안녕하세요 이번주 X-review의 주제는 Anomaly Detection입니다. 대부분의 분들이 Anomaly Detection이란 용어에 많이 익숙하실거라고 생각합니다. Anomaly Detection은 다들 아시다시피 저희 연구실에서도 중기청, 한전 과제가 Anomaly Detection과 관련이 있고, 실제 산업현장에서도 많이 사용되고 있습니다.
Anomaly Detection이란 용어를 그대로 한글로 번역하면 “이상치 검출”인데 Anomaly Detection도 도메인, 방법론의 종류에 따라 세분화 됩니다. 예를들어 도메인의 경우 이미지, 비디오, 타임시리즈 등이 있으며, 방법론은 Out of distribution, Classification, Segmentation 등이 있습니다.
이번에 제가 리뷰할 논문은 그 중에서도 Anomaly인 영역을 heatmap 형식으로 예측하는 Anomaly Segmentation에 해당합니다. 이해를 돕고자 아래에 예시그림을 가지고 왔습니다.

왼쪽은 일반적인 도토리이고, 가운데는 Anomaly인 케이스 입니다. 그리고 Anomaly인 영역에 대한 GT mask가 오른쪽 사진 입니다. 이렇게 각각의 이미지마다 Anomalous한 곳의 영역을 예측하는 것이 Anomaly Segmentation의 핵심입니다.
그렇다면 “불법유턴차량 감시”은 어떠한 Anomaly Detection일까요? 위에서 언급한대로 도메인, 방법론적인 관점에서 생각해봅시다.
정답은 여러가지가 될 수 있겠지만, 일반적인 접근법으로 생각 해봤을때, 도메인은 비디오, 방법론은 out-of-distribution이 될 거 같습니다.
여기까지 Anomaly Detection의 종류들에 대해서 간략하게 알아보았습니다. 이 밖에도 알고가시면 좋은점은 Anomaly Detection은 대부분 view point가 크게 변하지 않거나, 카메라가 고정되어있는 등의 constraint를 깔고 갑니다. Class imbalance 문제로 task자체가 쉽지 않은편이라, 그러한 전제를 가지고 가는것 같습니다.
이 밖에도 좀 더 디테일하게 Anomaly Detection이 어떠한건지 알고싶으신분들은 해당블로그를 참고해보시는 것도 좋을거 같습니다. Anomaly detection이 아예 뭔지 모르시는분들에게만 추천드립니다.
우선 본격적인 논문리뷰에 앞서 이 논문이 나오기까지의 선행연구들에 대해서 차근차근 간략히 살펴보겠습니다.
아래자료는 고려대학교 산업경영공학구 최희정박사과정 학생의 발표PPT중 일부입니다.
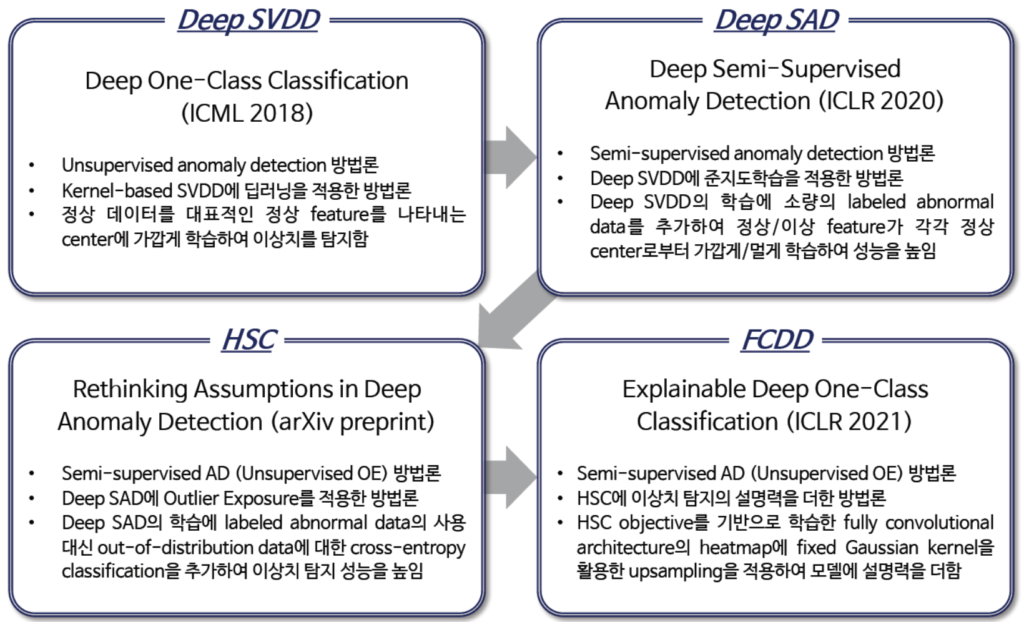
위의 그림은 해당 논문이 탄생하기전까지 배경이되는 방법론들을 잘 요약해줍니다. 그중에서 Deep SVDD부터 한 번 이해 해봅시다.
먼저 Deep SVDD는 쉽게 말해서 SVDD를 DNN화 한 방법론입니다. SVDD는 저희가 많이들어본 SVM 과 방법이 흡사한데 SVM에서는 하이퍼플레인을 이용하여 classification하는가하면, SVDD에서는 하이퍼스피어(Hyper Sphere)를 이용해서 Anomalous한 데이터와 normal 데이터를 분류합니다. 이 때, SVM과 마찬가지로 Kernel 트릭을 이용하여 non-linear한 경우에도 분류할 수 있게됩니다. 하이퍼스피어는 쉽게말하면 결정경계에 해당하는 원인데 해당 원의 최소반지름을 구하여 Anomaly와 Normal을 구분합니다.
Deep SVDD와는 다르게 Deep SAD에서는 학습데이터에 anomaly로 라벨링된 데이터를 추가합니다. 그리고 metric learning 개념처럼 normal인 데이터들은 센터로 더 가깝게, abnormal인 데이터들은 센터로부터 더 멀어지게 학습합니다. Deep SVDD에서는 라벨링되지 않은 데이터를 사용했지만, Deep SAD에서는 소량의 라벨링된 데이터를 추가적으로 사용하였으므로 semi-supervised의 방법론입니다.
HSC는 Deep SAD에서 발전한 논문인데 이번에 리뷰하게될 FCDD의 근간이되는 논문입니다. 여기서 핵심이되는것은 OE라고불리는 Outlier Exposure인데, 해당 기법을통해서 anomaly인 상황을 만들고 이를 cross-entropy classification 하여 Deep SAD를 개선하였습니다. 즉, 정상데이터와 정상데이터에 OE를 한 데이터로 학습을 한 후, 정상데이터와 비정상데이터가 포함되어있는 테스트셋에서 성능평가를 합니다. 이렇게 OE데이터를 활용하는것 만으로도 out of distribution 데이터에 대해서 더 강인해짐을 입증하였습니다.
이제 배경적인 소개도 마치었으니 아래서부터 논문리뷰를 본격적으로 해보겠습니다.
FCDD (리뷰할논문)
먼저 해당 논문은 2021 ICLR에 Accepted 논문으로 해당 논문에 대한 리뷰들이 모두 Open되어 있어 해당링크에서 확인해보실 수 있습니다. 개인적으로 Open Review 제도는 좋은 제도라고 생각을합니다.
해당 리뷰를 작성할때, 구글링하던중 고려대학교 산업경영공학부 세미나자료를 참고하여 공부하는데 도움이 많이되었습니다. 참고하실분들은 확인해보시라고 링크걸어둡니다. Anomaly Detection에 관한 내용들이 많이 있으니 한번 확인해보세요. 이와더불어 Anomaly Detection 관련논문들을 서베이하여 정리해둔 깃허브입니다. 읽을 논문을 찾으시는분들은 편리할거 같습니다.

방법론적인 설명전에 먼저 Figure1을 보시면 어떠한 연구인지 직관적으로 확인이 가능합니다. 해당 이미지는 MVTEC데이터셋에 대한 정성적인 결과인데요. 첫번째 행은 정상데이터, 두번째는 비정상데이터의 예시입니다. 그리고 마지막행은 마스크형태로 주어진 GT값이며, 세번째 행이 바로 해당논문에서 제안하는 아키텍처를 통해 나온 히트맵입니다. 해당 히트맵에서는 Anomaly인 영역을 잘 나타내주고있습니다.
특이한점은 Anomaly인 영역을 히트맵으로 나타내었다는점 입니다. 해당 과정을 위해 Fully convolutional network(FCN) 구조를 만들고 pooling 레이어를 거치며 다운샘플링된 feature map을 다시 upsampling시켜서 원래의 인풋이미지와 같은 해상도를 가지는 heat map을 아웃풋으로 가집니다. 기존 HSC에서 사용하는 FC layer와 다르게 FCN을 사용함으로써 공간정보를 보존 할 수 있었고 이는 성능향상 및 pixel level에서의 anomaly heat map을 만드는 결과를 가지고왔습니다.
사실 FCN이라는 개념은 2015년에 소개된 개념으로 각종 후속연구들이 해당논문을 인용하며 이미 유명한 방법론입니다. HSC에서 아키텍쳐적으로 크게달라진점은 FCN을 도입하여 Heat map을 upsampling 한거 뿐인데, 연구는 돌고 도는 느낌이 드네요.
이를 그림으로 살펴보겠습니다.
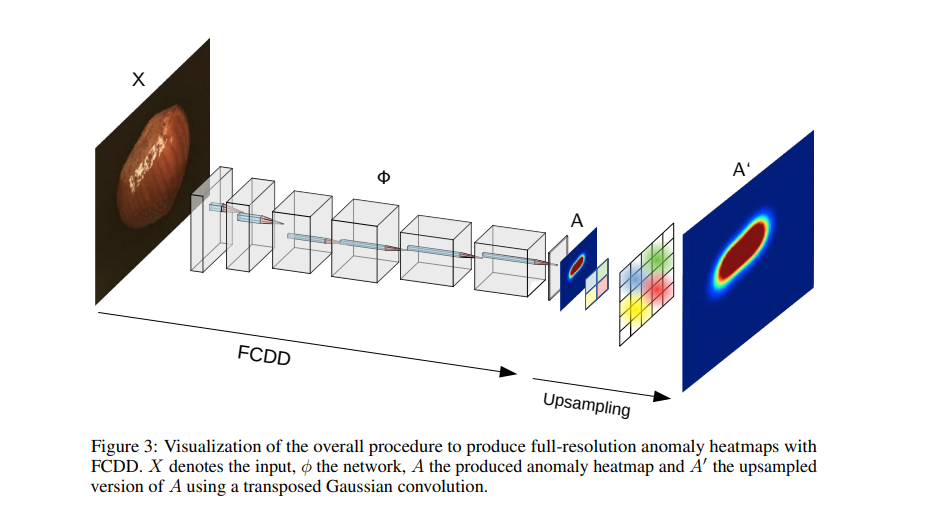
일반적인 cnn구조이며 pooling layer들을 거치며 다운샘플링되고, A의 heat map은 다시 upsampling되며 input 해상도로 복원이 됩니다. 해당연구 이전연구인 HSC에서는 A대신 FC layer을 사용하여 특정차원의 feature를 output으로 가집니다. 그러나 이렇게 FC layer를 태우는것은 spatial한 정보를 잃는 단점이 존재했습니다. 그래서 FCDD에서는 FCN의 개념을 도입하여 위와같이 heat map을 도출합니다.
그렇다면 어떻게 학습이될까요? FCDD의 Loss 함수는 기본적으로 HSC에서 정의된 Loss항을 기본으로합니다. 거기에 pseudo-Huber loss를 사용하는데 아래에 관련내용을 가지고 왔습니다.

논문에서 명시하는것처럼 A(X) 를 정의하고, element-wise matrix연산을하여 A를 구합니다. 그리고 pseudo-Huber loss를 사용하는데 이 A(X)를 사용합니다. 관련내용을 아래에 가지고왔습니다.

위의 Pseudo-Huber Loss에서 제곱항 안에들어가는 값이 논문에서는 network를 통해나온 값이며, 논문에서 정의한 A(X)가 S에 해당합니다.
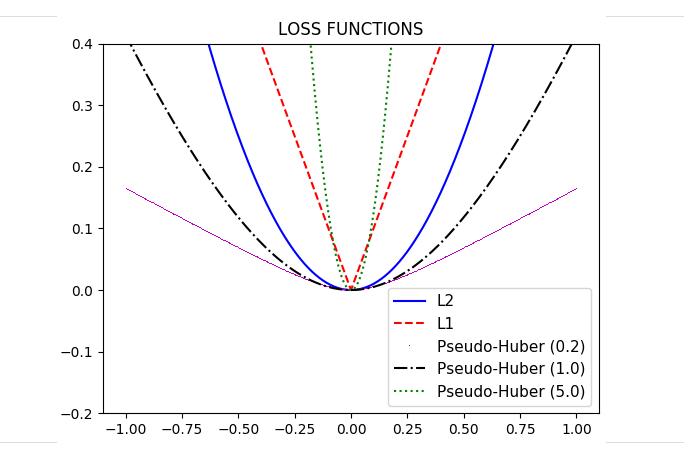
해당 예시에서는 Pseudo-Huber loss와 L1, L2 loss와의 차이를 보여주고있습니다. 감마값에따라 기울기가 달라집니다. 이러한 pseudo-huber loss는 outlier에 좀 더 강인성을 얻기위해 사용한다고합니다.
아무튼 이렇게 정의한 A(X)는 anomaly인경우에 maximize하고, normal인경우엔 minimize하며, 최종적인 anomaly score로 사용합니다. 학습에 사용된 objective를 좀 더 정확히 이해하려면 이전 논문들을 읽어보는게 필요할거같은데 앞으로 읽고 리뷰해볼 생각입니다.
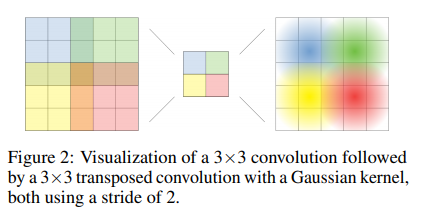
위의 그림은 spatial 정보가 어떻게 보존되는지에 대한 기초적인 설명입니다. 해당 그럼 upsampling은 어떠한 알고리즘으로 진행이 될까요?
이는 아래와 같은 알고리즘이 사용됩니다.

해당 알고리즘은 input이 output에 미치는 영향의 분포가 가우시안분포를 따른다는 사실을 기반으로 fixed gaussian kernel기반의 strided transposed convolution을 통해 anomaly heatmap을 upsampling합니다.
실험
실험은 Fashion-MNIST, CIFAR-10, ImageNet-1K, MV-tec에서 진행하였습니다. MV-tec을 제외하고는 One-vs-all classification문제로 접근하였고, MV-tec에서는 GT anomaly mask가 주어지므로 해당 GT를 기반으로 평가하였습니다.

비교는 기존에 존재하던 one-vs-all benchmark에서 좋은 성능을 보이는 모델들과 비교하였으며, OE가 있고, 없고에 따라 나누었습니다. 사실 드라마틱한 성능변화는 없는데 그 이유는 제가생각하기엔 해당논문에서 제안하는 FCDD의 핵심은 spatial 정보를 보존한다는건데 평가자체가 spatial정보가 반영된 GT anomaly mask를 기반으로 한게 아니기 때문이라 생각합니다. 그래서 GT anomaly mask가 주어지는 MV-tec에서 평가를 하였으며, 결과는 아래와 같습니다.
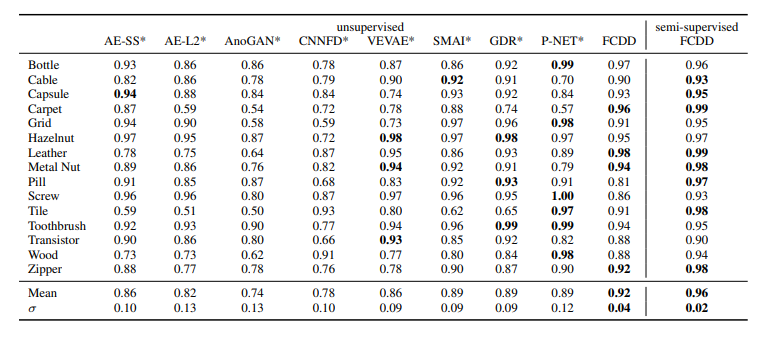
예상했던것처럼 spatial정보를 반영할 수 있기 때문에 mvtec에서는 가장 좋은 성능을 보였습니다. (현재소타는 아님)
unsupervised 기반의 FCDD는 0.92를 찍고, semi는 0.96을 찍었는데 여기서 semi-unsupervised는 위에서 설명했던 Deep SAD에서 사용한 소량의 labeled data를 넣는 것을 의미합니다. MVtec-AD 데이터셋말고 anomaly segmentation GT가 주어진 데이터셋이 없어서 비교대상군이 1개인게 좀 아쉽지만 확실히 spatial정보가 반영된게 실험적으로 입증되었습니다.
사실 아키텍쳐적으로도 보면 FCN을 가져다쓴것이고, 컨셉적인면에서도 이전논문들을 따라하였습니다. 결국에는 옛것을 알고 새것을 익히는 온고지신의 마음가짐으로 연구에 임해야겠다는 교훈을 주는 논문이었습니다.
논문이 개인적으로 생각할때, 컴팩트하게 잘설명되어있고, 부수적인 참고자료들은 전부 appendix로 빼서 가독성이 좋은거 같습니다. 그래서 한번 관심있으신분들은 읽어보시는걸 추천드립니다. 이전 연구들에 대한 이해가 짧아서 수식적으로 온전히 이해하진 못했기에 ref논문들을 간략하게 읽어보고 구글링하며 읽었는데 조만간 정독해보고 디테일한 부분을 챙겨가는게 목표입니다.
매우 흥미로운 논문 이네요.
모델의 다운샘플링 과정에서 공간적 정보의 손실로 w, h 크기에 예민할 것 같은데, 모델의 디테일한 구조가 궁금해지네요.
그리고 김형준 연구원이 가독성이 좋은 글이라고 칭찬하시니 나중에 논문 작성 시 참고해야겠습니다.
제 기억상 mvtec 기준으로 224*224로 resize한다음 다운샘플링합니다. 모델의 디테일한 구조는 논문링크 들어가시면 아주 상세하게 표로 정리되어있습니다. 일단 리뷰에서는 그림만 인용하였는데 한번 확인해보시면 좋을거같습니다. 그리고, 가독성이 좋다고 한 이유는 일단 군더더기 설명이 하나도 없고 핵심만 말하고 나머지 부수적인 결과는 모두 appendix로 뺐습니다. 그래서 실제의 핵심은 몇 페이지 안되는데 들어갈건 다 들어가 있다고 생각합니다.
이해를 돕기 위해 논문 리뷰에 앞서 기존 논문의 흐름을 정리해주신 점 인상깊습니다. 저도 제 리뷰 작성 시 참고해야겠습니다 ?♀️
감사합니다. 참고자료가 있어서 정리할 수 있었습니다.