Before Review
이번 리뷰는 Video 분야에서 Object Detection과 유사한 , Temporal Localization problem을 multi-stage CNN을 처음 도입해서 문제에 접근한 Paper를 가져왔습니다. 논문에 이렇게 적혀 있었습니다.(To the best of our knowledge , our work is the first to exploit 3D ConvNets with multi-stage processes for temporal action localization in untrimmed long videos in the wild.)
제목에서 느낄 수 있는데 , Multi-stage의 구조를 제안하며 , 이는 Two-stage 기반의 Object Detection 과정과 상당히 유사하게 설계되었습니다. Two-stage 기반의 Detector에서 Convolution layer만 3D convolution으로 바뀐 정도의 구조를 가지고 있고 , 따라서 이해하는 데 크게 어렵지는 않았습니다.
다만 , Video 관련 논문을 읽어보지 않은 분들은 3D Convolution 개념이 생소할 수 있어 , 본 논문의 리뷰를 시작하기 전에 간단하게 알아보고 가도록 하겠습니다.
3D Convolution
간단하게 설명하자면 , 비디오 같은 경우는 프레임의 연속이기 때문에 프레임과 프레임 사이의 연관관계인 시간 정보 , Temporal한 Information도 중요하게 작용하게 됩니다. 이를 위해 3D convolution은 시간 축으로도 Convolution filtering이 진행됩니다.
따라서 , 3D convolution filter는 축이 하나 늘어나게 됩니다. 바로 시간에 대한 축이고 , frame 간의 정보를 받아오게 됩니다.
아래의 그림을 보면 조금 감이 오실 수 있는 데 , 그림 (b) 와 (c)의 차이를 주목해서 보시면 됩니다.

좀 더 구체적으로 비교를 해보도록 하겠습니다.
2D convolution
input data : (3 , 16 , 171 , 128) = 3채널이고(RGB) , 16 frame으로 구성 , resolution은 171 x 128
convolution filter dimension : (16 , 3 , 3) = 3 by 3 의 kernel_size를 가지며 depth는 16
이때 2d convolution을 적용해주면 , 16 frame이 한꺼번에 연산이 진행되기 때문에 프레임간의 시간적인 feature를 효과적으로 추출할 수 없다고 합니다.
3D convolution
input data : (3 , 16 , 171 , 128) = 3채널이고(RGB) , 16 frame으로 구성 , resolution은 171 x 128
convolution filter dimension : (3 , 3 , 3) = 3 by 3 의 kernel_size를 가지며 depth는 3
이때 3d convolution을 적용해주면 , 16 frame을 세 개씩 살펴보면서(depth = 3) frame 방향으로도 stride 연산이 진행되며 , 그림 (c)와 같은 방식으로 연산이 진행되게 됩니다.
2D conv는 multiple frame에 대해 적용해주면 2차원 형식의 feature map이 생성되면서 temporal한 information을 읽게 되지만 , 3D conv는 multiple frame에 대해 적용해주면 3차원 형식의 volume을 가지는 feature map이 생성되면서 temporal 한 정보를 유지할 수 있게 됩니다.
이와 같이 Video에서는 spatio-temporal(시공간)적인 feature를 추출하기 위해 3D Convolution을 사용하게 됩니다.
Introduction
본 논문은 Untrimmed Video에서 action이 어디에 위치하는 지 , 예를 들어 줄넘기를 하는 Untrimmed Video라면 영상 내에서 실제로 줄넘기라는 action이 언제 시작되고 , 언제 종료되는 지 그 구간을 예측하는 Temporal action Localization을 multi-stage 3D CNN를 도입한 첫번째 논문입니다.
실제로 우리가 다루어야 할 많은 비디오 데이터는 Untrimmed video 형태로 존재하게 됩니다. 특히나 실제 application에서는 하나의 비디오 내부에 여러개의 action instance들과 background scene들이 포함되는 Untrimmed Video를 다루어야 하는 것을 요구하고 있습니다.
당시 2014년도 , 2015년도 SOTA 방법론들은 전통적인 handcrafted 방법을 사용을 했었던 것 같습니다. Improved Dense Trajectory(iDT) with Fisher Vector 방법론들을 사용했다고 하며 , 아직 CNN이 temporal localization 문제에 본격적으로 사용이 되지는 않았나 봅니다.
본 논문의 저자는 Video의 Temporal action localization 문제를 해결하기 위해 3D conv를 도입하게 됐고 , Network는 크게 3가지 network로 구성이 되어 있습니다.
- The proposal Network
input으로 들어오는 segment들(비디오 내 프레임의 연속적인 부분집합)이 action인지 background인지 구별하는 역할을 담당하며 , action을 담고 있지 않는 것 같은 background segment의 수를 줄이기 위해 설계 되었습니다.
- The classification Network
위에서 정의해준 Proposal Network에서 걸러진 Segment들을 input으로 받아와 , 각 Segment들의 action label이 무엇인지 구별하는 역할을 담당하며 , 각 Segment들은 action label 에 대한 확률값을 가지게 됩니다.
- The localization Network
마지막으로 Localization Network입니다. 여기서는 새로운 Loss를 적용한다고 합니다. Ground Truth 영역과 얼마나 겹치는 지에 따라서 , 값을 상이하게 부여하며 , action의 시작과 끝을 예측하는 작업을 수행하게 됩니다.
Detailed descriptions of Segment-CNN
Problem setup
- Input Video : X=\{ x_{t}\}^{T}_{{}t=1} , 이때 , T는 비디오 X의 전체 프레임 갯수 입니다.
- temporal action annotation : \Psi =\{ (\psi_{m} ,\psi^{\prime }_{m} ,k_{m})\}^{M}_{m=1} , 이때 M은 비디오 X안에 있는 action instance들의 전체 갯수 입니다.
- \psi_{m} = m 번째 action의 시작 시간
- \psi^{\prime }_{m} = m 번째 action의 종료 시간
- k_{m} = m 번째 action의 action label , k_{m}\in \{ 1,2,\cdots ,K\} , 이때 K는 action label 갯수
- \Phi =\left\{ \left( s_{h},\phi_{h} ,\phi^{\prime }_{h} \right) \right\}^{H}_{h=1} , 이때 H는 untrimmed video에서 segment 갯수
네트워크에 들어가는 Input은 두가지의 형태로 나눌 수 있는 데 Trimmed Video와 Untrimmed Video에서 Sampling 해올 때입니다. Trimmed Video에서는 그냥 16 frame만 uniform하게 sampling 해오면 되고 , Untrimmed Video에서는 temporal sliding window를 만들어서 sampling을 진행합니다. 마치 Detection에서 후보군을 만들기 위해 하는 방법과 비슷하다고 생각하시면 됩니다. Untrimmed Video에서 각 sliding window(16 , 32 , 64 , 128 , 256 , 512 frames)에서 16 frame씩 sampling해 segment를 만든다고 생각하시면 되겠습니다.
Training procedure
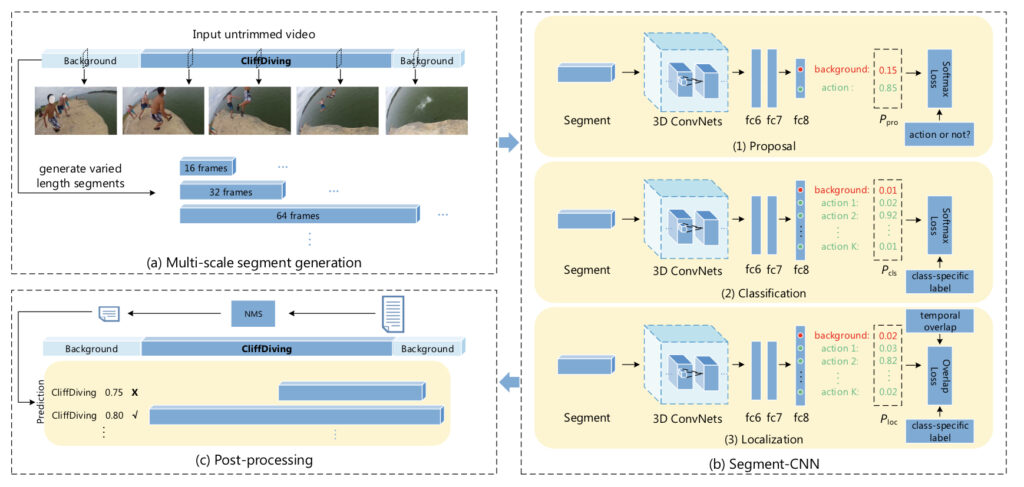
- The Proposal Networks
앞서 언급했듯이 , Proposal Network에서는 input으로 들어온 Segment들이 foreground(action)인지 background인지 구별해주는 역할을 수행합니다. Trimmed Video로 부터 들어온 Input이라면 당연히 action만 존재하게 되므로 , positive 한 label을 부여해줍니다. 하지만 Untrimmed Video로부터 들어온 Input이라면 GroundTruth와 IoU를 측정해서 일정 Threshold를 넘기면 action , 넘기지 못하면 background 이렇게 label을 부여해주게 됩니다.
따라서 본 Network로 들어오는 Input Segment들은 Trimmed(action) + Untrimmed(action) + Untrimmed(background)와 같이 구성되며 각 Segment들이 action인지 , background인지만 구별해주게 됩니다.
- The Classification Networks
Two stage Detector에서 Region Proposal Stage를 통해 Background box들이 제거 되는 것 처럼 , 본 Network에서도 Proposal Network를 통해서 , 상당한 Background Segment들이 제거가 됩니다. 여기서는 이제 각 Segmen들을 Network에 통과시켜서 , softmax 처리를 통해 , 각 action label이 무엇인지 예측을 수행해주게 됩니다. 복잡한 내용은 없고 , Image Classification의 비디오 버전이라고 보시면 될 것 같습니다.
- The Localization Networks
Localization Network에서는 action의 시작과 끝을 예측해주는 역할을 수행해줍니다. 좀 더 자세히 얘기하면 Ground Truth와 더 많이 겹치는 Segment들의 score를 높이고 , 적게 겹치는 Segment들의 score를 낮추는 Network 입니다. 이게 무슨 얘기냐면 그림으로 살펴보도록 하겠습니다.

Classification Network를 통과하고 다음의 Segment들이 넘어왔다고 가정해보겠습니다. 육안으로 확인할 수 있듯이 , B에 해당하는 Segment를 남기고 싶고 , A와 C는 떨궈버리고 싶은 상황입니다. 하지만 이 상태에서 NMS(Non-Maximum-Suppresion)을 진행해주면 , B와 C가 떨어져 나가게 됩니다. 따라서 Localization Network에서는 이러한 상황을 방지하고자 , 실제 GT 영역과 더 많이 겹치는 Segment들의 score를 더 올려주고 , 적게 겹치는 Segment들의 score는 낮춰주게 됩니다.
이를 위해서 Localization Network에서는 새로운 Loss-Function을 정의해주게 됩니다. 핵심은 Overlap이 어느정도인가에 따라서 gradient를 update 할 수 있는 Loss 입니다.
우선 input 부터 살펴보도록 하겠습니다. Localization Network에 들어오는 Input 들은 역시나 Segment 형식이고 , Ground Truth와 얼마나 겹치는지에 대한 정도를 나타내는 overlap measurement : v 가 같이 딸려오게 됩니다.
Trimmed Video에서 온 Segment라면 v = 1 , Untrimmed Video에서 온 Segment라면 v = IoU with Ground Truth가 됩니다.
이제 새로운 Loss 함수를 소개하면 다음과 같습니다.
Loss=Loss_{softmax}+\lambda \cdot Loss_{overlap} Loss_{softmax}=\frac{1}{N} \sum_{n} (-log(P^{(k_{n})}_{n})) Loss_{overlap}=\frac{1}{N} \sum_{n} (\frac{1}{2} \cdot \left( \frac{P^{(k_{n})^{2}}_{n}}{v^{\alpha }_{n}} -1\right) \cdot [k_{n}>0])주목해서 봐야 하는 부분은 overlap을 담당해주는 Loss함수 인데 해석을 하자면
[k_{n}>0]가 의미하는 바는 Segment가 action label을 가지고 있다면 1을 할당해주고 , Segment가 Background라면 0을 할당해주는 것 입니다.
분모에 있는 v_{n} 값을 가지고 detection Score인 (P)를 조절한다고 보면 됩니다. high overlap이라면 Score를 Boost 시켜주고 , low overlap이라면 Score를 Reduce 해주게 됩니다.
\alpha 값을 조절하여 score의 강도를 조절해준다고 합니다.
이러한 Loss를 설계함으로써 Overlap에 따른 Score를 할당할 수 있다고 하며 , 이를 통해 Localization Task를 수행하게 됩니다.
Experiments
우선 본 논문에서 제안된 방법이 당시에 SOTA를 달성하게 됐다고 합니다.
당시에 Temporal localization 연구가 활발하지는 않았는 지 베이스라인이 뭔가 적다는 생각이 들었습니다. 아무튼 베이스라인으로 제시된 3가지 방법론들과 비교를 하게 되는데 기존의 방법들은 Introduction 부분에서 설명했듯이 , iDT + Fisher Vector 였고 , 각각의 방법론 마다 미세한 차이점은 존재했습니다.
사진으로 보면 다음과 같습니다. 평가 기준은 mAP 입니다.
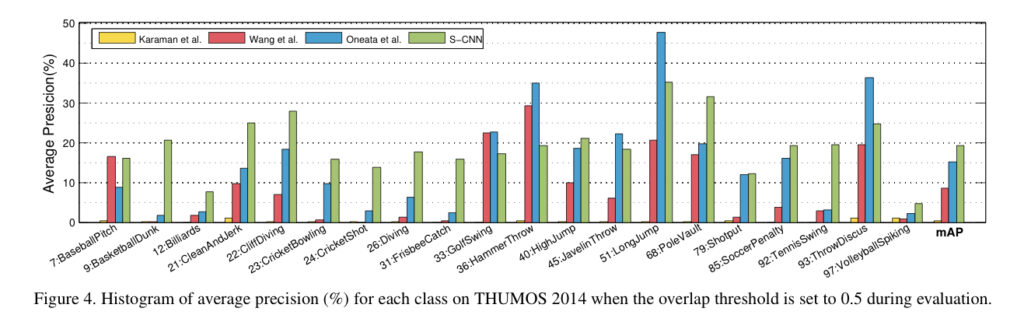
본 논문에서 제안한 방법은 연두색 막대기로 표현된 S-CNN이며 , 모든 action에서 performance가 뛰어난 것은 아니지만 , 대대수의 action에서 좋은 성능을 보여주고 있고 , 종합적인 성능은 SOTA를 보여주고 있습니다. 기존 방법론에 대해서 자세하게 서술해주고 있지는 않아서 , 설명은 잘 못하겠지만 아마도 Handcrafted Feature에서 Neural Network로 본격적으로 넘어왔으니 , 성능 향상은 당연한 수순이지 않나 싶습니다.
Conclusion
본 논문의 가장 큰 Contribution은 CNN을 사용하여 Video Temporal action localization task에 처음 접근한 것에 있는 것 같고 , 당시 SOTA였던 방법론을 능가하는 성능을 얻어낸 것에 있다고 생각합니다.
당분간은 논문들은 Temporal Action Localization을 위주로 읽을 생각입니다. 이 논문을 고른 이유는 기초를 쌓기에 적당한 논문이라 생각이 들어 고르게 됐습니다. 이 이후에 나온 Paper에서 Temporal action localization task를 어떻게 접근하는 지는 계속 X-review에 정리해서 올리도록 하겠습니다.