연구실 수주 받은 과제 중 스마트 팜(중기청)을 새롭게 맡게 되었습니다. 2차년도부터는 식물이 건강하게 성장 중인지 확인하는 태스크에 해당 합니다. 하지만 해당 태스크를 해결하기 위해서는 몇가지 해결해야하는 이슈가 있었습니다. 1. 적은 데이터. 식물의 질병을 의도적으로 만들기가 힘들며, 만들어도 식물의 다양한 형태와 질병의 형태(공간적, 정도 등)가 매번 다르다는 문제가 있습니다. 또한 식물의 성장 기간도 문제 중 하나입니다. 스마트 팜에서 주로 키우는 식물은 6개월이 지나야 성장이 끝나 제품화가 가능합니다. 한 식물의 질병 데이터를 얻기 위해서는 6개월의 시간이 소요되기 때문에 데이터 확보가 힘듭니다. 2. 식물마다 다른 성장 결과. 산업 환경의 이상상황 데이터 셋 MVTec의 정형된 형태를 가진 물체와 다르게 식물은 같은 클래스라도 성장 환경에 따라 형태가 매우 상이합니다. 그렇기 때문에 일반화된 정보를 획득하기가 어렵다는 문제가 있습니다. ++ 이번 과제에만 해당하는 이슈입니다. 3. 다른 조명, 다른 배경, 다른 식물, 매우 적은 데이터. 과제 해결하기 위해 제공 받은 데이터 셋에 정상 데이터와 비정상 데이터의 식물이 다른 종류, 다른 조명, 다른 배경을 가진 이슈가 있었습니다. 이런 문제로 단순하게 지도 학습 기반의 분류기로 문제를 풀기 어려운 상황이었습니다.
많은 고민을 하던 와중, Anomaly detection 방법론 중 reconstruction 기반의 방법론이 떠올랐습니다. 단, 해당 방법은 비정상 데이터로부터 정상 상황을 만들어 차영상으로 비정상을 찾아내는 방법론 입니다. 하지만 정상 데이터를 만들기에 데이터가 충분하지 못한 상황이기에, 컬러화 모델을 이용하여 비정상을 정상 데이터로 만드는 방법을 생각했습니다. 컬러화 모델을 적용하더라도 데이터가 부족한 상황이기 때문에, few-shot learning 위주로 찾았고 해당 방법론을 찾게 되었습니다.
해당 모델을 스마트팜에 적용한 결과 아래와 같습니다.
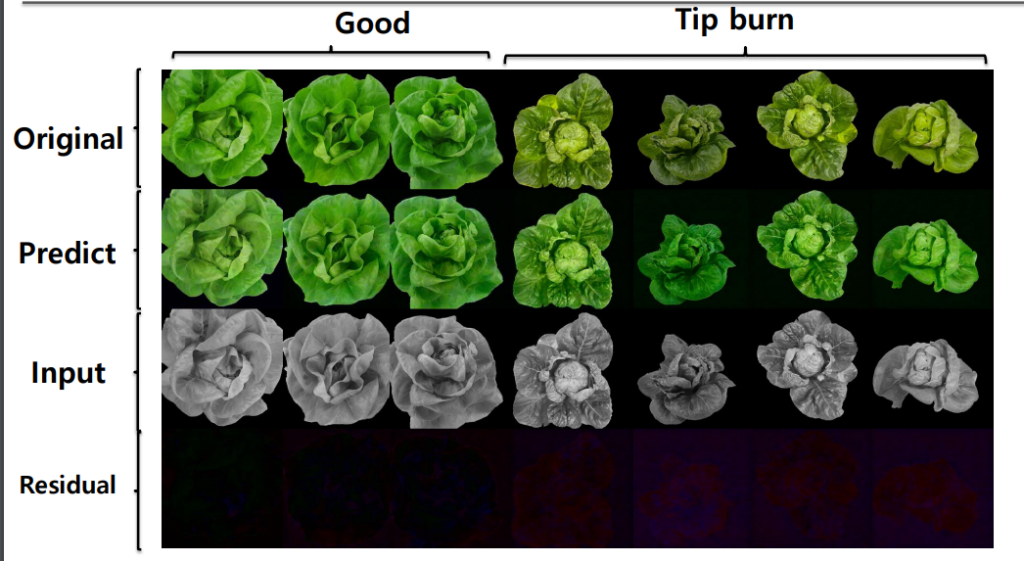
————————————————————————————————————————-
이번 리뷰 논문은 colorization task에 해당하며, 적은 데이터 셋에서도 특징을 추출하고 대표적인 특징들을 선별하여 기억하여 적은 데이터에서도 효과적인 결과를 보여준 방법론입니다. 또한 해당 논문은 고려대와 네이버웹툰가 함께, Fig 1와 같이 그림 혹은 3D animation의 colorization을 최종적인 목표로 둔 방법입니다.
Intro

기존 컬러라이제이션 방법론들에서 사용되어진 실제 사진들과 달리 그림과 만화들은 작가의 노력이 들어가기 때문에 많은 수의 데이터 확보가 매우 어렵습니다. 그렇기 떄문에 기존의 방법론을 적용하여 그림과 만화의 컬러를 복원하기 매우 어려웠습니다. 기존 방법론의 또 다른 문제로는 데이터에 존재하는 희귀 인스턴스를 무시하고 가장 빈번한 색상을 학습하여 데이터를 일반화 합니다.(fig 2)

저자는 앞에서 언급한 문제를 해결하기 위해 3가지 주된 컨트리뷰션을 제시합니다.
(1) 적은 데이터로 색칠하는 법을 배울 수 있는 few-shot, one-shot learning 기법을 제안합니다. 이는 memory network를 이용하여 학습 데이터로부터 유용한 색상 정보를 추출하고 저장하기 때문에 가능합니다. 입력이 모델에 주어질 때, 메모리 네트워크로부터 입력과 관련된 색상 정보를 추출 할 수 있습니다.
(2) 희귀한 영상의 컬러 정보를 추출이 가능합니다. 기존 방법들이 가장 빈번한 색상을 일반화하는 문제를 해결된 모습을 보여줍니다.
(3) 메모리 네트워크의 비지도 학습을 가능하게 해주는 새로운 손실 함수, threshold triplet loss를 제안합니다. 이를 통해 모델이 이미지를 성공적으로 컬러링하기 위해 라벨링된 데이터를 필요하지 않게 됩니다.
Method
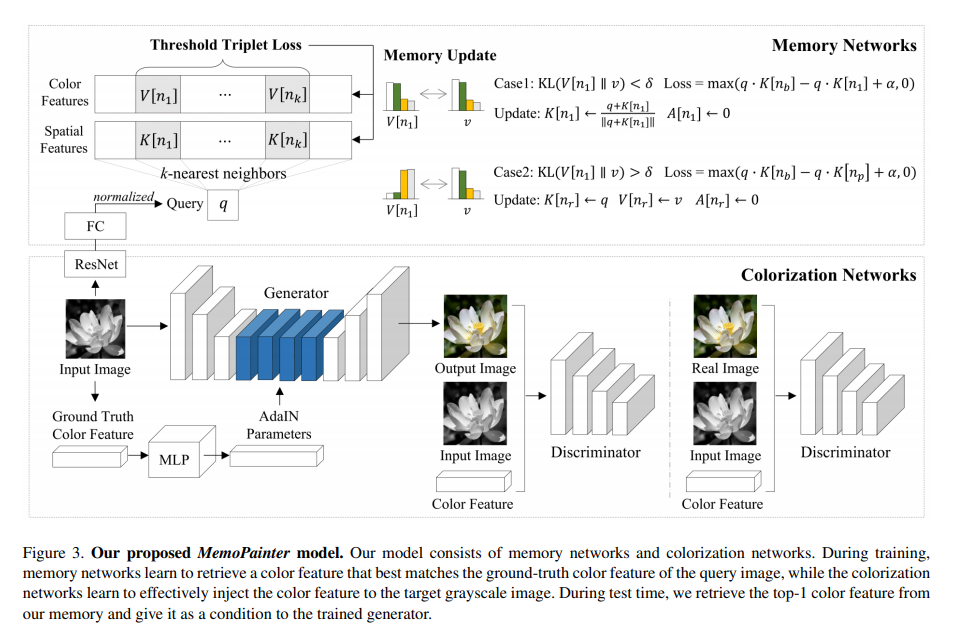
Memory Networks
메모리 네트워크는 장기간 중요한 정보를 저장하기 위해 NN으로부터 얻은 특징 정보를 외부 메모리 모듈에 적용하여 증강합니다. 보통 자연어 처리와 이미지 캡션닝, 이미지 생성, 비디오 요약 분야에서 lifelong, one-shot learning에서 많이 사용되는 방법입니다. 해당 방법론에서는 컬러화 네트워크에 최초로 적용했습니다.
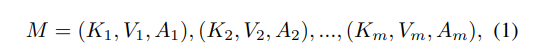
메모리 모듈에 적용되는 정보들은 수식 1과 같이 key memory K, value memory V, age A로 구성됩니다. Key memory는 입력 데이터의 공간적인 정보를 저장하며, value memory는 입력 데이터의 컬러 정보를 저장합니다. age는 저장된 데이터의 저장 후, 지난 시간을 의미하며 최신 정보를 업데이트 하기위해 사용되어집니다. 각 정보들은 학습 중 추출되는 정보를 토대로 저장됩니다.
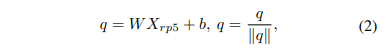
해당 방법론에서는 ImageNet으로 사전 학습된 ResNet18(~pool5)을 사용하여 추출된 정보를 사용합니다. pooling을 통해 물체가 어느 위치에 있든 공간적인 정보가 요약되어 표현되어지길 기대합니다. 그후 학습 가능한 linear layer와 표준화를 통해 공간적 정보를 가진 값 query q를 획득합니다.
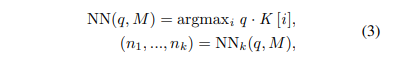
그 후, 수식 3과 같이 q와 key memory K와 cosine similarity가 적용된 kNN(~=NN())을 적용합니다. q와 K가 가장 유사한 특징을 선별 후, 매칭되는 value memory(color)를 획득하고 colorization network에 정보를 전달하게 됩니다.
Color Features
앞서 언급합 value memory의 컬러 정보는 두 가지 방법으로 추출되어집니다. 하나는 color distribution을 이용합니다. 입력된 RGB 영상을 CIE Lab color space로 변환하고 ab 값을 313개의 빈으로 정량화하여 획득합니다. 해당 정보를 통해 보다 다양한 컬러 정보를 그릴 수 있으며, 해당 방법론에서는 few-shot learning 기법에 적용하는 방법입니다. 또다른 방법은 RGB color value를 이용합니다. Color Thief를 이용하여 직접 대표되는 10개의 RGB 색상을 추출합니다. 적은 컬러 정보를 활용하기 때문에 쉽고 빠르게 모델 학습이 가능해집니다. 해당 color feature는 one-shot learning에 사용되어 집니다.
Color Thief : https://lokeshdhakar.com/projects/color-thief/#api
Threshold Triplet Loss for Unsupervised Training
기존의 triplet loss는 positive끼리는 가깝게 negative끼리는 멀어지도록 하여 metric learning에서 각광받는 손실 함수에 하나입니다. 하지만 positive와 negative의 명시적인 구분이 필요하며, 그 경계선이 모호한 경우가 많아 효율적인 학습이 어려운 경우가 많았습니다. 또한 이러한 구분을 하기위해 모든 데이터에 라벨링을 해주는 것은 거의 불가능에 가깝습니다. 저자는 이러한 문제를 임계값을 통해 비지도 학습으로 풀어가는 방법을 제안합니다.
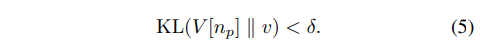
먼저 공간적인 특징이 유사한 두 영상이 있다고 가정할 떄, 컬러 분포간 거리가 임계값 내에 있으면 두 영상은 동일한 클래에서 있을 가능성이 높다고 가정합니다. 수식 5와 같이 해당 방법론에서는 두 컬러의 분포의 KL divergence가 임계값 이하인 경우, positive로 가정합니다. 임계값 이상인 경우 Negative로 가정합니다. one-shot learning에서 사용된 RGB color value도 CIE Lab로 변화하여 색상 거리를 계산하여 이용합니다.
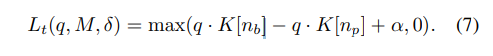
색상 정보를 토대로 positive와 negative를 정의하고 query와 key memory간 triplet loss를 계산하여 이용되어집니다.
Memory Update
해당 세션에서는 age를 이용하여 memory를 업데이트하는 방법에 대해 소개합니다.
(1) 만약 V[n]과 v의 거리가 임계값 이내에 있을 경우, K[n]과 q의 평균과 표준화를 한 값을 업데이트하고 age를 0으로 초기화 합니다.
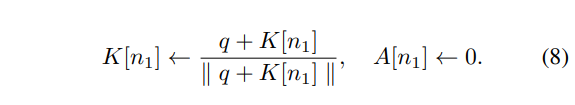
(2) 만약 V[n]과 v의 거리가 임계값을 초과한 경우, 이는 현재 메모리에 v와 일치하는 메모리가 없다는 것을 의미합니다. 따라서 (q, v)가 새롭게 기록되어 집니다. 가장 오래된 메모리 슬롯을 임의로 선택하고 해당 슬롯을 (q, v)로 교체합니다. 그리고 age를 0으로 초기화합니다.
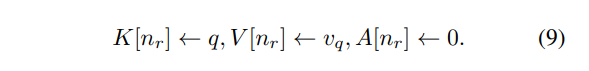
Colorization Networks
해당 방법론에서 사용된 컬러화 네트워크는 generator G와 discriminator D로 구성된 conditional generative adversarial networks를 이용합니다. generator G는 회색조 영상을 컬러 영상으로 복원하며 GT와 유사하도록 학습되어집니다. generator의 목적 함수는 아래와 같습니다.
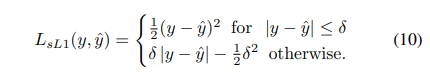
discriminator는 컬러 정보의 condition을 이용하여 회색조 영상으로부터 복원된 컬러 영상과 실제 컬러 영상을 구분하도록 학습됩니다. 전체적인 Loss 아래와 같습니다.
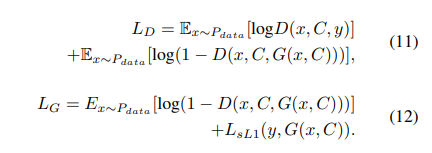
Colors as style
해당 방법론에서는 style transfer로 성공적인 성과를 거둔 AdaIN을 이용하여 style로써 color feature 값을 colorization network에 전달합니다.
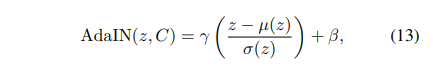
z는 이전 layer의 latent feature에 해당하며, r과 b는 각각 Color feature를 MLP에 태워 얻은 파라미터에 해당합니다. 수식 13에 대해 설명을 좀 더 드리면 특징 정보를 표준화하고 전달하고자 하는 color 값을 MLP를 통해 scale r과 shift b 만큼 분산을 이동시킴으로써, 적응적으로 정보를 전달하는 방법에 해당합니다. AdaIN을 이용함으로써 fig 6에서 보이는 것과 같이 다른 방법론에 비해 보다 나은 컬러화를 보여줍니다.

Experiments
Datasets
- Oxford102 Flower Dataset : 종류마다 40~258 장의 영상을 가진 120 종류의 꽃 데이터 셋
- Monster Dataset : 애니 컬러화를 목적으로 영화 몬스터 주식회사에서 수집한 1,315의 영상
- Yumi Dataset : 네이버 웹툰 유미의 세포에서 수집된 9,955의 영상
- Superheroes Dataset
- Pokemon Dataset

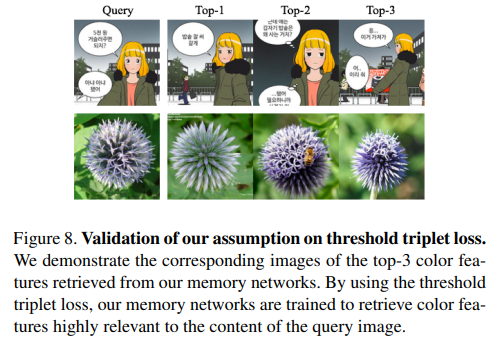
Fig 8을 통해 threshold triplet loss가 query와 연관된 정보를 잘 선별하는지를 보여준다.
본인이 왜 이 페이퍼를 선택했는지 함께 작성해줬으면 다른 연구원들에게 더욱 귀감이 될 듯
넵 추가하도록 하겠습니다.
추가 완료했습니다!
“기존 컬러라이제이션 방법론들에서 사용되어진 실제 사진들과 달리 그림과 만화들은 작가의 노력이 들어가기 때문에 많은 수의 데이터 확보가 매우 어렵습니다.” 저는 이게 오래 연재하거나 유명한 작가의 스타일의 경우 오히려 데이터 셋을 모으기 쉽다고 생각되는데 어떻게 생각하시나요..?
또한 기존 Colorization 같은 경우에는 현실 세계의 색깔을 예측하는 것이다 보니 보여주고 계시는 정성적 결과와 같이 GT와 유사한 결과가 나오는 것을 중요시 하는 것이 이해가 조금은 가는데, 말씀해주신대로 그림과 만화의 경우 창작의 영역이다보니 좀 더 비현실 적인 예측이 용인 될 수 도 있다 생각하는데 그것에 대해서는 김태주 연구원님은 어떻게 생각하는지 궁금합니다.
1. 한대찬 연구원님이 들어주신 예시를 제외하고는 데이터 수집이 어려운 상황이 맞다고 생각합니다. 한 캐릭터에 다양한 구도와 화풍이 담긴 경우는 통틀어서 본다면 매우 희박한 경우라고 생각합니다. 그리고 유명 작가의 작품에서도 주인공을 제외하고는 부족하지 않을까요?
또한 여기서 말하는 쉽고 어려움은 즉석으로 원하는 구도를 얻는 데에 있습니다. 예를 들자면 장미에 대한 데이터를 수집해야합니다. 실제 환경에서는 장미만 있다면 조명과 구도를 다르게 하여 촬영을 하면 그만입니다. 하지만 그림인 경우 작가 마다 화풍이 다르며, 다른 구도와 조명의 데이터를 획득하기 위해서는 작가가 하나하나 다시 그려야합니다. 이런 부분에서 실제 환경보다 수집이 힘들고 비용이 많이 들어가는 이유입니다.
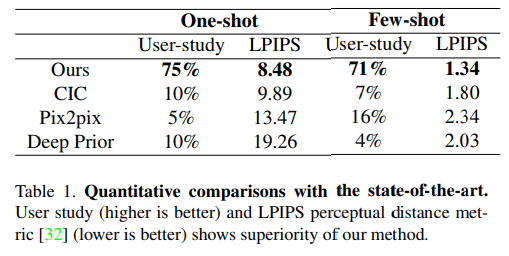
2. 실제 환경과 다르게 예술에 속하는 만화인 경우 예측의 허용 정도가 너그러울 거라고 생각이 듭니다. 하지만 사용되는 곳에 따라 너그러움 정도는 달라진다고 생각 합니다. 해당 논문의 소속 회사를 보면 작가들의 AI 어시스턴트를 제작하기 위한 목적이라고 생각이 듭니다. 그렇기 떄문에 말씀해주신 비현실적인 예측 보다는 유사한 결과가 나오는 것이 목적이였다고 생각이 듭니다. 근데 또 말씀해주신 부분에 동의하는 부분이 예술 분야이다보니 Table 1에 User-study를 성능 지표로 삼았고 너그러운 예측이 인정 받아 게재된 것이라고 생각합니다.
———————————————————————————————————————-
그리고 해당 방법론은 만화 컬러화를 위한 방법론보다는 메모리 네트워크를 이용해 ‘few-shot learning’이 가능한 GAN 방식의 컬러화 방법론이라고 기억해주면 좋을 것 같습니다.
답변 감사합니다