Introduction
3D 상황 인식은 중요하지만 비싸고 복잡하기 때문에 LiDAR나 stereo camera만을 이용하는 것은 어려울 수 있어 학습기반 방법론이 개발되었다. RGB-D 데이터는 RGB나 비디오 데이터에 비해 다양성과 양이 부족하며, 센서 노이즈와 구동 환경에서의 제한 때문에 대량의 GT를 수집하는 게 어려웠다. 따라서 stereo 이미지를 이용하는 것과 monocular camera를 이용하는 방법이 연구되고 있는데 monocular video를 이용할 경우에는 stereo 방식과 다르게 depth와 ego-motion(카메라의 3차원 이동)을 예측해야 한다. 정적인 장면에서 카메라 이동이 이뤄진다고 가정(카메라만 움직인다는 가정)하기 때문에 차, 사람과 같이 움직이는 객체와 관련된 픽셀은 “holes”로 추측하고 이를 해결하기 위해 특화된 구조, 마스킹 전략, 손실함수에 초점을 둔 연구들이 있었으나 stereo보다 성능이 낮았다. 이 논문에서는 self-attention과 discrete disparity prediction을 제안한다.
- self-attention
이미지의 비연속적인 영역에서 유사한 dispartiy value 추론이 가능한다. 즉, 주변(local)만을 고려하는 게 아니라 조금 떨어져 있는 영역(global)에 대해서 고려할 수있다. - discrete disparity prediction
더 robust하고 sharper한 depth를 예측할 수 있다.
– robust : 균일한 textural details로 인한 부정확한 pose예측과 matching 실패를 해결하기 위해 robustness의 향상은 중요하다. (마지막 부분과 연결해보면 이해가 된다.)
-sharper depth : 정확도 개선에 중요
Method
1. Model
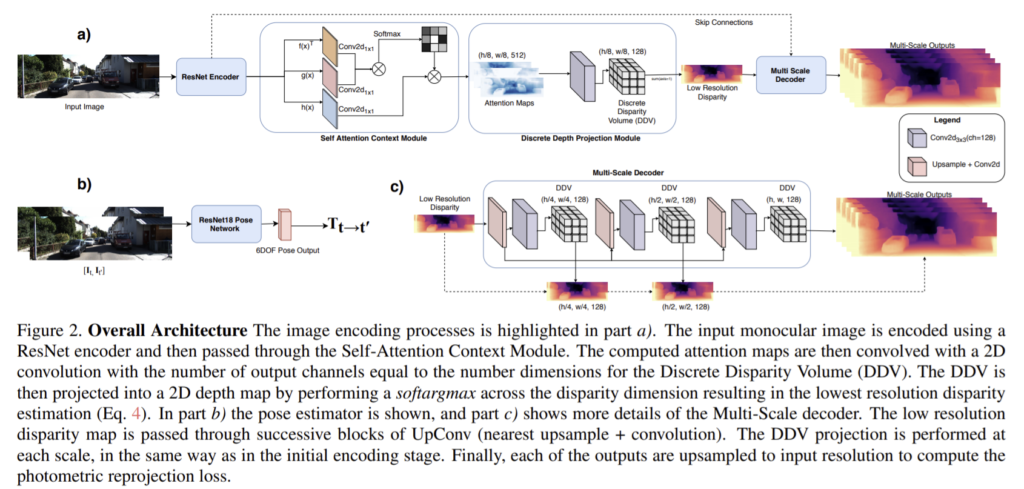
RGB 이미지를 ![]() 로 나타내고 이때 Ω는 이미지의 height H와 width W의 lattice를 나타내고 모델의 첫번째 단계는
로 나타내고 이때 Ω는 이미지의 height H와 width W의 lattice를 나타내고 모델의 첫번째 단계는 ![]()
![]() 로 나타낼 수 있는 ResNet-101 encoder를 거친다. 이때 Ω1/8은 초기 Ω보다 1/8 크기의 low-resolution의 lattice고 M은 ResNet의 output의 채널 수이다.
로 나타낼 수 있는 ResNet-101 encoder를 거친다. 이때 Ω1/8은 초기 Ω보다 1/8 크기의 low-resolution의 lattice고 M은 ResNet의 output의 채널 수이다.
이후 ResNet의 출력은 self-attention 모듈에 사용되어 다음 식 (1)로 나타낼 수 있는 query, key, value를 얻을 수 있다.
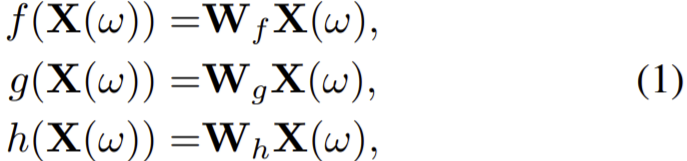
이때 ![]() 이고 query와 key는 다음 식 (2)로 결합된다.
이고 query와 key는 다음 식 (2)로 결합된다.
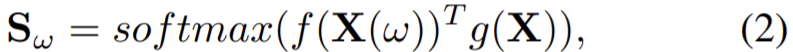
이때 ![]() 이고 g(X)는 N * (H/8) * (W/8)의 tensor크기를 갖는다. 그리고 self-attention map은 Sω와 value의 곱으로 만들어진다.
이고 g(X)는 N * (H/8) * (W/8)의 tensor크기를 갖는다. 그리고 self-attention map은 Sω와 value의 곱으로 만들어진다.
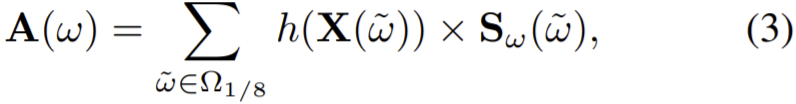
이때 ![]() 이다.
이다.
저해상도 discrete disparity volume(DDV)는 ![]() 로 나타낼 수 있고 이때
로 나타낼 수 있고 이때 ![]()
![]() (K는 discretized disparity 값의 수)를 나타낸다. disparity map은 식(4)로 계산할 수 있다.
(K는 discretized disparity 값의 수)를 나타낸다. disparity map은 식(4)로 계산할 수 있다.
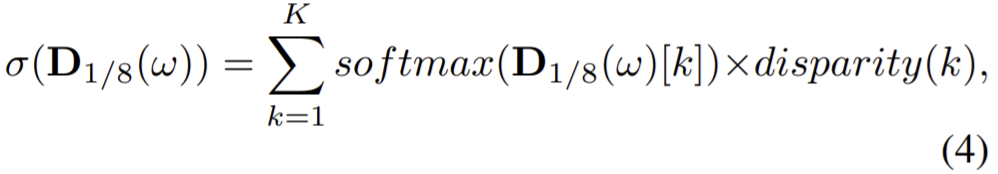
이때 ![]() 는
는 ![]() 의 k번째 output의 softmax결과이고 disparity(k)는 k의 disparity 값이다. 이후 저해상도 disparity map에 의해 모호한 결과가 만들어지므로 multi-scale을 이용한다. 저해상도부터 3단계의 upconv(nearest up-sample + convolution)와 ResNet encoder로부터 각각의 해상도에 skip connection을 진행한다. (Fig2의 c 참고)이후 각각 처음 크기에서 1/8 ,1/4, 1/2, 1/1의 해상도를 갖는 disparity map을 만든다.
의 k번째 output의 softmax결과이고 disparity(k)는 k의 disparity 값이다. 이후 저해상도 disparity map에 의해 모호한 결과가 만들어지므로 multi-scale을 이용한다. 저해상도부터 3단계의 upconv(nearest up-sample + convolution)와 ResNet encoder로부터 각각의 해상도에 skip connection을 진행한다. (Fig2의 c 참고)이후 각각 처음 크기에서 1/8 ,1/4, 1/2, 1/1의 해상도를 갖는 disparity map을 만든다.
pose estimator은 식(5)로 나타낼 수 있다.
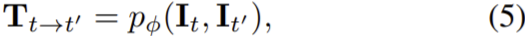
이때 t와 t’는 다른 두 시각이고 Tt→t’은 두 이미지의 변환행렬, pɸ(.)는 pose estimator로 ϕ파라미터의 딥러닝 모델이다.
2. Training and Inference
source image It’과 target image It사이의 각 픽셀의 photometric re-projection error를 최소화하는 방향으로 학습하고 각 픽셀의 에러는 다음과 같이 나타낼 수 있다.
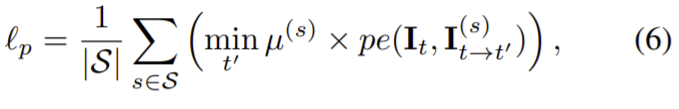
pe(.)는 photometric reconstruction error이고 S={1/8, 1/4, 1/2, 1/1}, t’∈ {t − 1, t + 1}로 It와 인접한 프레임을 source 프레임으로 이용한다. 그리고 µ(s)는 정지된 지점을 걸러주는 이진 마스크(식 (10) 참고)이고 식 (6)의 re-projected 이미지는 다음 식(7)로 정의된다.
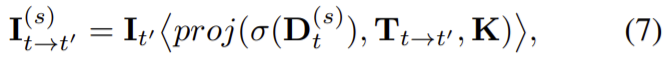
이때 proj(.)은 It의 depth인 Dt의 2D로의 투영이고 < >는 sampling 연산자이고
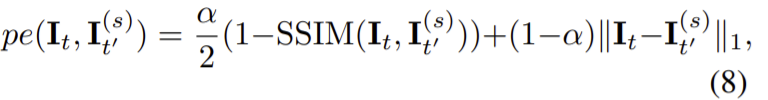
edge-aware smoothness 정규화 term을 사용하여
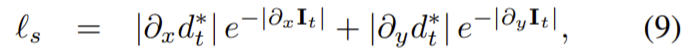
![]() 는 depth estimation의 축소를 막기 위해 평균-정규화된 inverse depth다.
는 depth estimation의 축소를 막기 위해 평균-정규화된 inverse depth다.
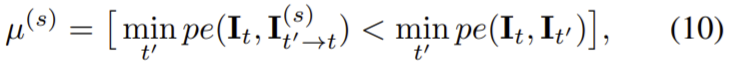
최종 loss는 각 픽셀의 reprojection 최소 loss와 smoothness term의 가중합으로 나타낼 수 있다. 이때 λ는 smoothness 정규화 term이다.

Experiments
KITTI 2015을 이용해 학습하고 KITTI 2015와 Make3D dataset을 이용해 평가했다. monodepth2에서 ResNet-18을 ResNet-101로 바꿔 메모리가 더 필요하지만 성능이 좋은 모델을 baseline으로 하였다. batch normalization과 activation functions을 합쳐 50% 까지 메모리를 절약하는 inplace activated batch normalization을 이용하여 메모리 이슈를 해결하였다.
ResNet-101 encoder의 마지막 2개의 convolutional block에서 dilation rate가 2, 4인 di convolution를 이용하여 성능을 향상시켰다. 이는 모델이 보는 영역을 증가시킴으로써 multi-scale encoding을 개선시키는 것을 보여준다.
- KITTI Results
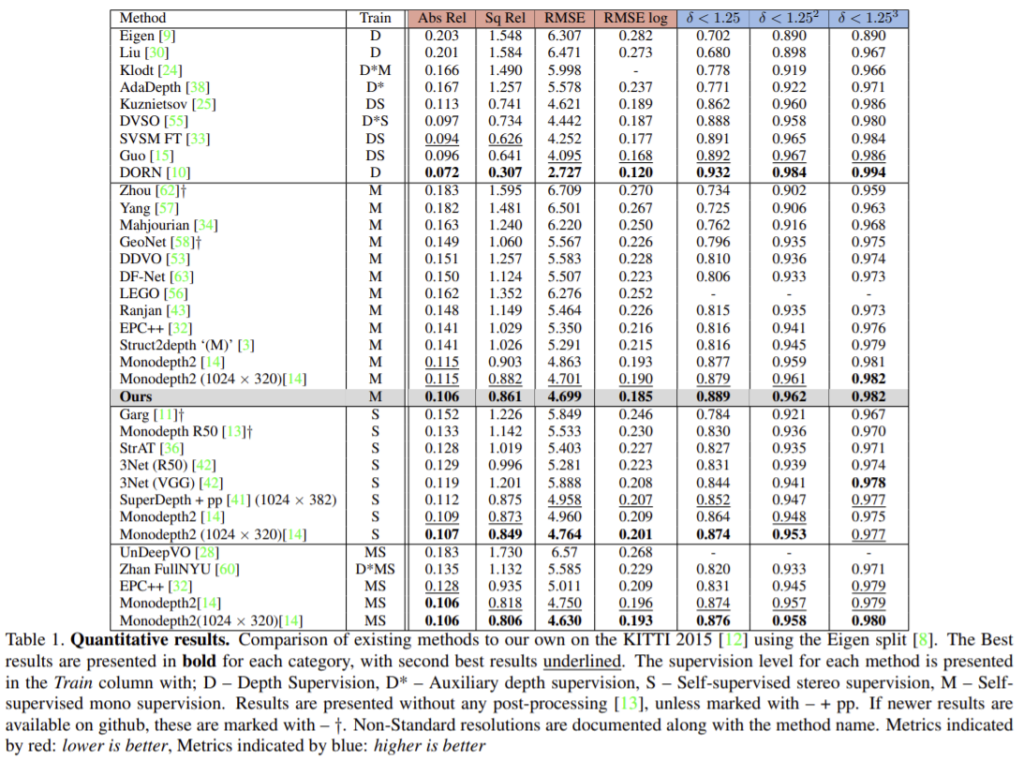
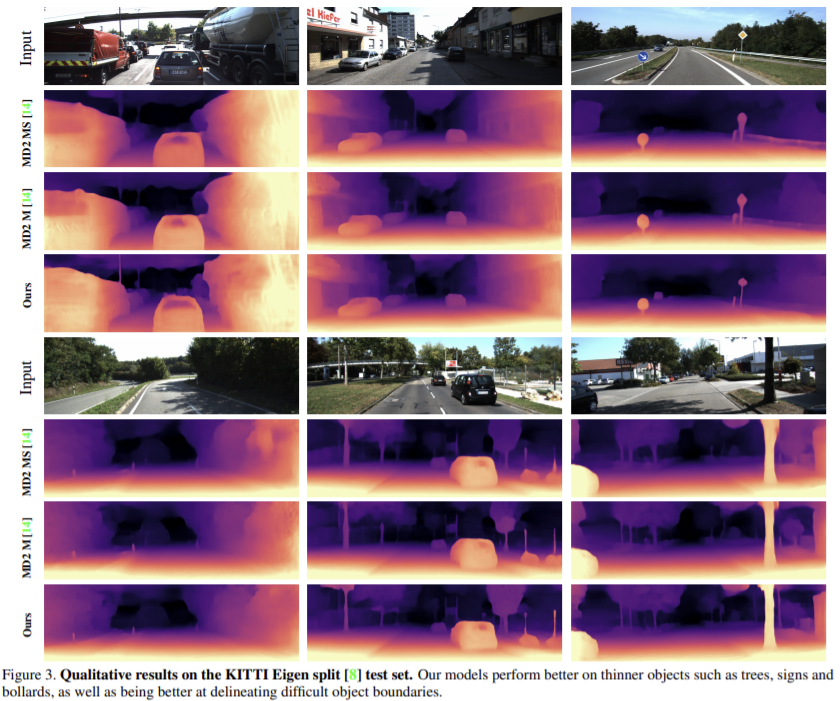
Self-supervised monocular중에 성능이 가장 잘 나오고 Self-supervised stereo방식과 비교했을 때도 대체로 성능이 좋게 나온다. 위의 그림에서 확인할 수 있듯이 얇은 기둥에 대해 monodepth2보다 더 sharp한 결과를 보여준다.(윗줄 가장 오른쪽의 경우 표지판의 봉 부분을 더 잘 찾은 것을 확인할 수 있다.)

Monodepth2는 유리 반사 표면의 깊이를 예측하는 것에 실패했고 이는 투명한 표면에 대한 깊이를 정확하게 예측할 수 없기 때문에 발생하는 문제이다. 이와 비교했을 때 이 논문의 방법론은 반사율이 높은 차량 지붕의 depth 예측에 성공했고 배경과 표지판을 성공적으로 분리했다. 이는 self-attention 모듈이 제공하는 추가적 문맥과 receptive field 뿐만 아니라 discrete disparity volume이 제공하는 정규화 로 설명할 수 있다.
- Make3D Results
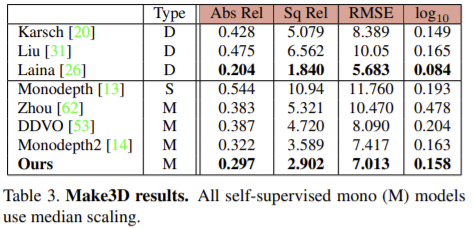
KITTI 2015에서 학습된 모델에 대해 Make3D를 이용하여 평가하였다.
- Ablation Study
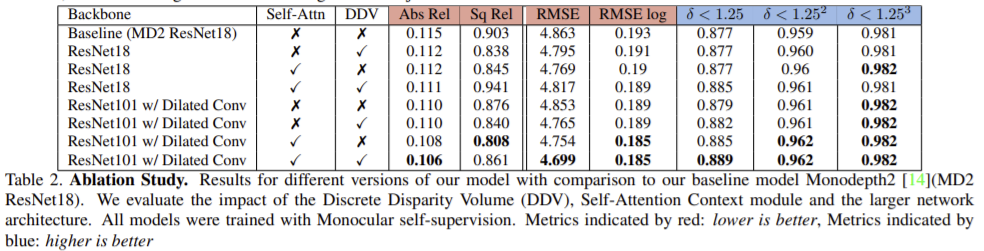
DDV의 유무는 ResNet-101보다 ResNet-18에서 더 큰 향상을 보여주었다.
self-attention의 경우는 두 백본 모두 가까운 영역에서(δ < 1.25) 큰 향상을 보여주었다. 이는 self-attention에 의해 계산될 수 있는 맥락 정보를 증가시키는 dilated convolution에 의한 넓은 receptive field에 의해서 일 수 있다.
- self-attention and Depth Uncertainty

식 (3)을 시각화하면 위와같이 전경,중간, 배경영역의 비연속적 영역을 강조한다. 또한 멀리있는 물체나 자동차와 같이 정지해있는 물체를 강조하는 경향이 있다.

거리가 멀어질 수로 불확실성 올라가다 무한에 가까운 깊이로 추정되는 영역에서는 낮은 불확실성을 보여준다. 불확실성이 높은 곳은 잎과 그림자가 있는 영역과 같이 색의 대비가 적고 textural 디테일이 부족하기 때문일 수 있다.
많은 실험을 시도해본 논문인 것 같습니다.
물론 해당 논문에서 수식을 통해서 많은 설명을 하고 있겠지만, 수학적인 수식의 의미해석 나열로 인해 결국 리뷰를 통해 저자가 논문에서 핵심적으로 이야기하는 방법이 무엇인지이 리뷰를 통해 이해하기 힘든것 같습니다…. 수식적으로 디테일한 설명도 좋지만 중간중간 저자의 논지를 정리해주시면 조금더 이해하는데 도움이될 것 같습니다 !
수식이 많은 내용을 함축적으로 담을 수 있어 매우 편리한 수단기이기도 합니다.
하지만 함축적인 의미가 담겨 있기 때문에 적절한 설명이 없으면 의도와 다르게 쉽게 잘못 이해할 가능성도 높아요. 그렇기 때문에 어쩔수 없이 논문들도 많은 부연 설명과 함께 수식을 설명한다고 생각합니다.
승현님은 논문의 설명과 자료들로 수식만 보고 이해가 되는 상태지만, 저희는 아무런 자료도 없이 승현님의 리뷰만 보고 있기 때문에 수식만의 흐름만 보고는 이해가 힘들어요.
몇가지 이해가 힘든 수식을 예를 들면
1. 수식 3에서 틸다 w는 수식 1,2의 w는 서로 다른 값을 가진 것이라고 예상이 됩니다. 그럼 수식 1의 value와 수식 3의 value는 다르다는 것으로 유추가 되겠죠? 그럼 수식 1의 value는 어디서 사용이되는지 궁금증이 생깁니다.
2. 또 다른 예시로 1/8에 있습니다. 수식을 보면 계속 1/8 아래 첨자를 가진 변수들이 등장합니다. 의미가 있으니 수식에 표기 했을거라고 생각합니다.
이제 수식을 알아보시는 능력은 충분하시니, 이제 논문에서 수식에 대해 말하는 바와 가능하다면 자신의 생각을 추가하여 작성해보면 좋을 것 같습니다. ++ 물론 저도 그럴려고 노력하겠습니다.