

현재 Temporal Localization 분야에서는 한 비디오에서 Action이 나타나는 시간대를 찾고 어떤 Action인지 판단하기 위한 데이터 셋이 주를 이루고 있습니다. 그러나 이전에는 주로 한 카메라로 촬영된 비디오 내에서 Action을 찾았기에 특정 Action 내의 variation이 낮은 단점이 있었고 이번 CVPR 2021에서 이를 해결하고자 MUSES(MUlti-Shot EventS) 데이터 셋 논문이 게재되었습니다. MUSES 데이터 셋은 비디오에서 Action 뿐만 아니라 Event가 나타나는 시간대를 찾는 것이 목적이며, 이전 한 카메라로 촬영된 Action 비디오 데이터 셋과 달리 한 Event를 여러 카메라와 전문적인 편집 기술로 가공한 영화나 드라마 비디오로 구성된 데이터 셋입니다.
1. MUSES Dataset
제안된 데이터 셋 설명에 앞서 간단한 용어 정리를 하겠습니다. 데이터 셋을 구성하고 있는 것은 비디오 이며, 비디오의 분류는 Category라고 합니다. 해당 데이터 셋에서 한 비디오는 여러 Category를 지닙니다. 그리고 비디오 내에서 특정 Category를 나타내는 부분을 instance라고 하며 이는 한 카메라로 촬영된 프레임 집합인 shot으로 나눠질 수 있습니다.
1.1 Data Collection
- Category Selection
총 25가지의 Category가 선정되었으며, 드라마 내에서의 빈도, 어려운 인식 난이도, 관객의 반응과 같은 요소를 고려하여 나눠졌습니다. 25가지의 Category는 아래와 같습니다.
conversation, quarrel, crying, fight, drinking, eating, telephone conversation, horse riding, hugging, stroll, driving, chasing, gunfight, modern meeting, speech, ancient meeting, kissing, war, playing an instrument, dance, (human) flying, cooking, singing, bike riding, and desk work
이 중 일상 생활에서의 Action인 drinking과 같은 몇가지 Category는 이전 제안된 데이터 셋에 포함된 것도 있으며, 일생 생활에서 자주 접하지 못하는 gunfight 나 war 와 같은 event도 포함되어 있습니다.
- Data Collection
본 데이터 셋의 비디오는 드라마를 호스팅하는 online 비디오 쉐어링 플랫폼에서 여러 장르 별로 태깅한 정보를 활용하여 수집되었습니다. 우선 수집된 데이터 셋의 다양성을 위해 각 장르 별로 시청 수가 적거나 해상도가 낮은 드라마를 제외하고 랜덤으로 선택하여 총 500개의 드라마를 수집하였으며, 여기에는 다양한 연도, 배우, 감독, 스토리로 구성된 1003개의 episode가 포함됩니다.
- Annotation
수집된 비디오 내에서 instance 별 start time, end time 그리고 Category로 annotation이 제공되었습니다. Annotaion은 시작하는 첫 주의 사전 학습을 받은 6명의 annotator 들이 진행하였으며 annotation의 성능을 보장하기 위해 매주 두 명의 annotator 끼리 짝지어 서로 다르게 annotation 한 부분에 대해 해결해 나갔다고 합니다. 이러한 과정은 3개월 동안 진행되었으며, annotation 가공 과정에서 생긴 두 가지의 주목할 만한 점을 기술하였습니다.
첫 번째로는 한 Event는 여러 개의 연속된 shot의 집합으로 구성되며 종종 Event에는 가려진 장면의 shot도 포함된다는 점입니다. 예를 들어, Event 중 dance를 가리키는 shot 두 개 사이의 관객들을 나타낸 shot이 존재한다면 그 shot도 dance라는 instance에 포함시켰다고 합니다.
두 번째로는 여러 instance가 시간 상 겹칠 수도 있다는 점입니다. 예를 들어, 차 내에서 발생하는 telephone conversation 것과 driving이 동시에 존재한다면 해당하는 시간 대에 여러 instance로 annotation 하도록 진행되었다고 합니다.
1.2 Statistics & Characteristics
앞선 과정으로 구축된 데이터 셋은 총 1003개의 episode 중, 702개의 training episode 301개의 testing episode로 나뉘었으며 한 episode 당 평균 42.8분의 길이를 갖습니다. 각 episode는 약 10분 정도의 비디오로 나뉘고 이 중 event 나 action이 나타나지 않은 비디오가 제거되었습니다. 그리하여 총 3697 개의 비디오를 생성하였고 이에 2587 개는 training 비디오, 1110 개는 testing 비디오로 나눠 총 31477 개의 instance와 716 시간의 비디오로 구성된 MUSES dataset이 구성되었습니다.

Table 1은 기존 다른 데이터 셋과의 비교 표 입니다. 데이터의 전체 크기 면에서는 ActivityNet-1.3 보다는 약간 큰 정도이나 HACS Segments 데이터 셋에 비하면 3분의 1정도의 크기를 지니고 있습니다. 그리고 MUSES 비디오의 평균적인 길이는 300초부터 1151초까지 다양하고 평균 698초의 비디오로 구성되어 있으며, 이는 THUMOS14에 비교했을 때 약 3배 더 긴 평균 비디오 길이 입니다. 그리고 Table 1에서 눈여겨보아야할 점은 마지막 두 column입니다. THUMOS14의 경우 비디오 당 속해있는 Category가 1.2개로 단일 Category는 아니나 적은 편이며, ActivityNet-1.3과 HACS Segments는 단일 Category의 비디오로 구성되어 있습니다. 그러나 제안된 MUSES 데이터 셋은 평균적으로 한 비디오 당 3.3개의 Category를 포함하고 있으며, 특정 Category를 나타내는 하나의 instance 내의 여러 shot이 포함되어 있는 것도 기존 데이터 셋과 다른 점 입니다.
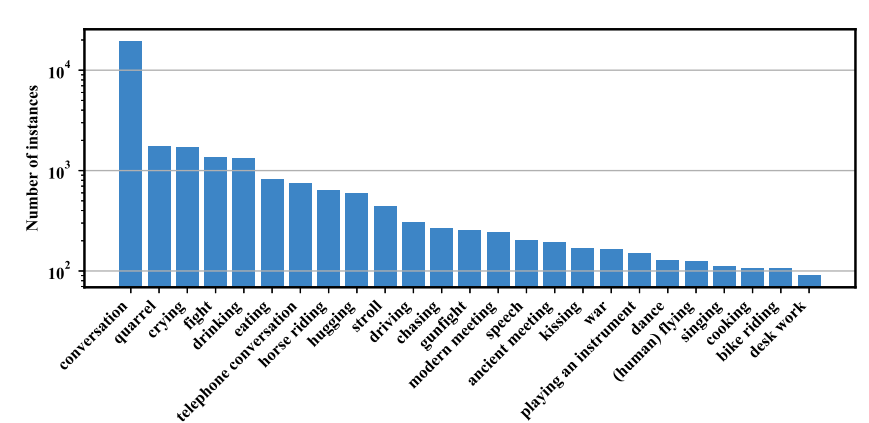

Fig 2는 모든 비디오에서 Category 별 instance의 수를 의미합니다. 최소 90개의 instance가 존재하며 평균적으로 1260개의 instance가 존재합니다. Fig 3-(a)는 비디오가 포함하고 있는 Category 수의 비율 입니다. 다른 데이터 셋은 앞서 Table 1에서 설명했던 것처럼 주로 한 비디오 당 하나의 Category가 존재하는 반면, MUSES 데이터 셋은 평균 3개 그리고 최대 7개가 존재하는 비디오로 구성되어 있습니다. Fig 3-(b)는 마찬가지로 비디오가 포함하고 있는 instance 수의 비율을 의미하며, Fig 3-(c)는 instance의 길이를 나타냅니다. 대부분의 instance는 20~40초 사이로 존재한다고 합니다. 또한 다른 instance와 tIoU>0.5인 instance는 15.8 % 존재한다고 합니다. 그리고 Fig 4-(b)는 instance 별로 포함하고 있는 shot의 수 입니다. 평균적으로 한 instance 당 19개의 shot을 포함하고 있으며, 한 비디오 당 176개의 shot을 포함하고 있다고 합니다.
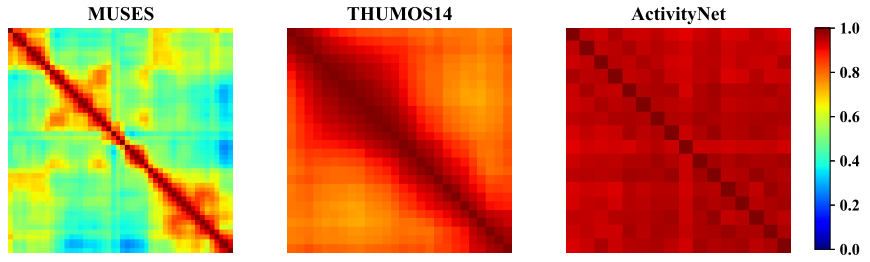

앞서 설명한 특징처럼 한 instance 내의 여러 shot이 포함되어 intra-instance variation이 MUSES 데이터 셋의 가장 큰 특징이며 저자는 이를 feature space에서 증명하였습니다. 먼저 Fig 4 는 각 데이터 셋 별로 한 instance의 shot 간의 pair를 만들어 I3D feature를 활용한 Self-similarity 입니다. 나타난 Self-similarity의 표준편차는 MUSES의 경우 0.16이었으며 THUMOS14와 ActivityNet-1.3은 각각 0.01과 0.09 였습니다. 이를 통해 MUSES 데이터 셋에서 한 instance 내부의 존재하는 shot variation은 다른 데이터 셋에 비해 크다는 것을 증명하였습니다. 다음은 한 instance 내의 각 shot들이 어떻게 기여하는지 확인하고자 Fig 5에서와 같이 CAM으로 visualization 하였습니다. Fig 5에서 한 instance 내의 각 shot들이 나타내는 CAM은 서로 많이 다른 경향성을 보이며 이를 통해 저자는 MUSES 데이터 셋의 intra-instance variation을 증명하였습니다.
1.3 Evaluation Metrics
MUSES 데이터 셋에서 다루고 있는 multi-shot temporal event localization 분야를 평가하기위해 우선 기존 temporal localization의 평가 지표인 mAP를 사용하였습니다. tIoU의 경우 THUMOS14 데이터 셋과 같이 0.1 간격으로 0.3부터 0.7까지 설정하였으며 다섯 가지의 경우를 평균 난 average mAP도 사용하였습니다.
그리고 한 instance에서 존재하는 수많은 shot의 처리 방식 평가를 위해 instance 내의 shot의 수에 따른 mAP를 각각 구하였다고 합니다. 이는 shot을 10개 미만으로 보유하고 있을 경우 mAP_{small}, 10개부터 20개까지 보유하고 있을 경우 mAP_{medium}, 20개를 넘게 보유하고 있을 경우 mAP_{large} 로 나뉘며 각 그룹의 비율은 각각 39.8%, 27.5%, 32.7%로 구성되어 있습니다.
1.4 Baseline Approach
- Pipeline
MUSES 데이터 셋의 평가를 위해 Fast R-CNN의 패러다임을 모티브로 삼아 다음과 같은 순서로 설계되었습니다. 1) I3D를 활용한 feature extraction, 2) intra-instance variation을 완화하기 위한 temporal aggregation 모듈, 3) ROI pooling을 통해 표현된 feature의 Category와 proposal의 정확도를 판단하는 두 개의 classifier와 boundary를 조정하는 regressor로 구성된 proposal evalutation 모듈
- Temporal Aggregation
한 instance 내 shot들의 feature coherence를 향상시키고자 해당 모듈이 추가되었으며, I3D network로 T x C 크기의 feature X를 추출하여 입력으로 사용합니다. (T는 시간 축으로의 길이, C는 차원) X를 우선 시간 축으로 W 길이인 H 개의 unit으로 reshape해 H x W x C 크기의 X’을 생성하며 W가 속하는 축으로는 연속된 shot, H가 속하는 축으로는 인접하지않고 stride가 W인 shot을 의미하게 만듭니다. 이후 H와 W가 속한 축으로 2D Convolution을 적용해 Y’을 추출하고 연속된 shot 내의 정보를 보는 short-term, 서로 다른 shot 간의 정보를 보는 long-term 연산 모두가 가능하도록 만듭니다. 이러한 방식으로 Convolution kernel의 크기를 키우지 않고 W 만을 조정하여 receptive field를 늘렸습니다. 이후 Y’을 다시 reshape하여 입력 크기인 T x C 크기의 Y를 생성하였습니다. 이와 유사하게 dilated 1D convolution 혹은 deformable 1D convolution이 존재하나 실험하였을 때는 낮은 성능을 보였다고 합니다. 마지막으로 앞서 설명한 temporal aggregation 모듈을 총 K 개 생성하되 다른 크기의 convolution kernel로 구성하였으며 각 모듈의 output을 합하는 방식으로 fusion 하여 서로 다른 duration의 event 에 강인하도록 설계하였습니다.
2. Experiments
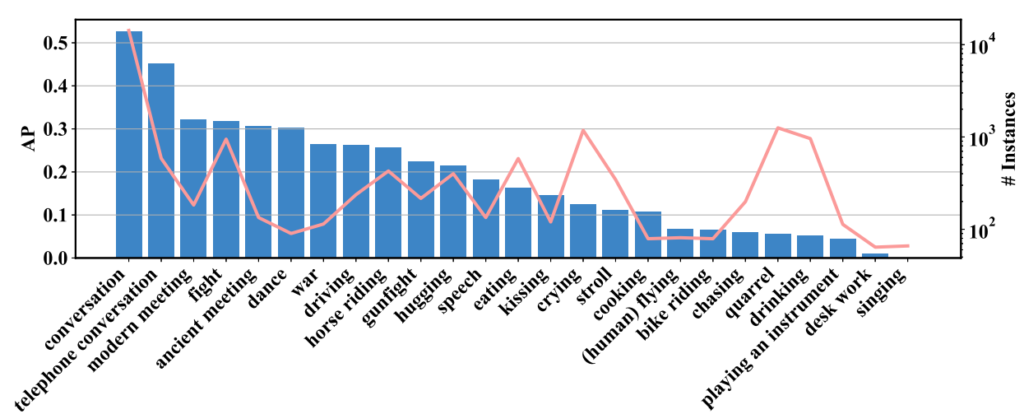
Fig 6는 각 instance 별 AP를 나타냅니다. 가장 좋은 성능을 보인 instance는 수가 많은 것에 기인한 것으로 보이는 conversation 이며 object와 scene에 연관된 telephone converation, modern meeting이나 motion feature가 두드러지게 나타나는 fight, dance도 좋은 성능을 보였습니다. 반면에 singing, desk work, playing an instrument, drinking, quarrel 같은 경우 데이터가 적거나 instance 간의 다양성이 매우 커 낮은 성능을 보였습니다.
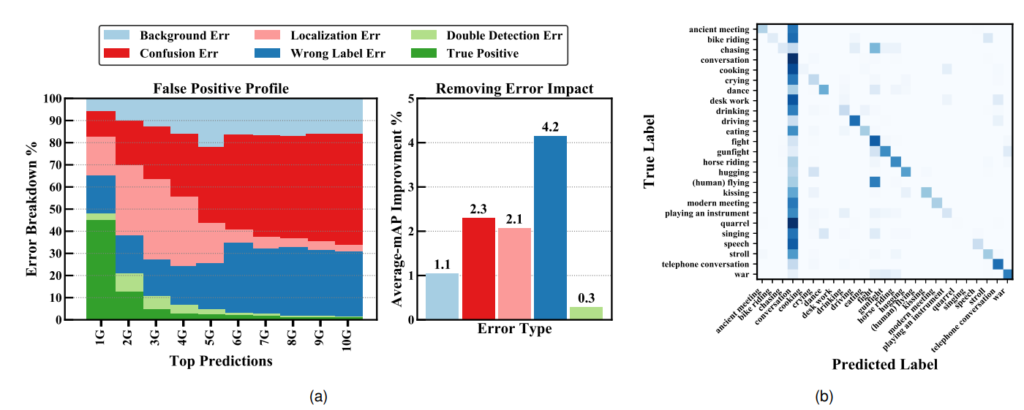
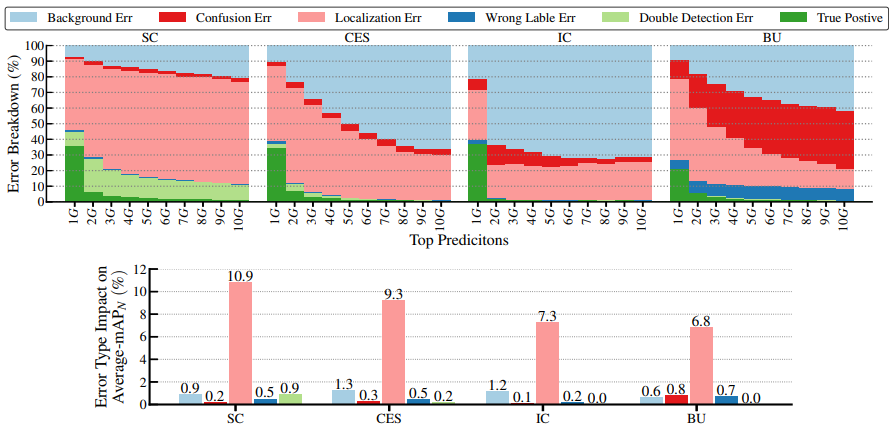
Fig 7-(a)는 Error Analysis 표입니다. Background Err는 prediction과 GT와의 tIoU가 0.1미만일 때, Localization Err는 label은 맞췄으나 tIoU가 0.1이상 threshold 미만일 때, Double Detection Err은 중복된 prediction의 tIoU가 label도 맞췄으나 최대 score의 예측이 아닌 경우, Confusion Err은 tIoU가 0.1이상 threshold 미만이며 label도 틀렸을 때, Wrong Label Err은 tIoU가 threshold 이상이나 label을 틀린 경우를 의미합니다. Fig7-(a)의 좌측 그림을 보았을 때, false postive의 대다수는 Confusion Err, Localization Err, Wrong Label Err이 차지하고 있는 것을 볼 수 있으며, Fig7-(b)에서는 Wrong Label Err을 개선하였을 때 가장 성능 개선율이 높은 것을 볼 수 있습니다. Fig 8은 ActivityNet-1.3에서 다른 SOTA 모델들이 Localizaion에만 주로 어려움을 겪는 것으로 보아 MUSES 데이터 셋에서의 Error Analysis 표는 빈번한 shot의 수로 인해 부정확한 boundary 예측과 label 예측이 발생하는 것을 의미합니다.
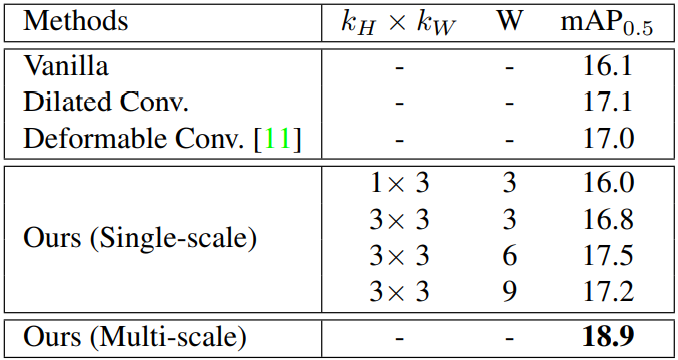
Table 2는 Temporal Aggregation 모듈에서 언급한 다른 convolution 방식을 사용하였을 때의 성능과 Multi-scale의 fusion이 아닌 Single-scale의 성능에 대한 ablation study를 보여줍니다.

is our re-implementation with the publicly available code.
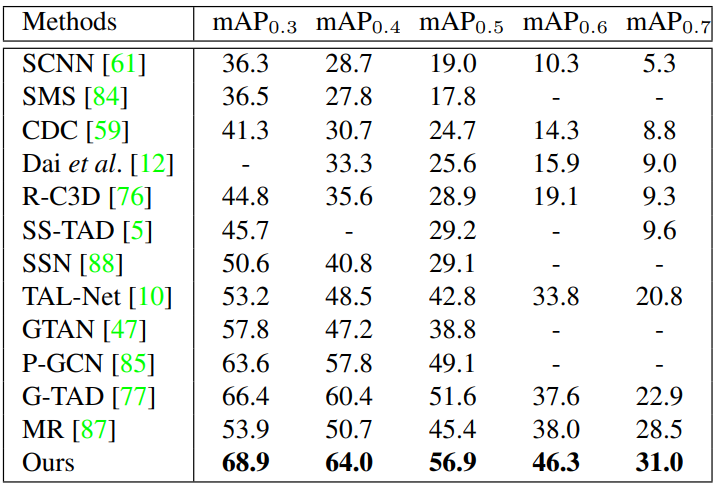
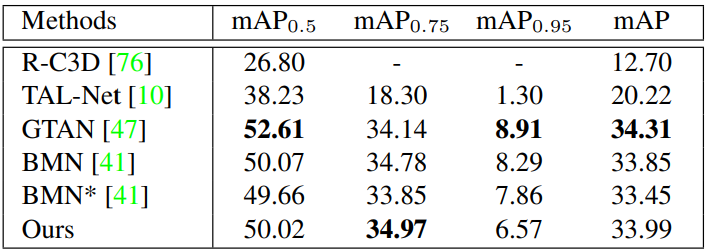
Table 3 은 MUSES 데이터 셋에서 제안된 baseline과 다른 SOTA들의 성능을 나타낸 표입니다. 상대적으로 다른 데이터 셋에서에 비해 낮은 성능을 보이는 것을 알 수 있습니다. 그리고 여기서 특이한 점은 해당 논문은 데이터 셋 중심의 논문이고 baseline은 단순히 제안된 데이터 셋에서의 성능을 보이기 위함인 줄 알았으나 MUSES와 THUMOS14에서 SOTA의 성능을 달성하였으며, ActivityNet-1.3에서는 두 번째로 우수한 성능을 보였다는 것입니다. Baseline은 BMN이라는 방법론에 temporal aggregation 모듈을 추가해 설계되었습니다.
3. References
[1] https://arxiv.org/pdf/2012.09434.pdf
[2] https://openaccess.thecvf.com/content_ECCV_2018/papers/Humam_Alwassel_Diagnosing_Error_in_ECCV_2018_paper.pdf