저는 cvpr challenge 이후 semi-supervised depth estimation과 self-supervised depth estimation 연구들을 계속 서베이 하고 있는 중입니다. semi supervised는 저번 리뷰에서도 말했듯이 sparse data를 취득하는 lidar와 dense depth map을 GT로 사용하지 않는 self-supervised 방식을 혼합하여 dense depth map을 추정하는 방법입니다. 이 방법은 저희가 계속 사용하는 Kaist dataset에서도 사용하여 성능 향상을 보여 줄 수 있을 것이라 생각하기 때문에 주목하고 있습니다.
이번에 리뷰할 논문은 저번에 리뷰했던 packnet을 semi-supervised 방식으로 학습시키는 논문으로, 학습 시 lidar와 비교하는 loss를 제안하여 높은 성능향상을 보였습니다.
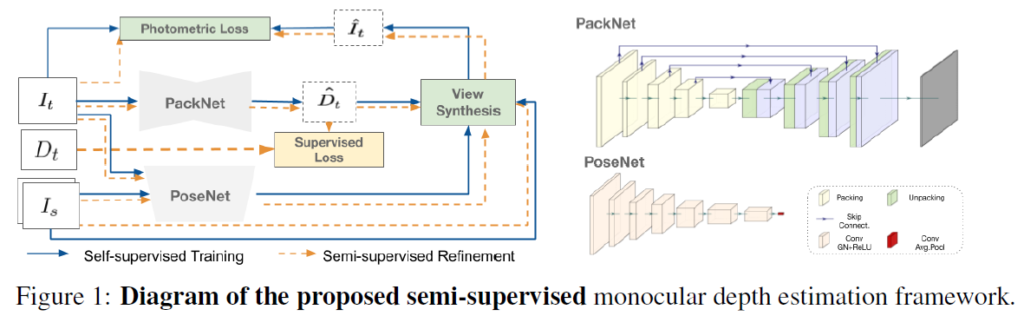
전체적인 아키텍쳐는 PackNet과 동일하지만 Supervised loss가 첨부된 아키텍쳐입니다. 타켓 영상과 소스영상 사이에 Pose정보를 예측하는 PoseNet과 Depth를 예측하는 Generator를 그대로 사용합니다.
Loss
위 아키텍쳐 네트워크를 학습하기 위한 Loss는 Semi-supervised 이니 Supervised 와 Self-supervised 방법론이 합쳐져있습니다.
Self-supervised loss
Self -supervised Loss는 Monodepth 2 에서 제안된 방법론과 동일합니다. (Monodepth2 에 대한건 앞으로 설명 없을 예정)
먼저 self-supervised 방법론을 간단히 설명하면
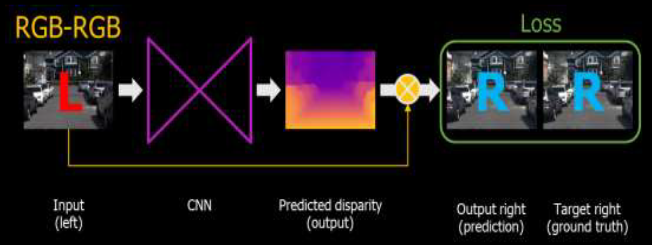
Self-supervised 는 아래와 위와 같이 모델을 이용해 left 와 right 사이에 disparity를 구하고, 구한 disparity와 input(left)를 이용해 Right 이미지를 생성합니다. 생성된 Right와 실제 Right의 차이를 구해서 모델을 학습합니다. 이때 두 영상의 차이를 구하는 metric은 다음과 같습니다.
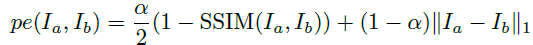
SSIM( Structural Similarity Index )을 이용해서 두 영상의 구조적인 유사도를 구해서 전제적인 Structure가 유사해지도록 하며, L1 distance를 이용해서, 전체적인 모습이 닮아지도록 하는 Appearance Matching Loss입니다. 하지만 이렇게 Synthesized image와 real image를 단순히 차이를 계산하게 될경우 Occlusion으로 인한 상황을 대처하지 못합니다. 이러한 문제를 극복하기 위해서 Monodepth2에서 다음과 같은 loss를 제안합니다.
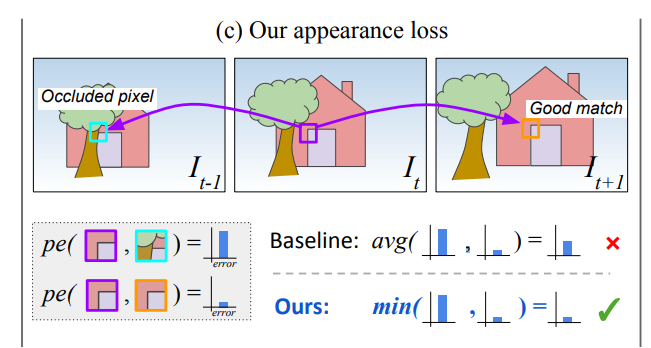
Synthesized image가 잘 생성된다는 가정하에 그림을 보면, It가 It-1로 변경되면 Occluded pixel 로 인해서 Appearance Matching Loss가 매우 커지게 되며 이는 학습을 방해합니다. 따라서 It를 It-1과 It+1로 모두 변경했을때 두 개중 Appearance Matching Loss가 적은 픽셀이 Occuluded pixel이 아닌 것 이고 그 픽셀의 Loss 만을 Loss로 반영합니다. 그 외에도 영상 속에서 동적인 물체는 SfM 의 가정을 깨는 상황이므로 동적인 물체를 학습에서 배제하는 Auto-Masking 방법을 제안했으며 이와 같은 모든 loss는 리뷰하는 이 논문에서 사용됐습니다.
그리고 생성된 Depth가 중간에 끊기지 않고 Smooth 하도록 만드는 Smoothness 까지 기존 연구들에서 사용된 Self-supervised loss를 적용했으며 최종 total self-supervised loss는 다음과 같다.
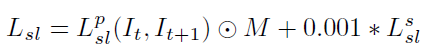
Supervised Loss
Self -supervised로 학습해서 예측하는 Dense depth map의 depth 값을 더욱 정확하게 예측하도록 Lidar와 비교한다. 기존에는 L1 diatance를 이용해서 LIDAR와 predicted depth를 비교했지만, 단순히 비교하는 것 보다 장면들간의 관계를 생각하는 Loss를 설계해서 제안하였다.
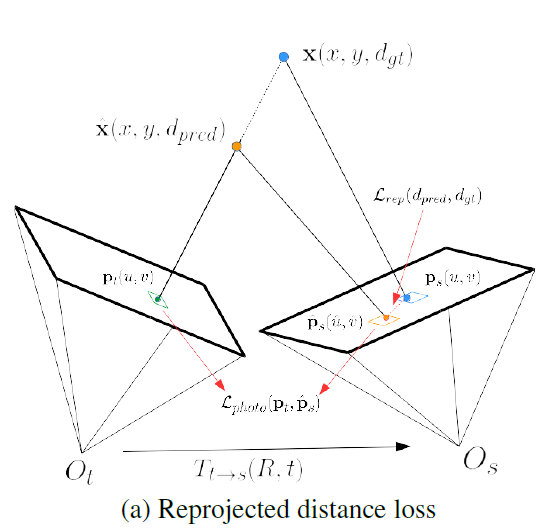
위 그림이 제안하는 loss를 표현 한것이다. Lrep가 제안한 로스이다. 기존의 Loss는 lidar 값이 존재하는 depth 값을 비교하지만 제안된 loss는 self-supervised 처럼 depth를 이용해 target image를 source 이미지로 변환하여 loss 를 계산한다. 예측된 depth 와 GT depth로 각각 t2s를 진행한다음 투영했을때의 pixel값의 위치 오차량을 Loss로 설계했다.
식은 다음과 같다.
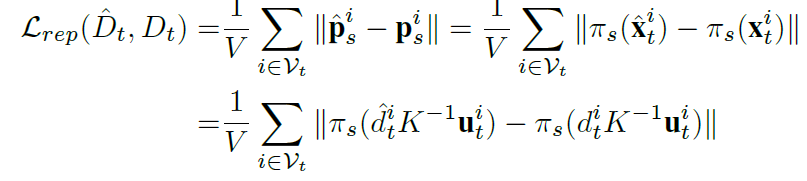
t2s를 할때 이용되는 pose값을 posenet에서 예측된 값을 사용하므로 posenet 에도 supervised의 영향을 줘 더욱 좋은 성능을 향상을 이룰 수 있다.
Result
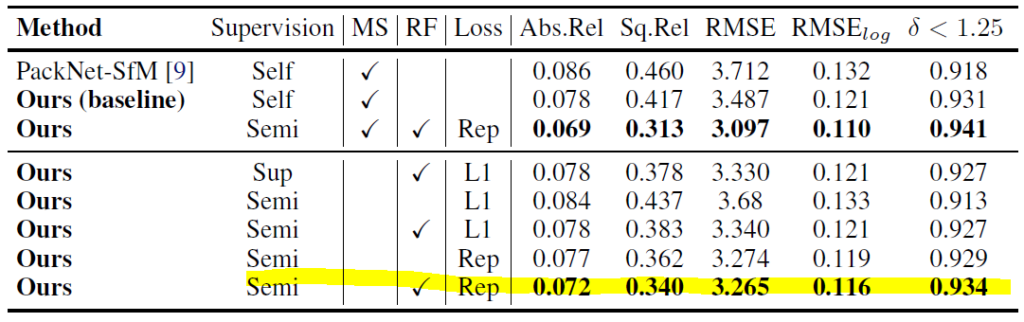
KITTI에서 Ablation 한 결과 입니다. 보면 L1 Distance 보다 제안된 Reprojection Loss를 사용했을 때 성능 향상이 있는 것을 볼 수 있습니다.

Ablation Study의 정성적인 결과를 보면 확실이 하늘 과 같은 부분에서의 성능향상이 뚜렷하게 있는 것을 볼 수 있습니다.
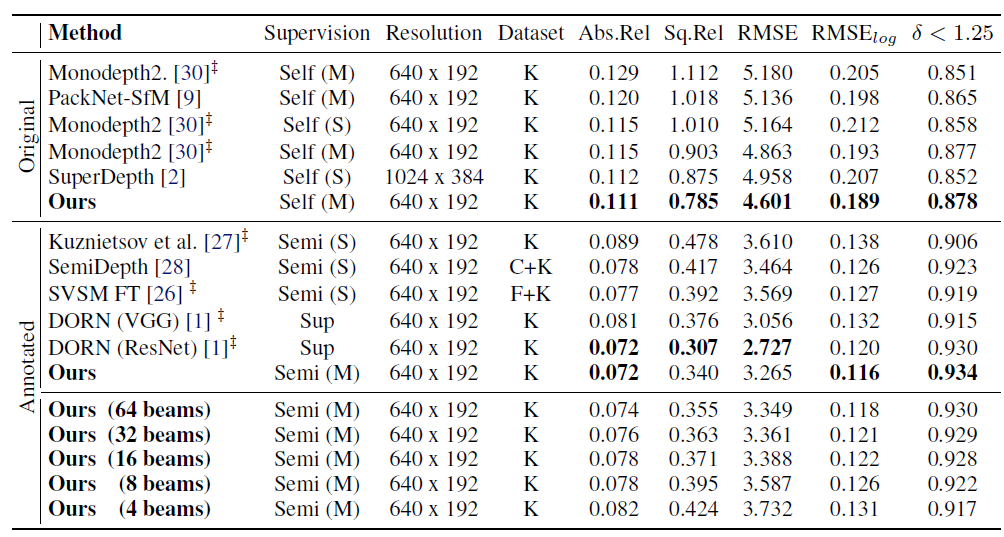
키티 데이터 셋에서 supervised 와 self supervised 방법론들과의 비교를 봤을때의 성능 차이를 볼 수 있습니다. 또한 마지막에 Supervised 에서 사용된 Lidar의 beam 갯수를 줄임에 따라서 성능차이를 보여주는데 beam의 갯수가 많이 줄어들어도 성능 드랍이 그렇게 크지 않은 것을알 수 있습니다.
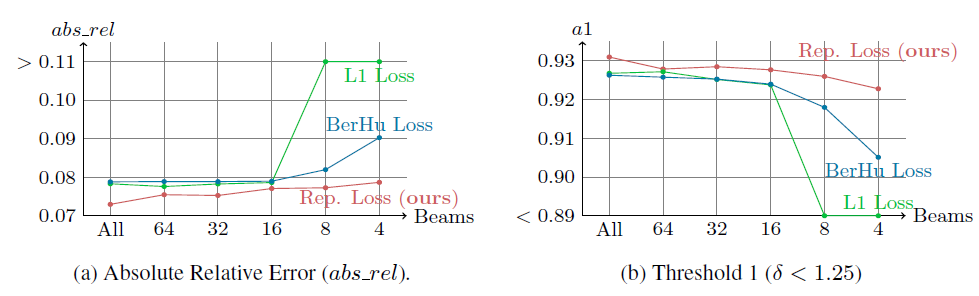
이것을 다른 Loss들과도 비료르 하여 나타냇습니다. 기존의 Loss들의 경우에는 Lidar가 Sparse해질 수 록 성능 드랍이 심해졌지만 제안된 Pep Loss를 그렇지 않은 것을 볼 수 있습니다.
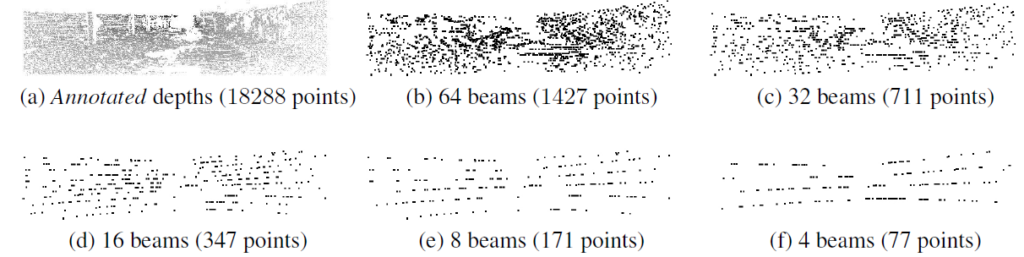
각 beam에 따른 lidar의 포인트 량을 보면 확실히 이러한 성능 드랍이 적은 것이 얼마나 좋은 것인지 느낄수 있습니다.