Before Review
이번 리뷰도 Temporal Action Localization 관련 논문으로 준비를 했고 , 저번 리뷰(S-CNN)의 후속 연구로 볼 수 있는 논문을 가져왔습니다.
간단하게 다시 복습을 하고 넘어가면
- Segment-CNN Review
- Temporal Action Localiztion task에 최초로 3D CNN을 도입하여 기존의 Handcrafted Feature 분류기의 성능을 넘어서는 방법을 제안했습니다.
- Proposal , Classification , Localization 3가지의 stage로 구성된 Multi-stage Network라 볼 수 있습니다.
- End to End 구조가 아니며 , Sliding Window 방식으로 고정된 크기의 Temporal Segment들을 만들어 내는 구조 입니다.
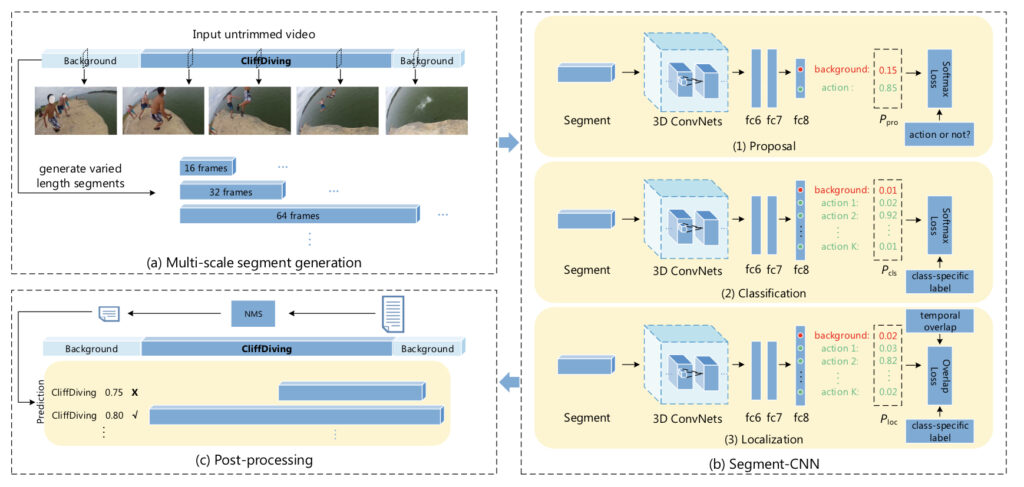
이번 논문에서는 이러한 S-CNN과는 달리 최초로 End to End 방식으로 설계된 Temporal Action Localization 모델을 살펴보도록 하겠습니다.
What is End to End?
사실 , End to End … 얘기는 많이 들어봤는 데 이번에 곰곰히 생각해보니 헷갈리는 부분이 있어서 이번에 간단히 정리를 해보려고 합니다. 기계학습 텀 프로젝트에서 풀었던 음성 데이터 분류 문제의 파이프라인을 떠올려보면 대충 Feature Extraction 부분에서 사람이 직접 설계한 수동적인 단계가 굉장히 많았습니다.
음성 데이터 받아와서 MFCC Feature를 추출하기 까지 단계가 꽤 많았는 데 이러한 파이프라인은 End to End Pipeline이라고 부르지 않습니다.

Deep Learning에서 End to End란 다음과 같이 Input data를 Neural Network에 던져주면 output까지 알아서 처리해주는 파이프라인을 의미합니다. 참으로 편리하기도 하지만 어떻게 보면 Neural Net이 알아서 처음부터 끝까지 처리하는 바람에 안에서 무슨 일이 일어나는 지 제대로 파악하기 힘든 경우가 많습니다. 또한 항상 End to End 방식이 성능이 제일 좋은 것은 아니라 , 해결하려고 하는 문제의 상황에 맞게 모델을 설계한다고 합니다.

Introduction
비디오 관련 리뷰에서 계속해서 등장하는 Untrimmed Video에 대해서 한번 더 얘기를 해보면 Untrimmed Video란 비디오 내부에 여러개의 action instance가 있거나 , action과 관련 없는 배경 영상들이 있는 비디오를 의미합니다. 이러한 Untrimmed Video에서 의미있는 spatio-temporal한 feature를 추출하는 것은 어려운 작업이며 , 우리는 Action 부분을 Detect 해서 무슨 action인지 , 이 action segment의 시작 시간과 종료 시간이 어떻게 되는 지 잘 예측하는 것이 목표 입니다.
기존의 방법론들은 우선 , sliding window 방식으로 여러 길이의 Temporal Segment(object detection에서 prior box , default box와 같은 의미)을 많이 많이 만들어 줍니다. 여기서 만들어진 Segment를 가지고 NMS , classification , localization을 진행해주는 데 , 아무래도 기존의 이런 방식은 어떻게 보면 기본적인 방법이라고 볼 수 있습니다. 즉 , Computation이 많이 소모 되며 , action의 경계들을 flexible하게 잡아주지 못한다고 합니다.
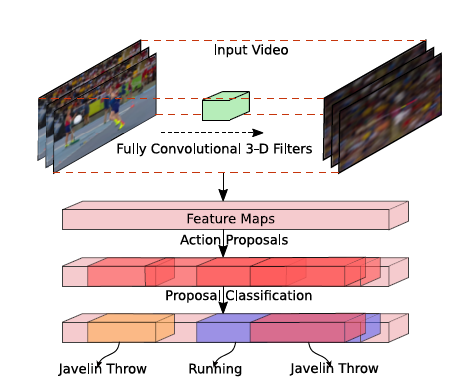
위의 사진이 본 논문에서 제안하는 R-C3D의 구조 입니다. 사실 구조는 간단하고 본 논문의 저자는 Object Detection 에서 최초로 End to End 를 시도한 Faster R-CNN 모델에서 영감 받아서 만들었다고 합니다. 실제로 많은 부분이 Faster – RCNN과 유사합니다. 본 Architecture의 특징으로는
- Temporal Action Localization 문제에서 최초로 End to End 방식으로 train 가능한 모델을 설계한 점
- 기존의 Segment Proposal 단계에서 사용하던 Sliding window 방식 말고 , Proposal generation stage를 도입해 사전에 정의된 크기로 생성 시키지 않고 무작위의 길이로 Segment들로 만들어내는 방식을 도입함
- Proposal generation 부분과 Classification 부분이 같은 feature map을 공유함으로 써 , Computation을 낮춘 점
이렇게 정리할 수 있을 것 같습니다. 3가지의 데이터셋을 가지고 실험을 진행했고(THUMOS 14 , ActivityNet , Charades) R-C3D가 모든 데이터셋에서 SOTA를 달성했다고 합니다. 또한 Proposal generation과 Classification이 같은 Featuremap을 공유해서 사용하는 구조라 Computation이 낮고 결국 그 당시 방법론들에 비해 5배 정도 빨랐다고 합니다.
저번에 리뷰했던 S-CNN과 달라보이는 점은 우선 , Segment Proposal을 만들어주는 과정 , Proposal과 Classification이 동일한 Feature map을 공유한다는 점인 것 같은데 저는 이 부분에 집중을 해서 방법론을 살펴보도록 하겠습니다.
Approach
Network
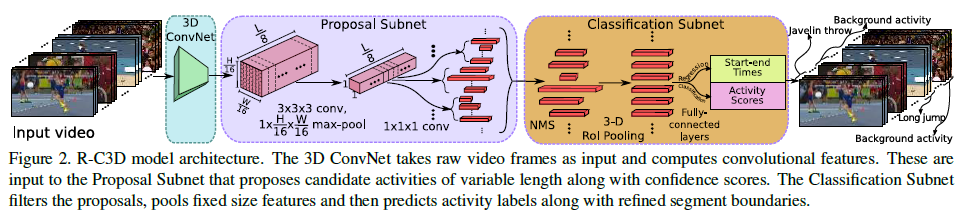
위의 그림을 보시면 Architecture는 3가지의 Subnet으로 구성되어 있습니다. 제가 위에서 Proposal Subnet과 Classification이 Feature map을 공유한다고 했는 데 , 이게 사실 저는 약간 좀 바로 이해가 되질 않아서 그 부분을 좀 더 집중해서 살펴보도록 하겠습니다.
- 3D ConvNet Feature Extractor
제가 저번 리뷰에서 비디오를 이해하기 위해서는 spatial-temporal한 feature를 잘 추출해야 한다고 얘기하면서 3D Convolution을 소개했습니다. R-C3D도 이러한 3D Convolution Filter들을 사용해서 Feature들을 추출해줍니다.
Input : R^{3\times L\times H\times W} , sequence of RGB video frames
output : C_{conv5b}\in R^{512\times \frac{L}{8} \times \frac{H}{16} \times \frac{W}{16} }
C_{conv5b} feature map이 activation을 통과한 값들을 최종 Feature로 사용하며 , 이 Feature가 proposal , classification subnet input으로 공유 되어집니다.
여기까지는 단순하게 Neural Network가 Feature를 만들어주는 과정이라고 보시면 될 것 같습니다. 다만 , 비디오 이므로 3D Convolution을 사용했다는 점 , 더 자세히 얘기하면 2014년도에 등장한 C3D를 backbone 으로 사용했다고 합니다.
- Temporal Proposal Subnet
이제는 Segment들을 Proposal하는 부분입니다. 주목해야 할 점은 기존의 Sliding Window와 다르게 Proposal 자체를 Neural Network 내부에서 진행한다는 점 입니다. 저는 이 Proposal Subnet이 좀 헷갈렸는 데 다시 그림을 자세히 보면서 파악해보도록 하겠습니다.
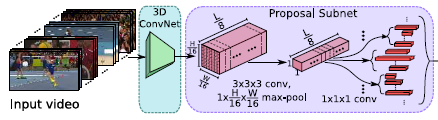
먼저 , Convlution과 max pooling 연산을 한번 진행해주게 됩니다. 3D Conv를 한번 더 진행함으로 써 temporal receptive field를 넓혀주고 , max pooling을 적용해줘서 1 by 1 사이즈로 만들어 주게 됩니다.
그 다음으로는 Anchor Segment라는 개념이 나옵니다. 흔히 우리가 Object Detection할 때 사용하는 Anchor Box라고 생각하시면 될 것 같습니다. Temporal한 방향으로 즉 , L/8개의 pixel 값에다가 K개의 anchor segment를 다른 scale로 셋팅해주게 됩니다 . 즉 , K*L/8 개의 Segment가 생기게 됩니다.
- Activity Classification Subnet
Activity Classification Subnet에서는 세가지 Task를 수행합니다.
- NMS를 통하여 Proposal Subnet에서 건너온 proposal segment들을 1차적으로 필터링 합니다.
- 위에서 선택된 proposal에 3D RoI pooling을 적용하여 , 고정된 크기의 feature들을 추출합니다.
- RoI pooling을 통하여 추출된 feature를 2개의 fc layer에 통과시켜 action recognition과 temporal regression(시작과 끝을 예측하는)을 진행합니다.
NMS를 해주는 이유는 대부분의 proposal 단계가 그러하듯 Overlap이 되는 proposal들과 , confidence score가 낮은 segment들을 1차적으로 필터링해주기 위함입니다.
그 다음으로는 3D RoI pooling을 진행해주는 데 , 이를 하는 이유는 Classification Subnet에 들어오는 Proposal들의 길이는 다양합니다. 어떤 Proposal Segment는 짧게 존재할 수 있고 , 어떤 Segment들은 길게 존재할 수 있습니다. 이렇게 크기가 다양한 output을 Fc layer로 보내줄 순 없으니 , 고정된 크기의 Feature Vector로 만들어줄 때 사용하는 것이 RoI pooling 입니다.
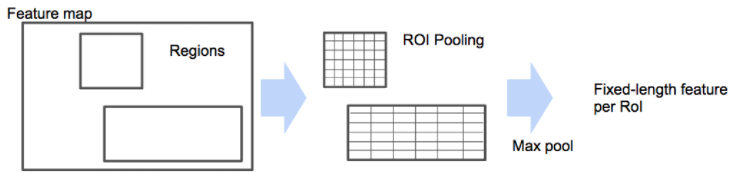
사진으로 봤을 때 두개의 Region들이 Proposal 됐고 , 크기가 다른 상태입니다. 이때 각각 Region에서 Grid의 크기를 다르게 잡아서 각각의 Grid 내에서는 max pooling을 진행해서 output을 산출합니다. Region마다 Grid를 다르게 잡아줌으로 써 우리가 원하는 고정된 크기의 output만 뱉어낼 수 있게 할 수 있습니다.
마지막으로 3D RoI pooling 연산을 거쳐서 나온 고정된 크기의 Feature vector들을 2개의 독립적인 Fully Connected Layer로 보내주게 됩니다. 어떻게 보면 특별한 점은 없는 것 같습니다. Fc layer 하나는 action classification을 담당하고 , 다른 하나는 Temporal region regression을 진행합니다.
Optimization
여기서 제안하는 Optimization 방법은 Object Detection에서 봐왔던 Loss와 동일합니다.
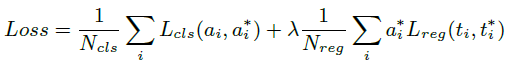
Softmax loss함수가 Classification 문제에 사용되고 , smooth L1 loss함수가 Regression 문제에 사용됩니다.
a_{i}는 각 class일 확률값을 담고 있으며 , t_{i} 은 Segment의 시작과 끝을 담아주고 있습니다.
위에서 R-C3D를 구성하는 Subnet들을 살펴봤는 데 , Proposal subnet과 Classification subnet 에 모두 Loss 함수가 적용된다고 합니다.
- Proposal Subnet
Proposal Subnet에서는 Action일 것 같은 부분에 Segment를 예측하는 구조 이므로 지금 생성한 Proposal이 Action인지 아닌지 Binary Classification을 수행하고 , 생성해준 Proposal과 GroundTruth간의 offset을 가지고 regression loss를 계산해줍니다.
- Activity Classification Subnet
Classification Subnet에서는 이제 Proposal Subnet에서 건너 받은 Proposal들을 NMS 처리해준 뒤 , pooling 연산을 거쳐서 Action Classification 즉 , Multiclass classification과 역시 마찬가지로 , 건너 받은 Proposal과 GroundTruth간의 offset을 가지고 Regression loss를 계산해줍니다.
Experiments
앞서 Introduction 부분에서 잠깐 언급했지만 , 세가지의 Dataset을 사용해 기존의 방법론들과 성능을 비교하였고 , 모든 데이터셋에서 우수한 성능과 빠른 속도를 얻었다고 리포팅 하고 있습니다.
- THUMOS’14
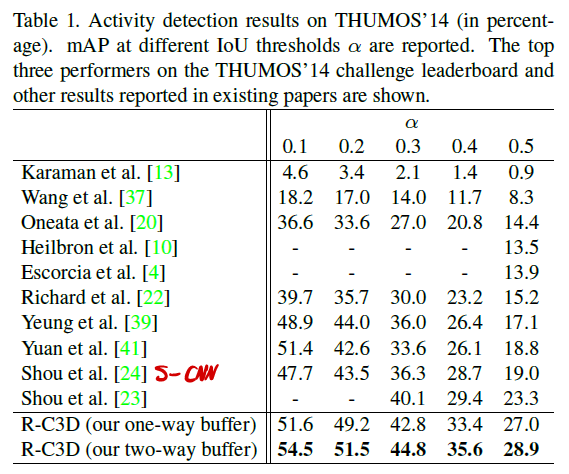
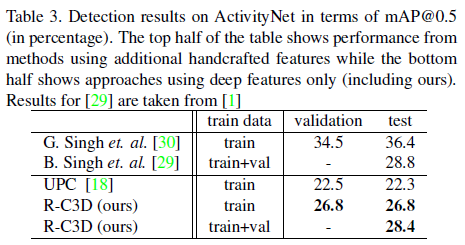
- ActivityNet
- Charades
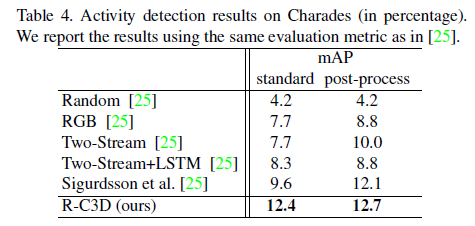
세가지 데이터셋에 대해서 비교 베이스라인들이 모두 동일하지는 않지만 , 모두 SOTA를 달성한 것을 확인할 수 있습니다.
- Detection Speed

모델이 End to End인 점 , Proposal Generation과 Classification Network가 Feature map을 공유한다는 점이 크게 작용해서 , 보시는 바와 같이 FPS가 좀 많이 높게 측정 되었습니다.
- Qualitative visualization

위의 사진은 R-C3D가 세가지 데이터셋에서 비디오를 샘플링 해서 뽑아낸 정성적 결과들인데 가장 밑에 있는 비디오 데이터에서 overlapping 된 action 영역에 대해서는 약간 아쉬운 예측을 보여주고 있습니다. 사실 이는 challenging 한 문제라고 저자가 얘기하는 부분이긴 합니다. 후속 연구에서는 이러한 문제가 개선되기를 기대해보도록 하겠습니다.
Conclusion
가장 최근에 리뷰했던 Segment-CNN 구조의 모델과 비슷하면서도 발전된 구조를 살펴볼 수 있었고 , End to End 방식으로 설계된 것이 가장 큰 특징인 것 같습니다. 뭔가 아직까지 리뷰한 Temporal Action Localization 논문들은 기존의 Object Detection 의 파이프라인을 벤치 마킹한 느낌을 받고 있는 데 , 후속 연구들을 계속 리뷰하면서 모델들이 어떻게 발전 되는 지 계속 알아보도록 하겠습니다.
해당 논문 리뷰에서 제가 찾아봤을때 ‘L’에 대해서 notation이 나타나지 않습니다. 아마도 Length이지 않을까 추축되는데, 그러면 입력되는 비디오의 길이는 모두 동일하다는 가정이 들어가는지 아니면 실제 데이터셋의 비디오 길이(시간)이 같은지 질문드립니다. 그리고 만약 비디오의 길이와 상관없이 모델을 사용할 수 있다면 Anchor Segment는 L에 따라 다르게 설정되어야 할텐데 혹 이러한 부분이 반영되는지 궁금합니다.
‘L’ 에 대한 notation은 질문하신 것 처럼 Length가 맞습니다.
실제 데이터셋의 길이(시간)은 모두 동일하지 않지만 , 입력되는 비디오 Tensor의 Length는 모두 동일한 값을 처리를 해주게 됩니다.
제가 아직 비디오에서 논문을 3편 정도 밖에 읽어보진 못했지만 , 제가 봤던 논문들은 비디오의 길이가 다르더라도 모두 고정된 frame 갯수로 비디오에서 Sampling 하는 방식을 사용했습니다. 비디오가 10초든 1분이든 L개의 frame만 사용한다고 보시면 될 것 같습니다.
L이 클 수록 즉 Sampling 을 많이할 수록 논문의 방식대로면 Segment(후보군)는 더 많이 생성될 것 입니다.
이때 , Segment의 Scale의 따라 Segment끼리의 길이는 차이가 나겠지만 이는 위에 설명한 3D-RoI pooling 연산으로 처리해서 동일한 크기의 Feature를 얻어주고 , 그 후 Classification과 Regression을 진행해주게 됩니다.