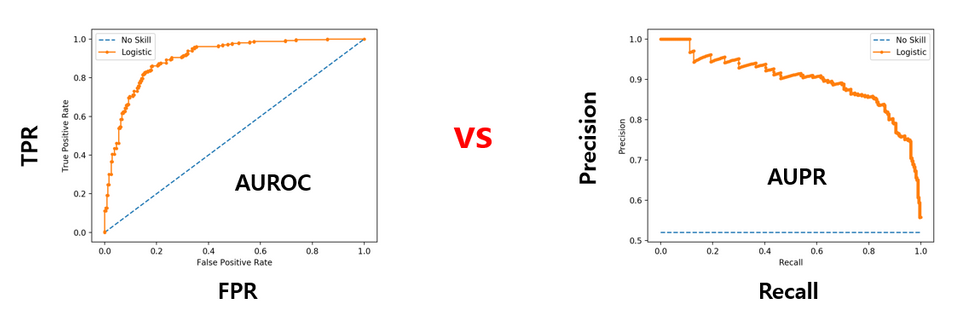
1) 2) 메트릭과는 달리 3) 메트릭인 FPRN은 하나의 threshold 에 대한 성능을 나타냅니다. threshold가 고정되면 detector의 성능 비교를 명확하게 할 수 있다는 장점이 있으며 FPRN은 낮을수록 성능이 좋습니다.
4.2 DATASET
각 데이터셋의 경우 워낙 유명한 데이터셋이기 때문에 데이터셋에 대한 추가적인 서술은 생략하겠습니다. 본 논문이 제안하는 데이터셋 구성을 정리하면 아래와 같습니다.
- D_{in}: SVHN, CIFAR-10 & 100, Tiny ImageNet, Places365, 20Newsgroups, TREC, SST
- D_{out-oe}: 80 Million Tiny Images(SVHN, CIFAR), ImageNet-22K(Tiny ImageNet, Places365), WikiText-2(나머지)
- D_{out-test}: SVHN, CIFAR-10&100, Tiny ImageNet, Places365, 20Newsgroups, TREC, SST
- 이 때 D_{out-oe}, D_{out-test}는 서로 겹치면 안되므로 겹치는 데이터는 모두 제거
4.3 MULTICLASS CLASSIFICATION
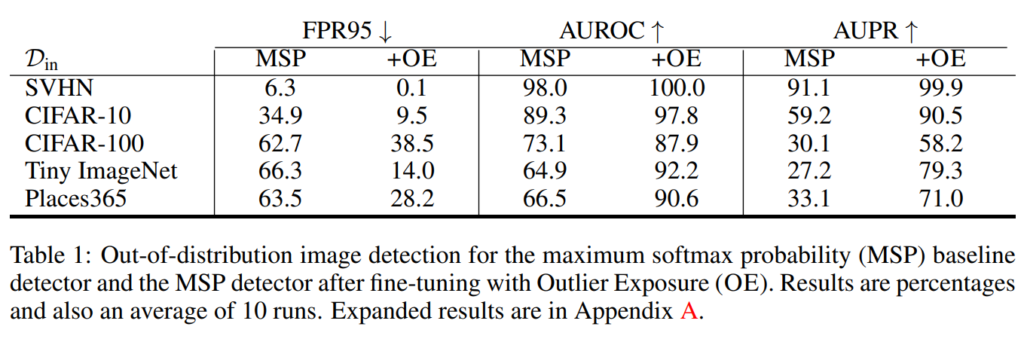
지금부터 본격적으로 기존 OOD 방법론에 OE를 적용함으로써 성능이 향상되었는지를 알아보도록 하겠습니다. 가장 먼저 Baseline 모델의 경우 MSP 값을 통해 OOD deteciton 을 진행하는데, D_{out-oe} 의 정답 label을 uniform 분포로 classifier를 재학습하였다고 합니다. 이렇게 classifier를 재학습할 경우, OOD 데이터에 대해서는 uniform 분포를 산출하기 때문에 MSP 값은 작아지고, 이를 통해 OOD detection의 성능을 높일 수 있었다고 합니다. 아래 실험은 Image 에 대한 실험 성능입니다. OE를 진행하였을 때, 성능이 크게 향상된 것을 확인할 수 있었습니다.
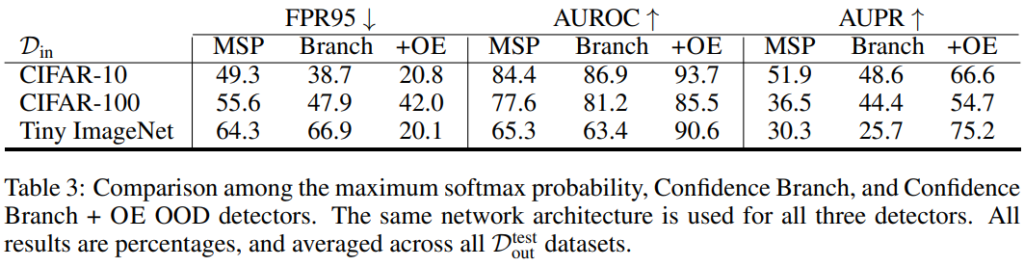
두번째 모델은 Confidence Branch 입니다. 아래는 Baseline 모델과 마찬가지로 image에 대한 실험 결과를 나타낸 테이블입니다. 실험 결과 MSP 와 Branch 간의 성능 차이보다 OE까지 적용했을 때 성능이 드라마틱하게 향상한 것을 확인할 수 있습니다.
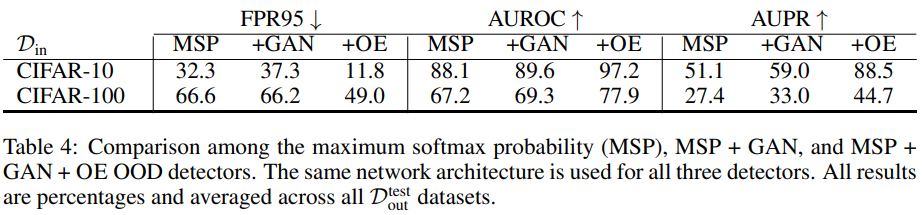
세번째 방법론은 GAN을 통해 OOD를 생성하여 활용한 모델입니다. 이 경우 MSP에 GAN 이미지를 추가하였기 때문에, 간단하게 D_{out-oe}를 추가하여 학습을 진행하였다고 합니다. 실험 결과 GAN 데이터만을 사용할 때보다 OE를 제공하였을 때 성능이 크게 향상됨을 확인할 수 있습니다.
DISCUSSION
본 논문에서는 OOD detection 성능을 높이기 위한 Dout-oe 데이터의 특징을 실험적으로 밝혔다는 contribution을 가집니다.
첫번째 특징은 바로 Dout-oe 데이터셋의 다양성입니다. CIFAR10을 in-distribution으로 한 실험에서 CIFAR 100의 10개 class 를 Dout-oe로 활용했을 때와 30개의 Class를 Dout-oe로 사용했을 때 그 성능 차이가 약 7%였습니다. 반면 50개와 30개를 사용한 경우에는 큰 차이가 없었고, 다양성이 확보된 경우 데이터셋의 개수가 큰 상관이 없다는 것을 입증했습니다.
두번째 특징으로 Dout-oe, Dout-test, Din 간의 유사성입니다. 실험 결과 Dout-oe와 Dout-test는 유사성이 떨어져도 전혀 상관이없었다고 합니다. SVHN을 OOD로 한 실험에서 SVHN과 비슷한 digit 이미지 데이터를 Dout-oe로 사용한 경우가 오히려 자연 이미지를 Dout-oe로 사용한 경우에 비해 성능이 안좋았다고 합니다. 반대로 Dout-oe와 Din의 유사성이 있는 경우 (유사성이 높으면 구분이 어렵기 때문에) 성능이 좋았다고 합니다.
다시 말해, Dout-oe는 충분한 다양성이 확보된 Din과 유사성이 높은 데이터셋을 사용하는 것이 좋다는 결론에 도달할 수 있습니다.
Conclusion
본 논문은 기존 OOD에 OE를 추가하여 성능을 올릴 수 있는 방법을 제안하였으며, 이 방법이 대규모의 이미지 뿐만 아니라 텍스트 데이터에도 적용됨을 보였습니다.
아쉽게도 제가 기존 방법론에 대한 이해가 부족한 상태로 이 논문을 이해하려니 시간이 많이 소요되기도 하고, 어떻게 동작하는지 이해가 가지 않은 부분도 있어 디테일한 부분을 많이 놓친 것 같습니다. 게다가 본 논문이 제안하는 방법을 기존 연구에 추가함으로써 자신들의 주장이 좋다라는 것을 보이기 때문에 기존 방법론의 이해가 필수적이어서 아쉬웠습니다. 그래도 부족하지만 OOD에 대해 맛볼 수 있었으며, 생각보다 간단한 아이디어 같아보여도 이를 입증하기 위한 여러 실험을 설계하는 것부터 여러 분야에 확장하여 적용하기까지 배울점이 많은 논문이었던 것 같습니다. 마지막으로 Discussion을 통해 제안한 idea가 성능이 더 좋다는 것으로 끝을 내는 것이 아닌 더 심도있는 연구와 주장을 하는 것 역시 인상깊었습니다.
궁금한 것이 있어 질문을 남깁니다.
conclusion에서 두번째 특징인 데이터셋 간의 유사도에서 ODD를 Dout-test로 이해했는데 제가 제대로 이해한 것이 맞나요??
네 맞습니다 ! 지적해주신 부분 수정해놓도록 하겠습니다 :>