안녕하세요 이번 주에 리뷰할 주제는 조금 특이한 Monocular Far Infrared camera를 활용한 보행자 행동인식 문제를 다룬 논문입니다.
해당 논문을 다루게된 계기는 이번 KAIST Revisit 논문계획이 사실상 장기프로젝트화 되면서 하계방학기간동안에 새로운 프로젝트를 하기로 정했기 때문입니다. 그래서 아이디어를 얻고자 재밌어보이는 논문을 고르던중 발견하였습니다.
카이스트 멀티스펙트럴 데이터셋을 인용한 논문중에서 찾게되었고, 2021년에 발표된 논문입니다. 아직 인용횟수는 없지만 꽤 괜찮은 논문인거 같습니다. 내용이 많고 다소 새로운분야라 잘 읽히지는 않았지만, 설명이 비교적 자세하게 서술되어있어서 도움이 많이 되었습니다. 다만 24페이지 짜리 논문이라 상당히 내용이 많고 수식적인 내용을 많이 다루어서 쉽진 않았습니다.
개인적으로 이 논문을 읽게된 이유중 또다른 하나는 이번에 이석주박사님 세미나에서 들은 발표내용중 이해하기 어려운부분이 많아서 비슷한 분야에 대해서 조금 식견을 넓혀보고자 함도 있습니다. 이석주박사님이 발표했던 내용들중에서 monocular 카메라를 이용하고 자동차들이 어떠한 방향으로 이동하는지 추정한다는 내용들이 있었습니다. 해당 논문에서도 monocular카메라를 사용하고 비슷한내용이 들어가 있습니다. 다만 특이한점으로는 해당 논문에서는 monocular카메라를 infrared camera를 사용합니다.

Figure 1입니다. 그림으로부터 직관적으로 알 수 있듯이, 해당 연구는 Thermal imagery만을 사용하여 pedestrian이 cross하는지 not cross하는지 인식하는 문제입니다. 그리고 이러한 연구는 collision warning이나 avoidance에 사용 될 수 있습니다. 아무래도 Thermal imagery만을 사용하다보니 멀티스펙트럴을 사용하는 것보다는 좀 한계가 있을거 같긴합니다. 예를들어 위의 그림에서 보이듯이 street위에있는 zebra marking 같은 정보는 보이긴하나 뚜렷하지 않습니다. 그러한 한계가 있음에도 불구하고 thermal만 사용해도 해당 논문에서 제안하는 task들이 큰 문제없이 가능하단게 조금 놀라웠습니다.
위에서 pedestrian이 cross하려고하는지 not-cross하려고하는지에 대한 연구라고 해당 논문을 소개하였습니다. 그 궁극적인 목표를 이루기 위해서 3가지 task를 해결해야합니다. 일단 우리가 잘 아는 detection을 해서 우선적으로 보행자를 인식합니다. 그리고 각각의 보행자마다 unique한 id를 부여하고 보행자들을 tracking합니다. 마지막으로 tracking되고 있는 보행자들이 어떠한 행동을 취할지에 대해서 action recognition합니다. 이러한 과정을 거쳐서 최종적으로 특정 보행자가 길을 건너려고하고있는지 아닌지에 대해서 라벨링하고 아웃풋으로 배출합니다.
Data acquisition;
2) Road surface estimation;
3) Pedestrian detection and tracking;
4) Pedestrian distance estimation;
5) Pedestrian speed computation;
6) Pedestrian action recognition;
논문에서는 해당과정을 위와같이 소개합니다. 이러한 task를 하기위해서 직접 보행자 데이터셋을 취득을 하고 이를 사용하였습니다. 아무래도 보행자가 길을 건너려고하는지 아닌지에대한 정보가 많이담기고, 액션에대한 라벨데이터가 있는 데이터가 필요했기때문에 직접 데이터셋을 촬영한거 같습니다.

어떠한 세팅에서 데이터셋을 찍었는지 논문내용을 가지고 왔으니 궁금하신분들은 위의 Figure2를 참고하시기 바랍니다.
CROSSIR DATASET
그렇게 찍은 데이터셋이 CROSSIR DATASET입니다. 640*480의 해상도로 thermal 이미지 만으로 구성되어있습니다. 86개의 시퀀스한 씬으로부터 촬영하였으며, day, night을 모두 다루고 있습니다. 그리고 Annotation은 아래와 같은 내용들을 담고 있습니다.
• Pedestrian identifier (id) – that is unchanged for every
frame in which the pedestrian appears, making the
dataset appropriate for tracking algorithms.
• Pedestrian bounding box in the form of top left coordinates,
width and height.
• A label for the performed action. It can be cross or not
cross.
• A label for the direction of movement with respect to the
road. The label can take the values: lateral, longitudinal
or diagonal.
• A label for the type of motion: walk, stand, run.
• A label that marks if the pedestrian is occluded or not.
카이스트 데이터셋과 비교했을때, 다른점들은 일단 보행자들이 각 개개인의 identity에 따라서 고유 번호가 주어지는걸 볼 수 있습니다. 또한, 길을 건너려고하는지 아닌지에 따른 행동에대한 라벨값이 주어집니다. 그리고 어떠한 방향으로 움직이고있는지에대한 값을 별도로 라벨링하였습니다. 걷고있는지, 멈춰있는지, 달리고있는지에 대한 정보도 라벨링하였습니다. occlusion이 있는지 없는지에 대한 값도 라벨링하였습니다.
여기까지 보면 상당히 annotation cost가 많이 발생하였을것을 직감할 수 있습니다. 역시 thermal imagery만으로 해결하기에 상당히 어려운 문제라고 생각했는데 그만큼 annotation cost가 상당하네요. 그럼 각각의 annotation한 방식을 좀 더 그림으로 자세히 알아봅시다.

위의 글과 그림은 Pedestrian이 cross할 때의 상황에 대한 정의입니다. 간단하면서도 논리적이고, 아이디어가 참신하지만, annotaton cost가 너무 지나치다는 점이 계속 머릿속에서 사라지지 않네요.
그림에서 직관적으로 보이지만, 좀 더 부연설명을 하자면 pedestrian이 길을 건너고있을때와 curb에서 건너려고 하고있을때, 그리고 대각방향을 이동하고 잇을때를 모두 cross상황으로 정의합니다. 이 때, run, stop, walking 모두 candidate가 될 수 있습니다.

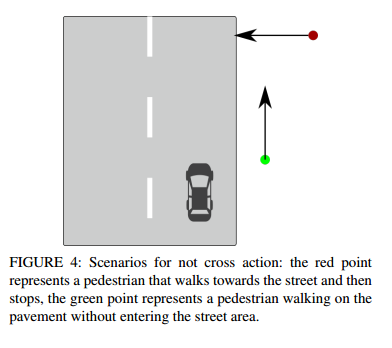
다음으로는 건너지 않는다고 정의한 상황입니다. pedestrian이 걷다가 curb에서 딱 멈추는 경우, 차와 parallel하게 side walks에서 움직이는 경우가 모두 Not cross 상황으로 정의됩니다.
These scenarios are depicted in Figure 4. The dataset contains fully visible and also occluded pedestrians. At least one pedestrian is present in each sequence. The total number of annotated frames is 14678. The dataset contains a total number of 175 unique pedestrians. Road segmentation sequences contain 471 night frames, and 376 day frames. These are annotated as polygonal areas. The annotations are made for a random subset of frames from all the acquired videos in order to ensure the large diversity of the annotations.
위의 내용처럼 적어도 1명씩은 pedestrian을 포함하게끔 데이터셋을 구성하였고, 총 14678 개의 frame으로 구성되어 있습니다. 좀 더 세세한 내용은 위의 원문을 참고해주세요.
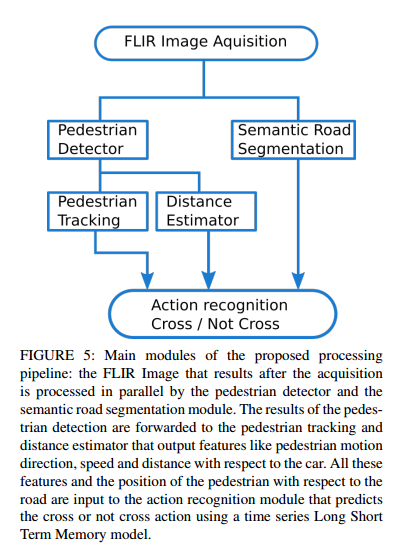
전체적인 파이프라인은 위와 같습니다. FLIR 카메라로 부터 얻은 thermal image로부터 detection과 Road segmentation을 동시에 수행하고, detection한 결과로 Pedestrian tracking과 카메라가 탑재된 ego-vehicle으로부터 각 pedestrian까지의 거리를 estimate합니다. 그리고 이러한 결과들을 종합하여 pedestrian이 길을 건너려고하는지 아닌지 행동을 예측하게 됩니다.
먼저 detection과 tracking에 대해서 이야기 해보겠습니다. 보행자를 먼저 인식하고 tracking하는 것이기 때문에 detection과 tracking은 밀접한 관련이 있습니다. 각각의 보행자를 인식하고, motion and appearance scores를 설계하여 해당 스코어를 기준으로 프레임에서 각 detect된 instance간의 correspondence를 비교함으로써 tracking을 합니다. 그리고 결과값중에서 unwanted track을 remove함으로써 refinement를 하고, 최종적인 tracking값을 도출합니다.
구체적으로 예시를 들자면, 먼저 detect된 보행자가 있고, 해당 보행자에 corresponding하는 bbox가 있다고 합시다. 그리고 이와 더불어 detection결과값인 class probability가 있을 것 입니다. 이러한 값들이 input데이터가되고, output은 각 보행자의 고유ID와 smoothing처리가 된 track이 됩니다.
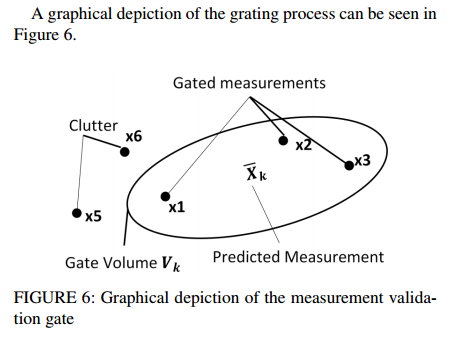
이러한 과정에서 모든 frame간의 association score를 다 구해서 비교하는 것은 computation cost가 너무 많이 발생합니다. 따라서, 해당 논문에서는 measurement validation gate 라는 유닛을 설계하고 comparison 횟수를 줄이기위해 위의 그림에서 나타난것처럼 사용합니다. 타원형의 gate volume을 구하고, 해당 영역에 있는 녀석들만 take into account하는 방식으로 computation을 줄이는 컨셉에 대한 설명만 논문에 명시되어있고, 수식에 대한 설명은 reference 논문을 걸어놓고 생략되어있어서 기회가 되면 나중에 읽어보고 리뷰하겠습니다. 다른내용이 워낙많아서 이번 리뷰에서 못다루게된점은 양해부탁드립니다.
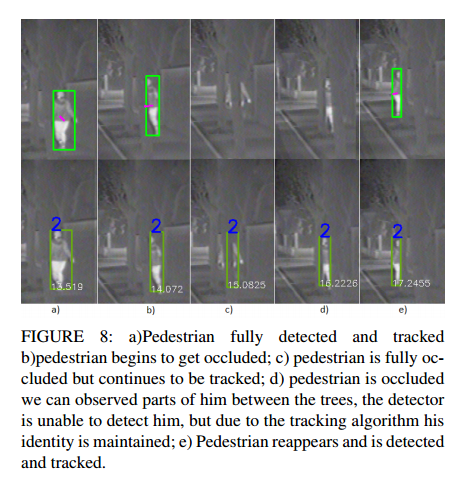
위의그림은 occlusion이 발생했을때의 예시 사진이며, fully-occluded였다가 visible해도 같은 id로 tracking이 되는 모습입니다.

사람을 Detect한다음 bbox를 치고, motion에 해당하는 vector값을 예측한 모습(좌상), 각각의 사람마다 unique한 id를 예측하고, 그에 상응하는 tracking값을 예측한 모습(우하) 입니다.
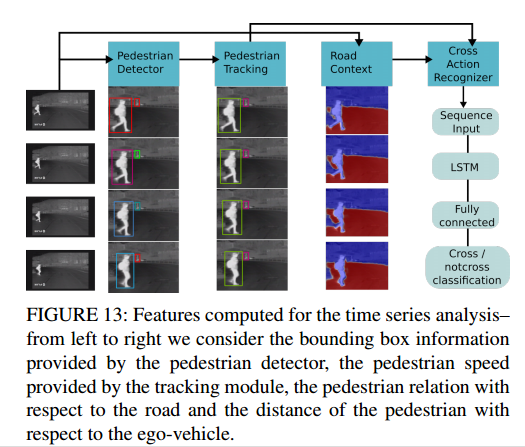
위의 그림은 위에서 다루었던 내용을 조금 다른 형태로 나타낸 것 뿐입니다. 위에서 언급한 Detection과 Tracking을 한 후, Road에 대해 바이너리하게 segmentation을 합니다. 그리고 이러한 road의 위치정보와 tracking정보를 종합하여 단순 LSTM모델에 태우고, action을 최종적으로 classification하게 됩니다. segmentation과 LSTM모델은 기존에 존재하던 모델을 단순 사용하였고, 저자가 직접 변형을 하거나 하진 않았습니다. 따라서 설명은 생략하고, 더 궁금하신분들은 논문에 Ref가 달려있으니 참고하시기 바랍니다. 조금 특이한점은 segmentation Network를 학습하는 과정에서 Encoder는 ImageNet pre-train하고, 뒤의 decoder는 스크래치부터 train 했다는 점인데 사실 이도 딱히 특이하다고 보긴 힘들거 같긴 합니다. 해당 논문이 전반적으로 기존에 존재하던 방법론들을 잘 활용하였고, thermal만을 이용해서 했다는게 주요 핵심이라고 이해하면 될거같습니다. 물론… 개인적인 의견으로 해당 웤을 실제로 산업현장에 사용하려면, annotation된 데이터셋 확보가 어려워서 big data기반으로 training 하기 쉽지 않을거 같단 한계가 있습니다.
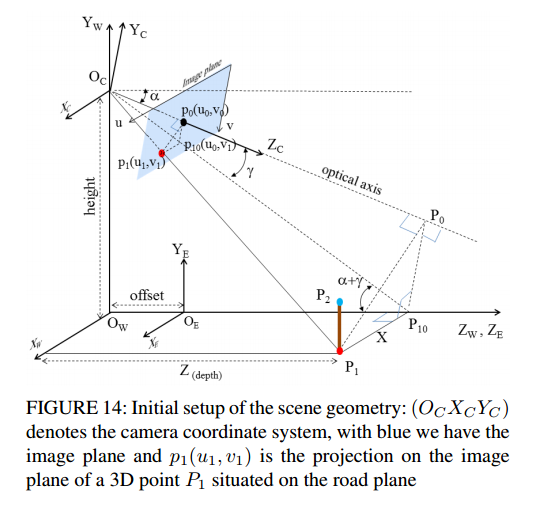
복잡해보이지만, 아마도 이번에 새로오신 URP인턴분들을 제외하고 다들 아시는내용이라고 생각합니다. Multi-view Geometry 내용을 해당 카메라 setup에 적용한 것 입니다. 즉, Camera 좌표계, world 좌표계, Ego-vehicle 좌표계로 3분할 하였고, 이를 이용하여 ego-vehicle로 부터 relative한 distance를 compute하는데 사용합니다.
먼저 카메라좌표계가 맨 왼쪽에있고, 카메라의 광학축을 중심으로 선이 이어집니다. 그 선상에 Image plane이 존재하며 이는 virtual image plane에 해당합니다. 핀홀카메라를 생각해봤을때, image plane은 camera의 뒤에 생기며, 해당 평면에 투영된 이미지는 도립상이 됩니다. 그래서 정립상을 다루고자 virtual image plane을 정의하고 사용하는게 일반적인데 책마다 virtual image plane을 그냥 image plane으로 표기하는 경우가 많은거 같습니다. 해당 논문에서도 정립상이 유지되는 virtual image plane을 그냥 image plane이라고 표기하였습니다.
카메라의 광학축과 위에서 설명한 image plane이 만나는 교점으로부터 road로 평행한 수선을 내렸을때, road와 만나는 교점을 바로 ego-vehicle의 원점으로 설정합니다. 그리고 pedestrian의 distance는 해당 ego-vehicle로 부터 상대적인 거리를 사용하게됩니다.
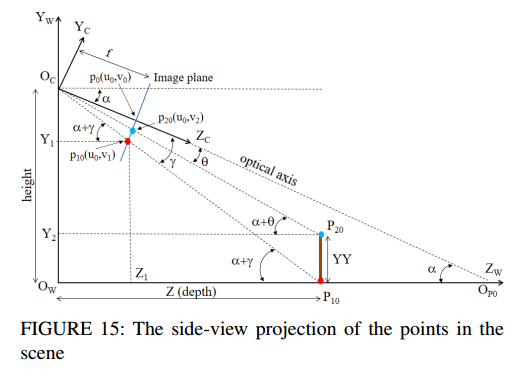
Side-view를 보면 좀 더 직관적을 알 수 있습니다. 해당 좌표계에서 Z에 해당하는 depth가 pedestrian의 거리입니다.
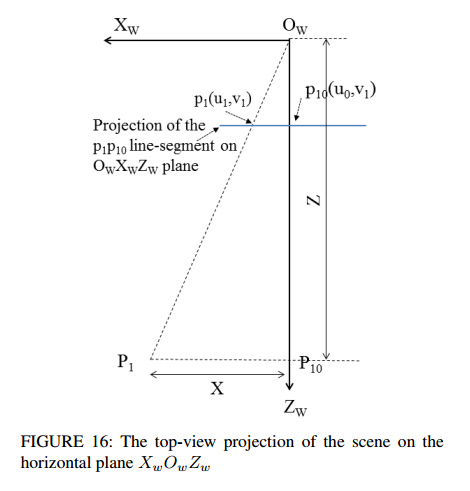
앞에서 얘기한 내용들을 Top-view로 위에서 내려봣을때의 모습입니다. 이를 이용하여 relative한 speed와 distance를 구하는데 사용합니다.

다음으로 소개할 내용은 큰 bbox안에있는 8개의 작은 bbox들입니다. 해당 부분은 pedestrian이 지면과 맞닿는 지점을 표기하기위해 도입하였으며, 해당 8개의 bbox들마다 road에 속해있는 영역을 구합니다. 예를들어 Pedestrian이 road에 있으면 8개의 bbox들이 모두 높은 값을 갖게 됩니다. 그리고 이 값들이 average 취해져 최종적으로 해당 보행자가 road있는지 아닌지 예측을 합니다.
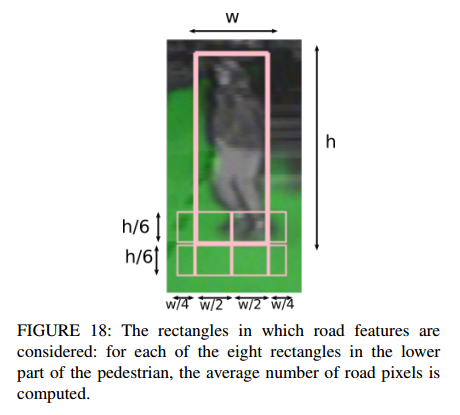
bbox는 위와같은 규격으로 width에 비례해서 나누어주었다고 합니다. 보통 scaling 관련 작업을 할때는 width를 기반으로 하는거 같습니다.
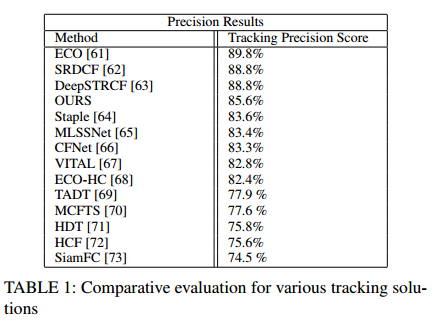
Tracking 성능이 이리 나왔다고 하는데, 제가 tracking분야 지식이 없어서 fair comparison인지에 대한 의심이 가네요. 예를들어 해당 work에서는 annotation된 정보를 많이 사용하였는데 저 비교 대상군들도 동일하게 annotation을 모두 활용하였을까요?

road semetation 결과입니다.
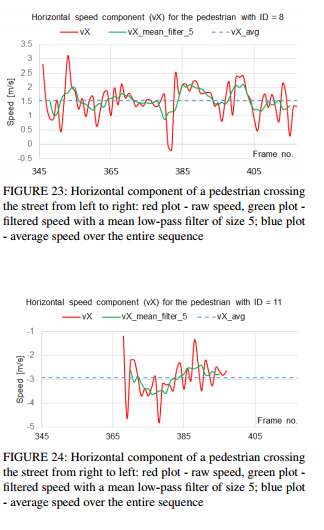
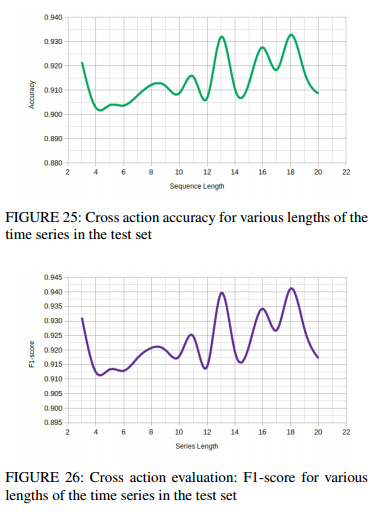
피규어 23~24는 고유한 보행자마다의 horizontal speed/전체프레임 분석내용이고 25~26은 평가분석내용입니다. 한번 확인해보시기 바랍니다. 이 밖에도 평가내용이 많은데 해당 논문을 참고하시기 바랍니다. 이러한 비슷한 종류의 그래프가 10개 가까이 되는데 다 소개드리는건 힘들거 같습니다. 마지막으로 데모비디오를 첨부해 두었으니 한번 확인해보시기 바랍니다. 이상 리뷰 마치겠습니다.
앞으로 해당 페이퍼가 어디에 공개된 것인지도 함께 알려주면 좋을 듯 합니다.
https://ieeexplore.ieee.org/document/9432859 IEEE Access 논문이군요.
피드백 감사합니다. 수정사항 반영하였습니다!