이번 리뷰는 CVPR 2021 oral이기도 하며, 현재 KITTI에서 SOTA인 monocular 3D object detection 논문입니다. 해당 방법론은 각 픽셀의 categorical depth Distribution을 구해 깊이 추정을 하지 않고 신뢰성 및 정밀도를 향상 시키기 위해 Distribution를 feature로 사용합니다. 그 후 계산 효율성을 향상시키기 위해 bird eye view로 투영 후, 1 stage detection을 이용하여 검출하는 방법을 사용하였습니다.
Intro

3D 물체 검출은 자율주행에 있어 핵심 분야 중 하나입니다. 레이저의 반사되고 돌아오는 시간으로 깊이를 측정하는 LiDAR와 두 영상의 시점 차이에 대한 삼각 측량으로 깊이를 얻는 스테레오를 기반으로 3D object detection task의 발전이 이뤄졌습니다. 이와 동시에 저비용에 설치가 용이한 단안 카메라를 이용한 3D object detection 연구도 같이 이뤄졌습니다. 하지만 단안 카메라의 3D object detection은 깊이 추정에 필요한 단서의 부족으로 LiDAR와 스테레오에 비해 낮은 성능을 보였습니다. 이런 문제로 대부분의 3D object detection 방법론들은 3D object detection와 깊이 추정 모델을 분리하여 학습 및 추론을 진행합니다. 하지만 이런 문제는 깊이 추정 모델로부터 추론된 깊이 정보를 과신하는 문제가 있습니다. 잘못된 confidence를 가진 깊이 정보로 인해 올바르지 못한 최적화가 이뤄지며, 또한 분리 되어 있기에 잘못된 부분에 대해 깊이 추정 모델에게 전달할 수가 없는 한계가 존재합니다.
저자는 이런 문제를 해결하기 위해 3가지 컨트리뷰션을 제안합니다.
- Categorical Depth Distributions. 기존의 방법론들은 깊이 추정의 정확도를 향상 시키기 위해 Distributions을 보다 날카롭게(한 빈에 특출나도록) 만들도록 학습을 합니다. 반면에 저자는 기존 방법론과 다르게 덜 날카로운 분포를 생성합니다. 이는 불확실성에 대해 반응하여 잘못된 깊이 추정으로 발생하는 영향을 줄이고 성능 향상을 가져옵니다.
++ 해당 방법론의 핵심 기여이며, 기존 트렌드와 다른 방향을 제시하고 있습니다. 아마 이러한 이유로 CVPR oral이 된거라고 생각이 듭니다. - End-To-End Depth Reasoning. 깊이 추정과 3D object detection을 공동으로 최적화를 진행하는 방법을 제안합니다.
- BEV Scene Representation. Categorical Depth Distributions과 projective geometry을 이용하여 단일 영상을 이용한 고품질의 조감도 영상을 생성할 수 있는 방법을 제안합니다. 이를 통해 높은 계산 효율과 성능 개선을 가져왔다고 합니다. KITTI에서 SOTA를 달성하였고, Waymo Open Datasets에서 최초로 3D object detection 성능 결과를 리포팅합니다.
Method
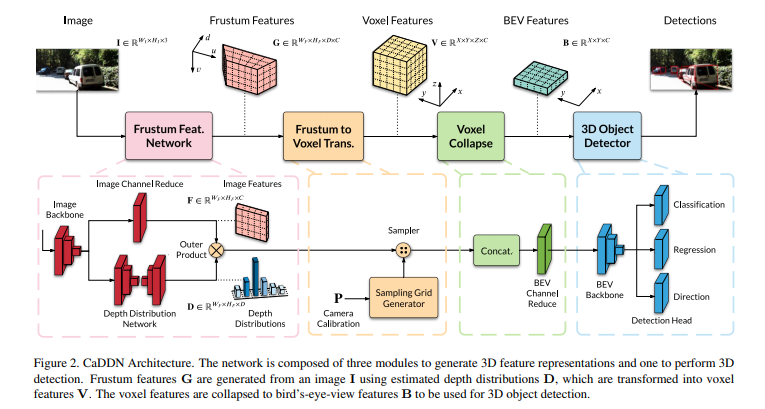
해당 방법론은 Fig 2와 같이, 단안 영상을 3D 공간에 투사하여 3D object detection에 적합한 조감도를 생성 후, 3D object detection을 예측하도록 구성됩니다.
3D Representation Learning
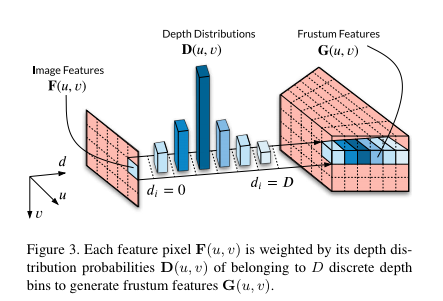
Frustum Feature Network. 해당 네트워크의 핵심은 영상 정보를 3차원으로 투영시키는 것에 있습니다. 영상 I를 모델에 태워 Frustum Feature G \in R^{W_F * H_F * D* C} 추론하는 것이 목적입니다. 여기서 W_F, H_F는 image feature의 높이와 너비이며, D는 depth bin, C는 feature의 channel에 해당합니다. 스테레오 기반의 깊이 추정 방법론에서 사용되는 volume feature 기반의 방법론과 동일한 형태를 가집니다.
먼저 영상은 ResNet101을 백본을 이용하여 image feature를 생성합니다. 그후 두 갈래로 나눠집니다.
하나는 pixel 별 categorical depth distribution D를 생성합니다. semantic segmentation network DeeLab V3 기반으로 설계된 모델을 수정하여 사용되어집니다. 또다른 하나는 최종적인 영상 특징을 생성하기 위해 channel reduction을 수행합니다. 메모리 효율을 위해 수행되어지며, 1×1 conv, BatchNorm,ReLU를 통해 C=256->64로 줄여 최종적으로 영상 측징 F 생성합니다. 그 후 , D와 F를 외적을 통해 frumstum fatrue G를 생성합니다.
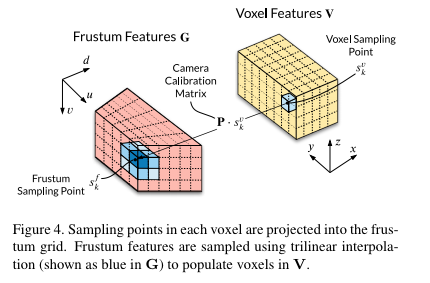
Frumstum to Voxel Transformation. 해당 단계는 G를 카메라 기하학을 이용하여 voxel화를 진행합니다. 즉 깊이 정보들을 x y z의 실제 환경으로 투영 시키는 단계에 해당합니다. G의 연속적인 깊이 값들은 voxel 단계에서 depth bin 값으로 변형되어져 추가되어집니다.
Voxel Collapse to BEV. 해당 단계에서는 이전 단계에서 완성된 voxel feature V V \in R^{X*Y*Z*C} 의 단일 높이 정보를 주어 조감도의 feature를 생성합니다. 먼저 Z * C로 채널을 concat한 후, 1×1 conv + BachNorm + ReLU를 통해 기존 C로 크기를 복원 시켜 줍니다. 즉, Bird’s-eye-view(BEV) feature B \in R^{X*Y*C} 만 남게 됩니다.
BEV 3D Object Detection
해당 세션에서는 BEV를 이용함으로써 보다 효율적인 계산 효율성을 가져오게 됩니다. 또한 기존의 LiDAR 방법론에서 사용되어진 방법론들을 적용가능 하기 떄문에 효율적인 연산이 가능합니다. 저자는 LiDAR기반의 BEV 3D object detction 방법론인 PointPilars를 베이스로 사용하여 3차원 물체를 검출을 예측합니다.
Training Losses
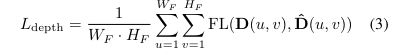
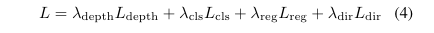
Loss는 기존의 PointPillars의 regression, classification, direction classification loss를 사용합니다. 여기에 추가로 BEV를 생성하는 Depth 추론을 위해 수식 3의 depth distribution loss를 제안합니다. 깊이 분산에서 단일 깊이를 정확하게 예측하기 위해 Focal loss를 사용하여 loss를 설계합니다. 추가로 전경과 배경 픽셀에 대한 가중치를 다르게 하여 전경에 대해 집중 하도록 합니다.
Experiment
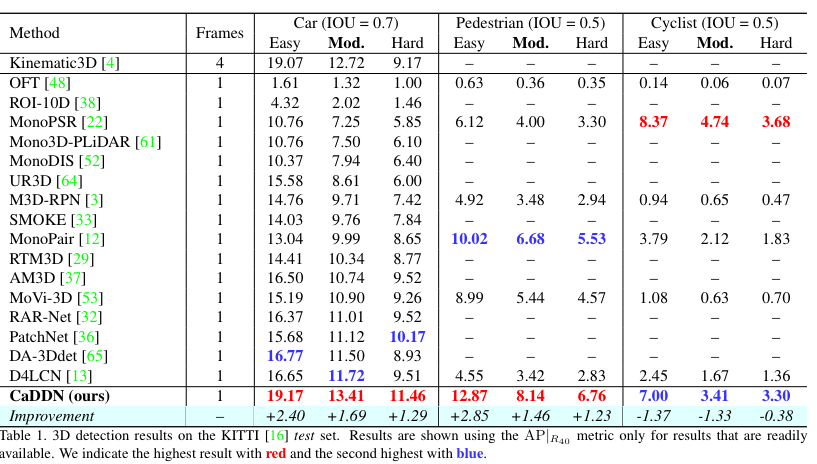
기존 제안된 단안 카메라 기반의 3차원 물체 검출 SOTA 방법론에 비해 1~2 % 성능 개선을 보이며 Pedestrian과 cyclist에서도 좋은 성능을 보여 상대적으로 큰 차량 외에도 비교적 작은 물체인 보행자와 자전거에서도 좋은 성능을 보여줌으로써 제안된 방법론의 효과를 보여줍니다.
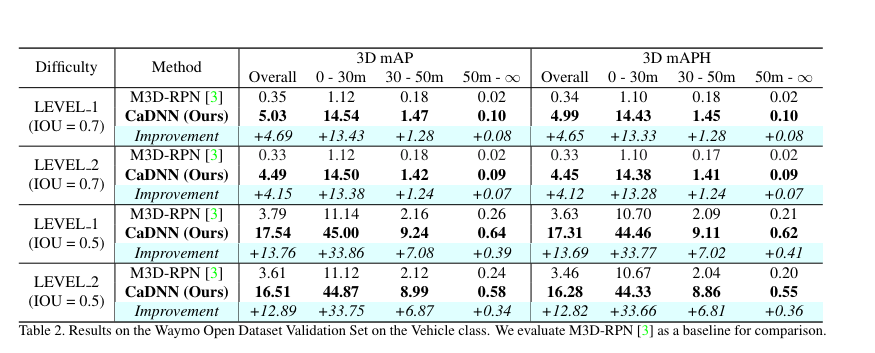
Waymo datasets에서도 처음으로 성능 평가를 진행했습니다. 여기서 LEVEL은 각 데이터 셋의 구분이라고 보시면 됩니다. 다른 방법론과 비교를 위해 M3D-RPN에서도 성능을 평가하여 성능 향상에 대해 비교를 했습니다. 높은 성능 향상을 보여주며 제안한 방법론의 효과를 검증합니다.
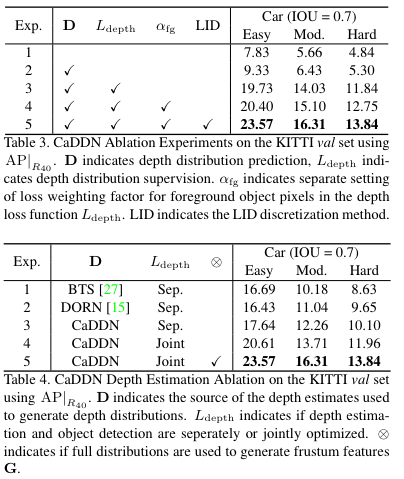
Fig 3에서 EXP 1은 depth의 개선 없이 날카로운 깊이 분산을 사용하며 분리된 모델로 성능을 평가한 결과 입니다. EXP 2는 Fig 2의 Frumstum feature를 생성 시, depth distribution D와 image feature F를 나눠 학습하여 결합한 결과에 따른 실험 결과에 해당합니다. EXP 3부터 깊이 추정과 3차원 물체 검출을 결합하여 평가한 결과입니다. EXP 3은 depth LOSS를 추가, EXP 4는 Focal loss에 전경과 배경에 대한 가중치를 다르게 주었을 때에 결과. EXP 4는 depth distribution 계산시, uniform한 방식이 아닌 선형성을 이용하여 덜 날카롭게 예측했을 때의 성능 향상에 따릅니다(LID는 추후 다시 추가하도록 하겠습니다).
Fig 4는 기존의 날카롭게 깊이의 분산을 생성하는 방법 기반의 3차원 물체 검출과 성능 비교 입니다.
_______________________________________________________________________
이번 리뷰 한 방법론은 Pseudo-Lidar와 비슷하게 이번엔 point cloud가 아니라 BEV를 이용해서 보여준 방법론이라고 생각합니다. 새롭게 한 획을 그은 방법론이기 때문에 꼭 기억하고 추후 논문 작성 시 , 해당 방법론을 추가하도록 해야할 것 같습니다.
실험은 알아서 보라는 건가요. 읽다가 만 기분이군요.
실험결과의 포인트를 잘 설명해 주셔야 합니다.
추가 작성해두었습니다. 피드백 감사합니다.
좋은 리뷰 감사합니다.
3D Object Detection 분야에 대해 처음 접해서 그러는데, 해당 분야에서는 Depth를 추정할 때 각 픽셀당 Depth를 Distribution 형식으로 추정하는 것이 일반적인가요? 기존의 mono depth estimation 분야에서는 이러한 분포 형식으로 구하지는 않는 듯 보여서요. Distribution 형식으로 표현하였을 때 장점이 무엇인지 혹시 알 수 있을까요?
그리고 소제목에 BEC 3D Object Detection이라고 적혀있는데, BEC가 뭔가요? Bird Eye View의 약자를 잘못 적으신건가요?
해당 분야에서는 Depth를 추정할 때 각 픽셀당 Depth를 Distribution 형식으로 추정하는 것이 일반적인가요?
– 일반적인 경우가 아닙니다. 제가 아는 지식 선에서는 최근에야 Depth와 3D object Detection을 1 stage로 학습되는 방법이 제안되었습니다. 해당 논문이 1 stage를 기여로 제시한 걸 보면 알 수 있죠. 대부분의 방법론들은 제안된 Depth estimation을 사용하여 2 stage로 추론하거나 2d detection에 height와 angle을 regression 추가하는 방식을 이용합니다. 그렇기에 일반적이라고 말씀드리기 어렵습니다.
기존의 mono depth estimation 분야에서는 이러한 분포 형식으로 구하지는 않는 듯 보여서요. Distribution 형식으로 표현하였을 때 장점이 무엇인지 혹시 알 수 있을까요?
– 말씀해주신 바와 같이 Distribution을 이용한 방법은 Mono가 아닌 stereo depth estimation에서 많이 사용되는 방법론입니다. stereo에서는 disparity bin에 대한 distribution을 구함으로써, bin별 불확실성을 계산할 수 있게 됩니다. 또한 각 픽셀간 매칭을 진행하기 떄문에 가려짐과 흩어짐에 강인한 모습을 가짐으로써 성능이 향상되는 효과가 있습니다. 아마 저자도 이런 장점을 mono depth distribution로 바꿔 적용하는 시도의 일환으로 해당 연구가 나온 걸로 보입니다. 제목도 categorical depth distribution 이구요
그리고 소제목에 BEC 3D Object Detection이라고 적혀있는데, BEC가 뭔가요? Bird Eye View의 약자를 잘못 적으신건가요?
– BEV로 수정 했습니다. 지적 감사합니다.