해당 논문은 unsupervised visual learning을 dynamic dictionaries 구축 과정으로 정의하며 contrastive learning을 위한 크고 지속적인 사전을 구축하기 위한 연구를 소개합니다.
Introduction
Unsupervised representation learning은 language processing 분야에서 supervised learning에 버금갈정도로 높은 성공률을 보이는데요, Computer vision 분야에서는 아직 supervised 방식의 pre-training 과정이 우세한 중요도를 갖습니다. 본 논문은 이를 word나 sub-word와 같은 구별가능한 signal space를 가진 언어만의 특성이 vision에는 정의가 되지 않았기 때문이라 언급하며, unsupervised representation learning을 단어가 없는 vision 영역의 사전을 구축하는 과정이라고 소개합니다. 기존의 해당 분야 연구는 주로 contrastive loss를 최소화하는 방향으로 진행됩니다. 앞서 몇번 소개드렸던 군집 내 요소와 군집 간 요소를 비교하여 거리를 통해 feature space의 거리를 모델링하기 위한 Metric Learning의 일종입니다. 이러한 기존의 학습 방법의 문제점을 정의하며 논문이 진행하게 될 연구방향은 크고 지속적인 사전 구축이라고 합니다. 여기서 사전 구축이란 encoder를 말하는데요 unsupervised 연구에서 encoder는 데이터를 feature space로 보내는 과정이며 encoder를 통해 사전을 간접적으로 구축할 수 있습니다.
용어정리
- keys (tokens): 사전(dictionary)에서 Keys란 데이터에서 셈플링되어 encoder network를 통해 표현된 것
- query : 인코딩된 쿼리는 매칭되는 key와 유사해야한다.
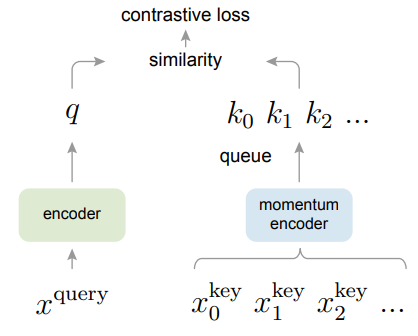
MoCo에서 구축한 dictionary는 데이터 셈플(key)의 큐(선입선출) 구조로 되어있습니다. 큐의 크기는 학습의 미니배치 크기보다 크며, 학습과정 중 당시의 미니 배치의 인코딩 키들은 대기열에 enqueue되며 오래된 것은 dequeue됩니다. triplet loss에서 positive&negative pair를 구축하는것처럼 미니배치 내에서 queue 구조체 형식으로 dictionary를 구축한 후 positive&negative 샘플을 추출합니다. 쿼리와 키는 동일한 이미지의 변형일 때 매칭됩니다.
Method
1. contrastive learning
contrastive learning은 encoder를 학습시키기 위한 학습법입니다. 이는 positive, negative sample과 쿼리와의 유사도를 이용하여 학습하는데 식1의 InfoNCE를 통해 loss 함수를 구성합니다. 식의 τ는 hyper-parameter이며 하나 이상의 positve (K+)와 K개의 negative 의 합으로 계산됩니다. 즉 K+1개 방향의 log loss가 q를 K+로 분류하고자 하는것입니다. (왜 k개가 아닌 k+1개인지는 확인하지 못했다. 어떠한 조합의 갯수가 아닐까 하는데 확인이 필요하다)
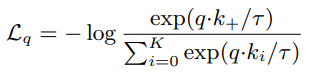
2. Momentum Contrast
그렇다면 Momentum Contrast가 무엇일까요? dynamic한 무언가를 만들때의 중요한 것 중 하나는 어떠한 변화에 어느정도 대응을 할 것인가? 입니다. 랜덤 샘플링된 키가 training과정에 영향을 마치는 동적인 과정을 어떻게 구성할 것인가? 이에 대한 논문의 해결책은 큰 사전을 만드는것입니다. 큰 사전을 통해 풍부한 negative samples을 지닌다면 학습시 다양한 아웃라이어등에도 안정적으로 학습할 수 있다는 것입다. Momentum Contrast는 풍부한 negative sample에 대한것입다.
1. Dictionary를 큐로 구성하기
큐 구조체를 이용하여 값이 점차적으로 변할 수 있음으로써 dynamic한 dictionary를 구성하였습니다. 미니배치보다 큰 사이즈의 큐를 이용하여 한 미니 배치 구간 이외의 데이터도 dictionary로 반영할 수 있으며 지속적으로 업데이트 됨으로써 dictionary를 관리합니다.
2. Momentum Update
Dictionary를 큐로 구성하면 큰 사전을 구축할 수 있지만, back-propagation시 모든 샘플에 gradient가 전달되지 않는다는 어려움이 있습니다. 이에 대한 해결책으로는 비교적 적은 데이터를 이용하는 query의 인코더(그림1의 녹색)를 key encoder로 사용하는것인데, 이는 대표성을 띄지 못하는 입력값 (적은 입력값)을 이용하게 때문에 학습의 성능이 좋지 않습니다. 이를 해결하기 위해 momenturm update를 도입합니다. key 인코더의 파라미터 업데이트를 위해 쿼리 인코더를 이용하되, momentum을 조절하여 대표성을 띌 수 있도록 합니다. 각 인코더의 파라미터를 θ라 할 때 업데이트식은 식2와 같습니다. m은[0,1)의 상수로 기본값으로는 0.99 입니다.
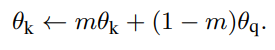
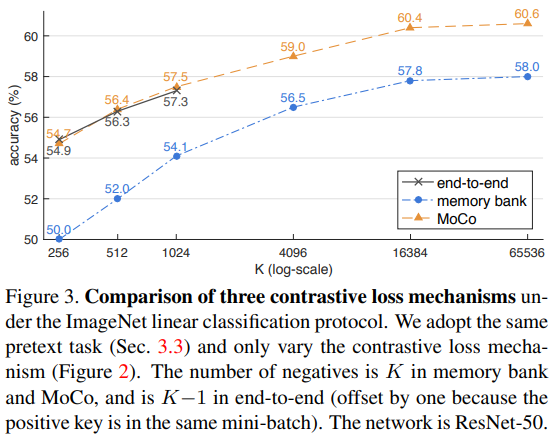
위와같은 방식으로 제한된 MoCo는 기존의 방법들과 얼마나 다를까요?
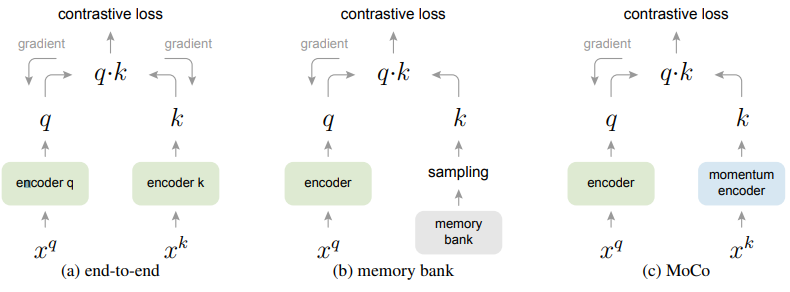
(a)의 end-to-end 방식은 mini-batch를 dictionary로 사용하는 구조입니다. 그러나 이는 대규모 미니배치 최적화에 어려움이 있어 사전의 크기에 제한이 있습니다. 다음으로 memory bank 구조는 사전이 모든 데이터셋의 샘플로 구성되어있습니다. 이는 back-propagation으로 인한 사전 샘플의 업데이터가 없으나 큰 사전의 크기를 유지할 수 있습니다. 이는 메모리 뱅크의 feature embedding 형식이 바로바로 업데이트 되지 않아 지속성이 떨어진다는 문제점이 있습니다.
실험
해당 논문은 unspervised learning의 목적이 downstream tasks에 적용할 수 있는 모델의 pre-training을 위함이라고 소개하며 MoCo가 다양한 pretext tasks에 사용할 수 있음을 보이기 위한 실험을 진행하였다. 실험은 ImageNet-1M, Insgagram-1B 데이터셋을 통해 기존 unsupervised 학습 방법과 비교 분석실험을 하였으며, ImageNet을 통해 pre-training된 모델을 PASCAL VOC, COCO 데이터에 transfer하여 object detection, segmentation, pose estimation과 같은 과 같은 다양한 Downstream tasks로의 확장을 보였다.
…..뭔가 작성되다만 느낌인데 맞나요..? 결과가 궁금하네요
네.. 맞습니다 작성중이라는 글을 적어두었는데 업데이트시 지워진것 같습니다 죄송합니다!
우리 유진이는 이 논문을 왜 고르셨을까나?
지난번 리뷰했던 A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning 에서 SlowFast 모델의 Slow가 Contrastive learning으로 진행될 수 있다는 부분을 보고 이어서 찾게 되었습니다. 비디오의 long term을 하나의 feature로 나타내는 방식(메모리 방식)이 아닌, 유사한 부분을 하나의 의미론적 feature로 나타낼 수 있다는 것이 흥미롭고 contrastive learning 학습방식이 개인적으로도 궁금하여 읽게 되었습니다.
MoCo를 Unsupervised 방식으로 학습하기 위한 implementation detail과 같은 항목이 있다면 설명해주실 수 있나요?
네 encoder로 ResNet을 사용하였다고 하는데, 이때 Shuffling Batch Normalization을 사용하였다고 합니다. 배치로 선입선출 형태의 사전을 구축하는 모델 특성상 naive BN을 사용하는것은 일종의 cheating이 될 수 있기 때문에 shuffling BN을 적용하여 이를 해결했다고 합니다.