저는 이번 주말동안 제가 어떤 분야에 관심이 있는지를 탐색하기 위해, 어떤 연구 분야가 있는지 그리고 어떤 논문들이 있는지를 계속 찾아보았습니다. 주말을 다 쏟았음에도 불구하고 제 심장이 반응하는(?) 그런 분야를 찾기는 어려웠습니다. 연구 분야를 보고 내가 좋아하는 것을 찾는 그 순서가 잘못된 것이 아닐까 하는 생각이 드는데요,,, 그래서 저는 아마 방학동안 계속 이 고민을 해야할 것 같습니다. 방학동안 다른 연구원들과도 이야기를 많이 나눠보고, 리뷰도 열심히 읽어서 계속 고민해봐야겠습니다. 이번 방학동안은 최대한 다양한 분야의 논문을 읽고 리뷰를 써보도록 하겠습니다 ?
각설하고, 본 논문 리뷰를 시작해보도록 하겠습니다. 어떤 논문을 읽을지 계속 고민하니 임근택 연구원이 논문 한 편을 추천하더군요. 제가 이번에 읽을 논문은 비디오 관련 논문입니다.. 허허 ..
Introduction
비디오에서 시공간 정보를 표현하기 위해서는 크게 두 가지 방법이 있습니다. 하나는 RGB 및 optical flow stream으로 구성된 2-stream 아키텍처를 사용하는 것이고, 다른 하나는 2D 커널 대신 시공간 3D 커널을 사용하는 것입니다. 3D CNN은 매개변수가 많아 성능이 좋지 않았지만, 최근 Kinetics와 같은 대규모 비디오 데이터 세트에서는 3D CNN 성능이 크게 좋아졌다고 합니다. 즉, 3D CNN은 2D CNN보다 얕지만 성능은 비할만 하다고 하네요.
다시 말해 이번 논문은 action recognition에 대한 논문입니다.. 그런데 이제 .. ResNet을 곁들인.. 3D Convolution kernel을 사용한 ResNet의 성능을 알아보도록 하겠습니다.
Related Work
Action Recognition Database
먼저 action recognition에 사용되는 데이터셋에 대한 설명입니다.
HDMB51와 UCF101는 action recognition에서 가장 많이 사용되는 데이터베이스라고 합니다. 그러나 이들은 largescale (대규모) 데이터베이스는 아닙니다. 이 데이터베이스를 사용하려면 overfitting이 발생하지 않고는 좋은 성능을 내긴 어렵다고 합니다. 따라서 최근에는 Sports-1M, YouTube-8M 과 같은 데이터베이스가 제안되었습니다. 이들의 크기는 충분히 크지만, annotation에 노이즈가 많고 video-level labels(즉, 타겟 활동과 관련 없는 프레임이 포함된 라벨 )만 있습니다. 이렇게 노이즈와 관계없는 프레임들은 모델이 좋은 성능을 내지 못하게 합니다. ImageNet에서의 사전 학습된 2D CNN과 같이 성공적인 사전 훈련 모델을 만들기 위해 Google DeepMind는 Kinetics human action video dataset을 공개했습니다. Kinetics 에는 30만 개 이상의 비디오와 400개 카테고리가 포함되어 있으며, 크기는 Sports-1M과 YouTube-8M보다 작지만 annotation의 quality는 매우 좋다고 합니다.
따라서 본 논문이 제안하는 3D ResNet을 최적화하는 데에 Kinetics를 사용했다고 합니다.
3D Residual Networks
Network Architecture
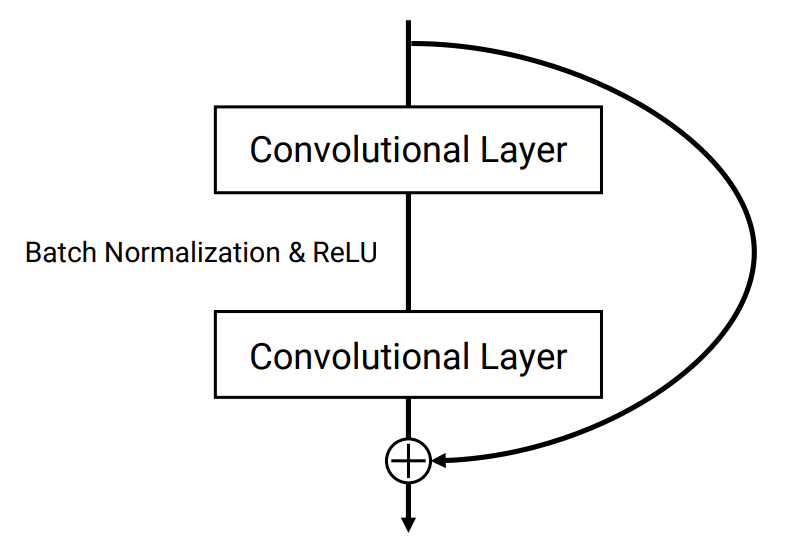
다들 아시겠지만, ResNet은 한 layer에서 다음 layer로 신호를 넘기는 shortcut connection을 도입함으로써 매우 깊은 네트워크 학습을 가능하게 한 네트워크 입니다. 아래 그림 1에서는 ResNet의 핵심인 residual block을 확인할 수 있습니다. 본 논문에서는 바로 이 ResNet을 기반으로 만들어진 네트워크를 제안합니다.
아래 표 1을 통해 본 논문에서 제안하는 ResNet 기반의 네트워크 구조(이하 3D ResNet)를 확인할 수 있습니다. ResNet 과는 컨볼루션 커널과 pooling의 차원의 수가 다릅니다 즉, 3D convolution과 3D pooling을 수행합니다. 이를 통해 temporal 정보를 모델링이 가능하게 됩니다.
- The sizes of convolutional kernels : 3 x 3 x 3
- temporal stride of conv1 : 1
- input : RGB clips (16 frames)
- The sizes of input clips : 3 x 16 x 112 x 112
- Down-sampling of the inputs : conv3_1, conv4_1, conv5_1 (by stride 2)

Implement
Training
training 데이터의 비디오에서 랜덤으로 train sample을 생성하여 데이터 augmentation을 수행합니다. 따라서 먼저 균일한 샘플링을 위해 각 샘플의 시간 위치를 선택합니다. 그 결과 16개의 프레임 클립이 생성됩니다. 만일 비디오가 16프레임보다 짧다면, 필요한 시간만큼 반복합니다. 그 후, 4 corner 혹은 1 center로부터 랜덤하게 spatial position을 선택합니다. spatial position 외에도, 멀티스케일 cropping 수행을 위한 각 샘플의 spatial scale도 선택합니다. scale은 다음 중 하나를 선택한다고 합니다: {1, \frac{1}{2^{1/4}}, {\frac{1}{\sqrt{2}}, \frac{1}{2^{3/4}}, \frac{1}{2}}}
Recognition
앞 장에서 설명한 방법으로 학습된 모델을 사용하여 비디오에서 action을 인식합니다.이 때 input 클립을 생성하기 위해 슬라이딩 윈도우 방식을 사용합니다 (즉, 각 비디오가 겹치지 않는 16개의 프레임 클립으로 분할됨). 각 클립은 최대 스케일로의 중심 위치로 잘립니다. 학습된 모델을 사용하여 각 클립의 확률을 추정하고, 비디오의 모든 클립에 걸쳐 평균을 구해 비디오에서의 동작을 인식합니다.
Experiment
데이터셋으로는 ActivityNet(v1.3)과 Kinerics dataset을 사용하였습니다.
Result
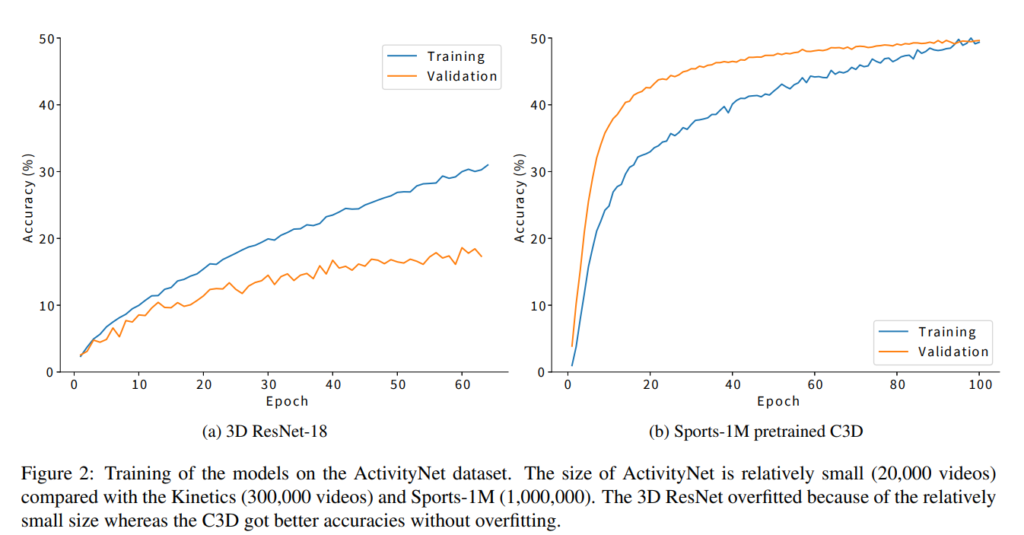
먼저 ActivityNet 데이터에 대한 preliminary 실험 결과를 보여줍니다. 그림 2는 ActicityNet에 대한 3D ResNet-18과 Sports-1M으로 사전학습된 C3D의 train과 validation의 accuracy를 보여줍니다. 이 때, accuracy는 전체 영상이 아닌 16개의 프레임 클립으로 계산합니다. 그림 2 (a)와 같이, 3D ResNet-18은 overfit 되기 때문에 validation accuracy가 train보다 상당히 낮습니다. 이는 ActicityNet 데이터셋이 너무 작아 3D ResNet을 처음부터 학습할 수 없음을 나타낸다고 논문에서는 주장합니다. 반면, 그림 2(b)는 사전학습된 C3D가 과적합되지 않고 정확도를 높인 것을 보입니다. C3D의 비교적 shallow한 구조와 사전학습 덕분에 overfit 되지 않았기 때문입니다.
다음으로는 Kinetic 데이터에 대한 실험 결과입니다. 이 때, Kinetic의 활동 instance의 수가 ActivityNet보다 훨씬 많기 때문에 ResNet-18 이 아닌 34로 학습했다고 합니다. 그림 3을 통해 앞에서 비교한 실험과 동일하게 C3D와 비교를 확인할 수 있는데, accuracy 역시 16개의 프레임 클립 결과로 계산됩니다. 그림 3(a)와 같이 3D ResNet-34는 overfitted 되지 않아 성능이 좋습니다. 게다가 그림 3(b)와 비교했을 때에도 사전 학습 없이 C3D와 경쟁력이 있음을 확인할 수 있습니다. 즉, Kinetics 데이터셋을 사용할 때, 3D ResNet이 효과적이라는 것을 보여준다고 합니다..
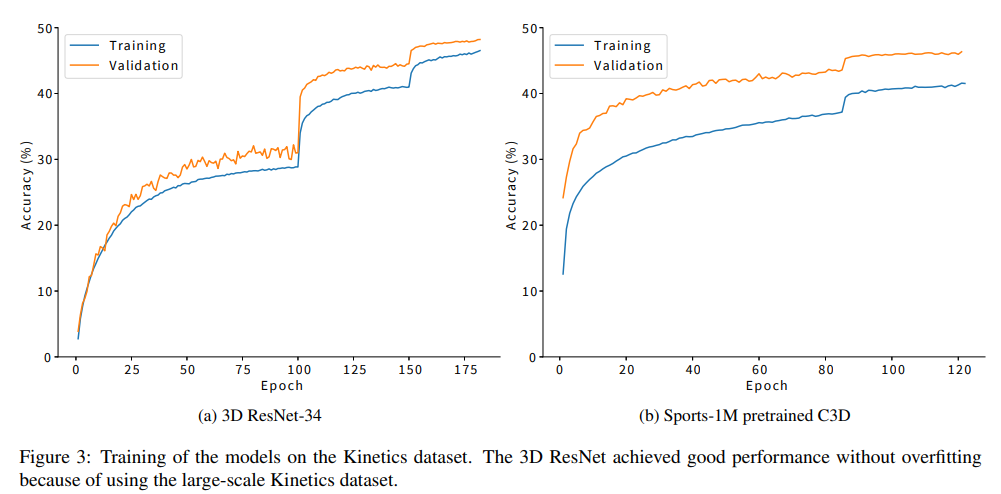
그런 다음 Kinetics 데이터 세트에 대한 실험을 보여 줍니다. 여기서는, Kinetics의 활동 인스턴스의 수가 ActivityNet의 것보다 훨씬 더 많기 때문에 18계층 1이 아닌 34계층 3D ResNet을 교육했습니다. 그림 3은 교육의 교육 및 검증 정확도를 보여줍니다. 정확도는 그림 2와 유사하게 16개의 프레임 클립을 인식하여 계산되었습니다. 그림 3(a)와 같이 3D ResNet-34는 오버핏되지 않아 우수한 성능을 달성했습니다. 또한 그림 3 (b)와 같이, 사전 교육된 스포츠-1M C3D는 우수한 검증 정확도를 달성했습니다. 그러나 교육 정확도는 검증 정확도(즉, C3D 미장착)보다 낮았습니다. 또한 3D ResNet은 Sports-1M 데이터셋에 대한 사전 교육 없이도 C3D에 비해 경쟁력이 있습니다. 이러한 결과는 C3D가 너무 얕고 Kinetics 데이터 세트를 사용할 때 3D ResNets가 효과적이라는 것을 나타냅니다.
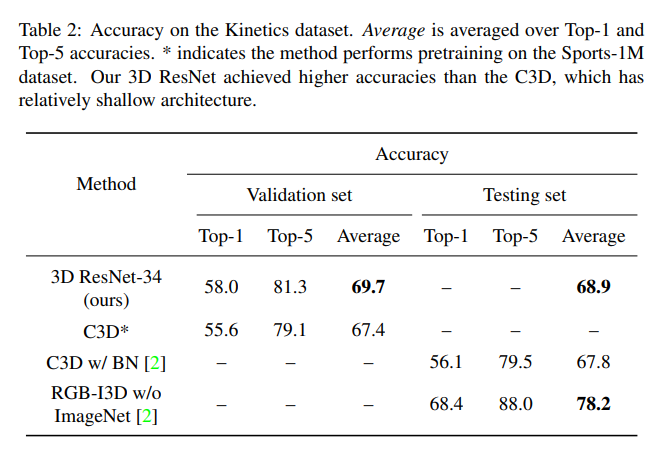
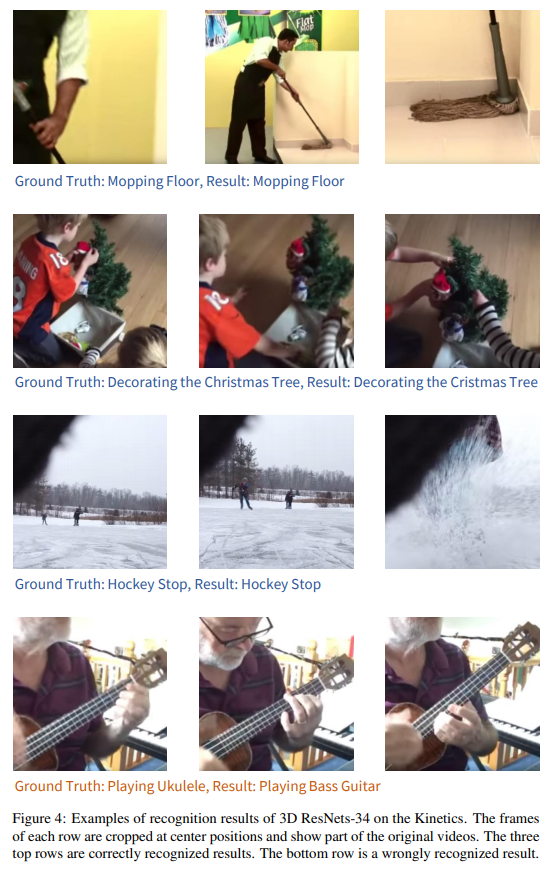
본 저자는 future work으로 더 깊은 ResNet 및 DenseNet 에 대한 추가 실험을 실시할 예정이라며 논문을 마칩니다.
음 .. 논문을 다 읽고 드는 생각은 … 너무 실험이 빈약하지 않은가 싶습니다. 왜 3D가 좋은지, overfit은 왜 발생하는지 친절하게 알려주면 좋을텐데.. 그리고 또 다른 실험들을 추가하여 이해를 도우면 좋을텐데… 하는 아쉬움이 남습니다.. 게다가 본 논문에서 비교하는 C3D는 kernel의 depth를 찾기 위한 여러 실험을 진행하곤 하는데, 여기서는 그런 것 없이 단순히 C3D와 비교만 하고 우리가 좋다라고 하니 조금 아쉬웠습니다.
네트워크는 기존의 ResNet model에서 kernel과 pooling만 3D로 바뀐 것이 맞나요? 다른 구조에서 변화된 점은 없는 건가요?