9월달 논문 제작을 위해 저희 미래국방 팀은 Transformer를 이용한 Depth estimation을 사용하기로 했습니다. 현재 KITTI 데이터셋에서 SOTA를 달성한 것들이 Transformer이기도 하며 대 Transformer 시대에 편승하기 위한 얄팍한 생각을 갖고 있습니다. : )
또한 제가 참여했던 CVPR2021 DDAD challenge의 self-supervised 부분 1등을 차지한 방법론이 Transformer를 사용한 이 논문을 베이스로 하고 있기 때문에 더욱 Transformer를 사용하는 것에 주목하고 있습니다. 그런 의미에서 이번에 리뷰할 논문은 챌린지에서 사용된 Transformer관련 논문을 들고 와봤습니다.
1.Introduction
사실 이 논문은 Depth estimation 논문이 아닙니다. 이 논문은 논문 제목대로 Vision Transformer를 사용해 pixel level의 prediction을 하는 방식에 대해 제안하는 논문이며, 그에 대한 실험으로 Depth estimation과 Semantic Segmantation에서 성능을 증명하였습니다.
기존 pixel level의 prediction( dense prediction) 은 encoder와 decoder의 형태를 유지하고 있으며 encoder를 기존 classification에서 제안되고 있는 모델을 차용하며 이 encoder의 성능이 전체 성능을 좌지우지 합니다. 하지만 이 CNN을 사용한 encoder는 Receptive field가 제한적이라는 한계가 있습니다. 이러한 한계를 극복하고자 다양한 방법들이 제안되어 높은 성능향상을 이뤘지만 여전희 CNN을 사용함에 따라서 한계를 극복하지 못하고 있습니다.
이러한 상황에서 Transformer라는 CNN의 한계를 극복한 방법론이 Classfication에서부터 큰 돌풍을 일으키고 있으며, 이러한 상황에 발맞춰 이 논문에선는 Transformer를 dense prediction의 encoder로써 높은 성능 향상을 일으킬수 있는 방법론을 제안합니다. 대표적인 Vision Transformer인 ViT를 encoder 로 사용하였으며, Transformer에서 나온 feature들을 decode하는 방법을 제안합니다.
2.Method
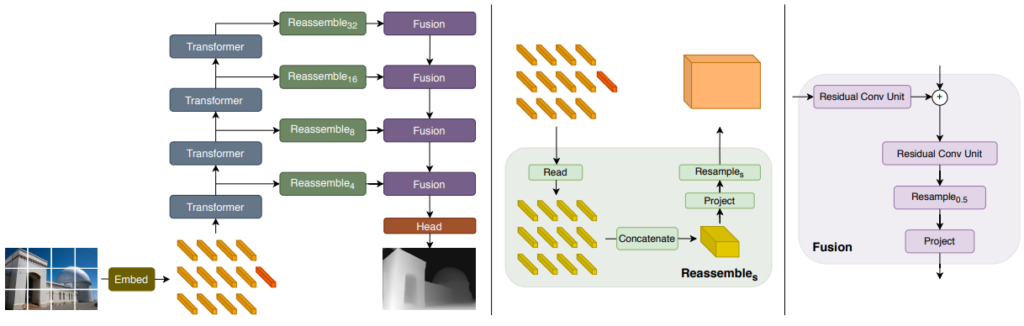
그림 1에 이 논문에서 제안하는 Dense prediction 방법이 표시되어있다. 그림을 보면 ViT가 Encoder로 CNN이 사용된 것을 알 수 있다. Encoder로 사용된 ViT의 경우 많은 연구원분들이 Review를 했으니 생략하고 decoder가 어떠한 방식으로 transformer feature와 CNN이 합쳐져 있는지 설명하도록 하겠다.
Convolutional decoder
이 논문에서는 Transformer를 통해서 생성된 다양한 image resolution의 feature를 처리하는 방식인 Reassemble과 합치는 방식인 Fusion 을 제안하며 먼저 Reassemble의 식은 다음과 같습니다.
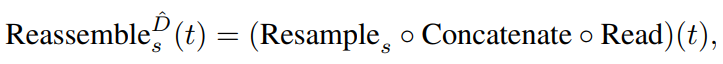
여기서 Read는 Dense prediction에 불필요한 readout feature를 제거하는 역할을 하며 이과정을 통해서 shape를 맞출 수 있게 됩니다. 그리고 Concatenate는 이름 그대로 분리되어 있는 feature들을 연결하는 역할을 하며 이과정들을 거치면 그림1 Center에서와 같이 하나로 합쳐지게 됩니다. 그후 1×1 convolution을 사용해 project한 후 3×3 convolution이나 transpose convolution을 이용해 형태를 맞추는 Resample 작업을 진행합니다..
이렇게 하나의 Resolution feature를 Convolution block으로 만드는 과정을 거치고 모든 Resolution의 결과를 합치는 방식인 Fusion을 통해 최종 Depth map을 생성합니다.
Fusion 방식은 Refine-Net에서 제안된 방식을 사용했으며 단순히 Refine-Net의 방식을 사용하면 image resolution의 반인 영상 크기가 나오므로 추가적인 convolution을 설계하여 input image와 동일한 크기의 depth map을 예측한다.
3.Result
이 논문에서 제안하는 방법론은 단일 이미지를 이용해서 동일한 크기의 새로운 image를 예측하는 generator에 대한 것입니다. 이 generator의 성능을 보여주기 위해서 논문에서는 Monocular depth estimation과 Sematic segmentation에 적용하여 성능을 보여줬습니다.
Monocular depth estimation
이 논문 이전에 논문의 저자는 Few shot learning을 활용한 Monocular Depth estimation 방법론인 MiDaS를 제안하였고 그와 동일한 파이프라인에 Generator만 교체하여 학습을 하였다고 합니다.
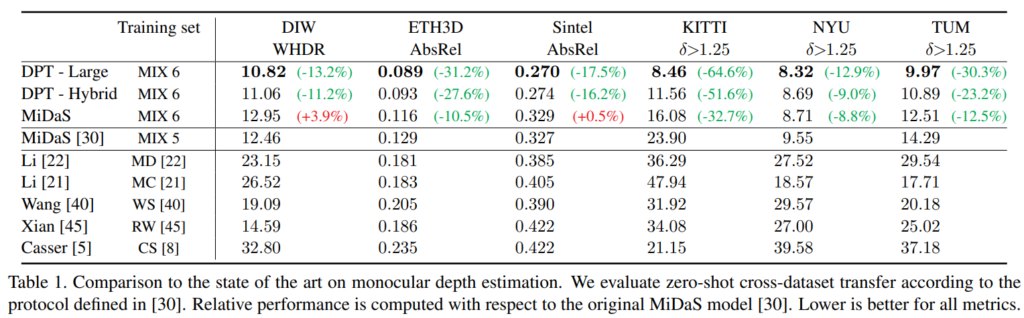
MiDaS는 큰 데이터 셋으로 pretrain 후 각 작은 데이터 셋으로 조금의 finetune 하는 과정을 거치며 이 논문에서 제안하는 DPT또한 동일하게 했다고 합니다. 그랬을때 다양한 데이터셋에서 다양한 방법론과의 평가가 위의 표에서 나타나있는데 보면 모든 데이터 셋에서 SOTA의 성능을 보여주고 있습니다.
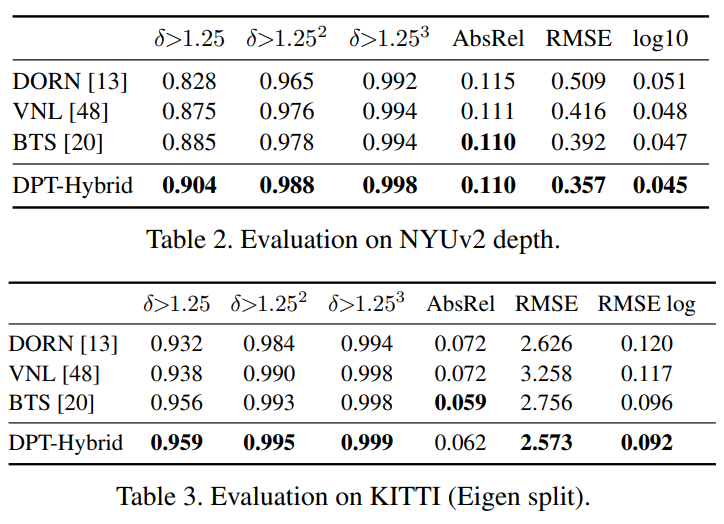
또한 KITTI와 NYU에서 각각 데이터셋의 SOTA 방법론과 다양한 평가 지표로 비교해도 모두 좋은 성
Segmentation
Segmentation에서는 ResNeSt을 Base로 하고 있습니다.
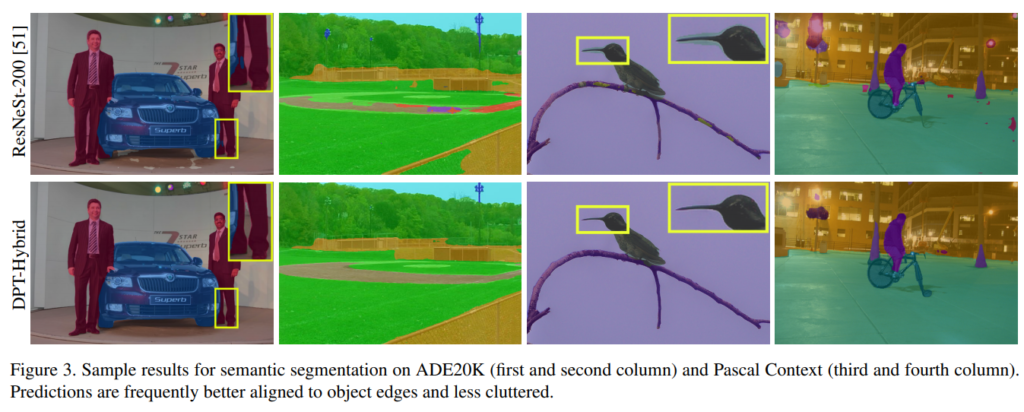
ADE에서 base와 정성적 성능을 비교해보면 확실히 디테일한 부분에서 차이가 나는 것을 볼 수 있습니다.
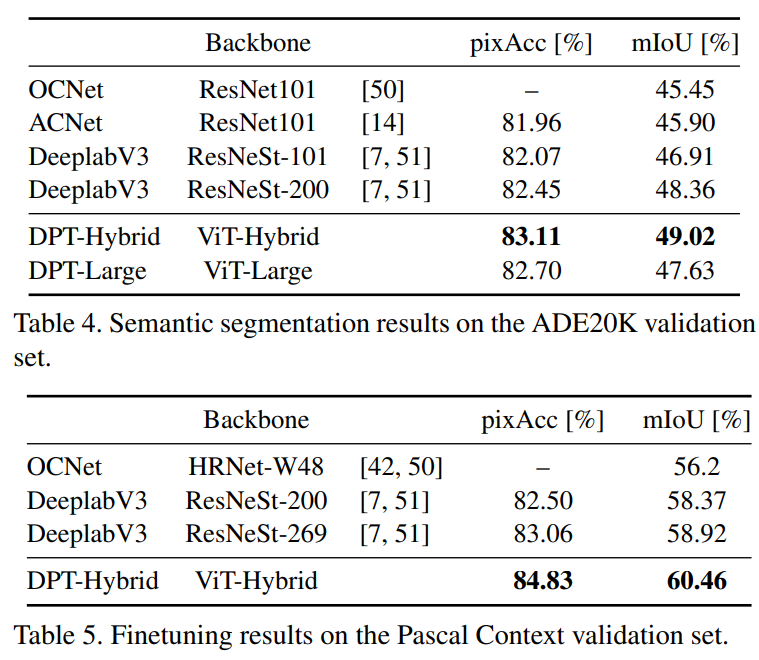
또한 정량적인 평가에서도 SOTA의 성능을 보임을 알 수 있습니다.
최근 Transformer 관련 논문들을 보면 대부분 ViT를 많이 사용하는 것을 보이는데, 제가 알기로 ViT는 데이터셋의 영향을 많이타는 단점이 있어서 ViT말고 DeiT와 같이 ViT의 그런 단점을 보완한 방법을 Encoder로 사용하면 더욱 general 한 성능을 보일 수 있을 것 같다는 생각을 해봅니다.
deit: https://arxiv.org/abs/2012.12877 페이스북 연구
한대찬연구원의 마지막 정리글때문인지 deit 가 궁금해지는 군요. 리뷰해주실 예정인가요?
….해보겠습니다