Before Review
이번 리뷰는 지난번에 황유진 연구원이 리뷰했던 TSP 입니다. (이번에 직접 TSP feature를 추출해야 하는 일이 있어서 스스로 꼼꼼히 파악하기 위해 같은 논문을 Review하게 됐습니다.)
본 Review를 본격적으로 진행하기 전에 trimmed Video , untrimmed Video가 무엇인지 잠깐 알아보고 가도록 하겠습니다.
- trimmed Video : Video에 ForeGround 영상만 존재하는 Video를 의미합니다. 즉 , action 부분을 담당하는 영상만 존재하게 되고 , action recognition 이런 곳에서 사용이 된다고 합니다.
- Untrimmed Video : Video에 ForeGround 영상과 BackGround 영상이 동시에 존재하는 Video를 의미합니다. 따라서 영상 속에 action 부분이 어디인지 판별하게 되는 Temporal Localization Task에 사용이 된다고 합니다.
[ForeGround]
[BackGround]

Introduction
비디오는 이미지와 다르게 용량이 매우 크다는 점 때문에 End to End 방식으로 Architecture를 설계하기 힘들다고 합니다.
그래서 , computation 제한 때문에 aggressive 한 spatial , temporal downsampling이 많이 사용하거나 , precomputed clip feature를 사용한다고 합니다.
본 논문에서 집중하는 부분도 precomputed clip feature를 개선하는 방향으로 진행이 됩니다. 좀 더 자세히 얘기해보면 untrimmed video의 large memory 특성 때문에 당시 video localization의 SOTA 방법론들은 사전에 계산된 video clip feature를 사용한다고 합니다. 하지만 이러한 feature들은 trimmed action classification task를 위해 훈련된 video encoder에서 추출되기 때문에 , Temporal localization task 에는 적합하지 않은다는 점이 존재합니다.
특히 , Trimmed Video로 훈련된 precomputed clip feature는 temporally insensitive 하다고 표현되는 데 무슨 말이 나면 , foreground segment와 background segment가 비슷하게 표현이 된다고 합니다. 본 연구에서는 action을 분류하는 것만 아니라 Temporal sensitivity를 개선하기 위해 Background clip과 Global video information을 같이 고려하는 새로운 clip feature를 제안하고 있습니다.
이렇게 제안된 새로운 clip feature는 Video의 Encoder의 구조 , dataset의 종류와 관계없이 성능을 향상했다고 합니다.
Technical Approach
Traditional Pretraining Strategies
untrimmed video 전체를 downsampling 없이 GPU에 장착하는 것은 불가능하기 때문에 일반적으로 Localization task는 video encoder에 바로 target taks를 조정하지 않는 것이 관행이라고 합니다.
대신에 pretrained 된 encoder를 fixed feature extractor로써 사용하게 됩니다. 이때 Trimmed action Classification(TAC)이 이러한 encoder들을 pretrain 시키는 전통적인 방법이라고 합니다. 하지만 TAC의 목표는 Localization task의 방향과 상황에 조금 맞지 않는다는 점이 있습니다.
무슨 얘기냐면 , TAC는 서로 다른 두 action에 대해서는 잘 구별할 수 있는 feature를 제공하는 반면 action instance 근방에 있는 background context에 대해서는 안 좋은 모습을 종종 보여주곤 합니다.
저자는 이러한 점이 Localization task에 있어서 문제가 되고 있고 , 후에 설명할 TSP feature는 이러한 ForeGround와 BackGround를 더 sharp 하게 구분할 수 있다고 표현하고 있습니다.
How to Incorporate Temporal Sensitivity
위에서 얘기했지만 결국 Trimmed action classification task로 학습된 encoder의 한계는 positive sample(foreground/action)들로만 학습이 진행된다는 점입니다.
직관적으로 , negative sample(background/no-action)들도 학습에 포함시키면 , encoder들의 temporal discriminative ability를 향상할 수 있을 것이라고 기대할 수 있습니다.
결국 untrimmed video가 제공됐을 때 localization task에 적합한 encoder는 서로 다른 action에 대해서도 잘 구분할 수 있을뿐더러 , action과 background context 역시 잘 구분할 수 있는 구조라고 볼 수 있습니다.
위의 내용을 직관적으로 봐도 현재 보고 있는 clip이 action clip인지 아닌지(ForeGround인지 BackGround인지) 우리가 알 수 있다면 Video에서 Action을 Localization 하는 데에도 도움이 될 수 있다는 것을 알 수 있습니다.
따라서 저자는 pretrain encoder 해야 하는 task를 다음과 같이 설정했습니다.
- Classifying the label of foreground clips -> 기존의 task처럼 action의 종류를 잘 구분하는 것
- classifying whether a clip is inside or outside the action -> 이제는 이 clip이 foreground인지 background인지 까지도 구분할 수 있도록
Temporally-Sensitivity Pretraining (TSP)
위에서 TAC로 뽑은 feature들의 문제점을 살펴봤고 , 이를 해결하기 위한 새로운 feature가 설계되어야 할 방향까지 살펴봤습니다. 이제는 본 저자가 제안하는 Temporally-Sensitivity Pretraining feature를 어떻게 추출하는지에 대해서 살펴보도록 하겠습니다.
- Input data
학습에 사용되는 input data의 형태에 대해서 먼저 살펴보도록 하겠습니다.
untrimmed video가 주어졌을 때 고정된 길이의 clip들로 분할하며 각 clip 들은 X = 3 * L * H * W 의 차원을 가지게 됩니다. (L = the number of frames)
그리고 X와 함께 두가지의 label 값을 전달해주게 되는 데
- y^c : 만약에 clip이 foreground segment라면 action class 라벨에 해당합니다.
- y^r : clip이 foreground인지 background인지에 대한 binary temporal region 라벨에 해당하며 foreground라면 1 , background라면 0 이렇게 할당이 됩니다.
- Local and global feature encoding
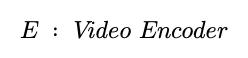
먼저 ,E는 clip X를 feature vector f로 변환해주는 Video Encoder입니다.(size = F)
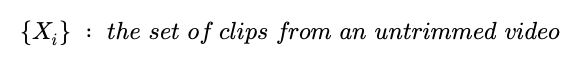
\{ X_{i}\} 는 untrimmed video 내부에 존재하는 video clip들의 집합을 의미합니다.
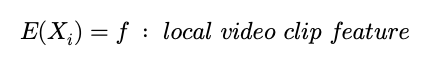
그래서 clip에 대해서 Encoder를 태워주면 , clip에 대한 feature 즉 , 비디오 입장에서는 local feature를 얻어낼 수 있습니다.
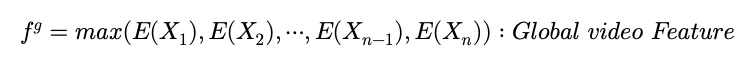
그리고 Global Video Feature(GVF)를 구해주게 되는 데 구해주는 이유는 다음과 같다고 합니다.
Local Clip 정보만을 가지고 , 이 Clip이 ForeGround인지 BackGround인지 구분하는 것이 아니라 전체적인 비디오의 이해를 바탕으로 이를 수행한다고 합니다. 따라서 모든 Clip에 대해서 local feature 들을 구해주게 되고 pooling 연산을 거쳐서 Global 한 Video Feature를 얻어낸다고 합니다. 이 pooling 연산은 max pooling으로 수행되고 있습니다.
아래의 그림을 보면 이해에 도움이 되실 겁니다.
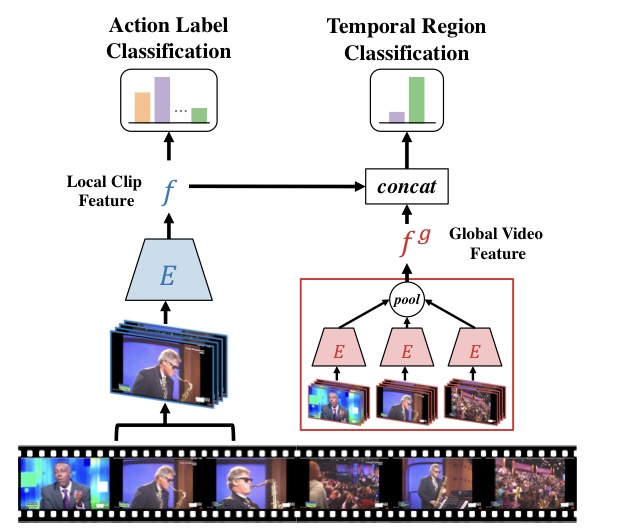
Clip에 대해서 Encoder를 태워주고 Local feature를 얻습니다.
이를 사용해서 Action label classification 즉 , 이 action이 어떤 종류의 action인지 판단하게 되고
비디오 전체에 대해서 각각의 Clip에 대한 local feature들을 모두 구해주고 , pooling 연산을 통해서 얻어낸 Global Video Feature와 현재 해당하는 Clip에 대한 Local Feature를 Concat 해서 (concat 했으니 사이즈는 2*F) 이를 가지고 Temporal Region Classification을 수행하게 됩니다.
즉 , ForeGround인지 아닌지를 Concat 된 vector를 가지고 진행한다는 이야기입니다.
- Two classification heads
같은 얘기를 반복해서 하지만 , 두 가지의 classification이 진행되고 각각이 어떤 task인지는 앞에서 살펴봤습니다. 각각의 classification은 FC layer를 거쳐서 최종 결과가 나오게 되는 데
- W^{c} : transforms the local features f to an action label logits vector \hat{y}^{c} (size : F x C , C : num of action classes in the dataset)
- W^{r} : transforms the Global Video feature f^{g} to an temporal region logits vector \hat{y}^{r} (size : 2F x C , C : num of action classes in the dataset)
- Loss
clip이 ForeGround와 BackGround일 때 두 가지 상황으로 나눌 수 있는 데
ForeGround라면 두 가지의 classification loss에 대한 합으로 구해주고 있으며 각각의 Loss는 CrossEntropy를 사용한다고 합니다.
BackGround라면 temporal region classification에 대한 loss만 계산해주고 있는 것을 확인할 수 있습니다.
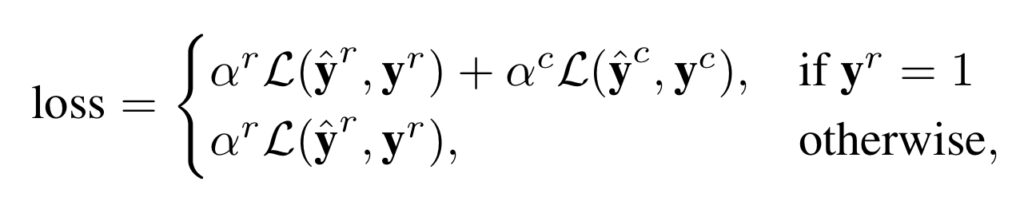
특별히 어려운 점은 없고 , 두 가지의 상황으로 나뉜다는 것만 파악하시면 될 것 같습니다.
Experiments
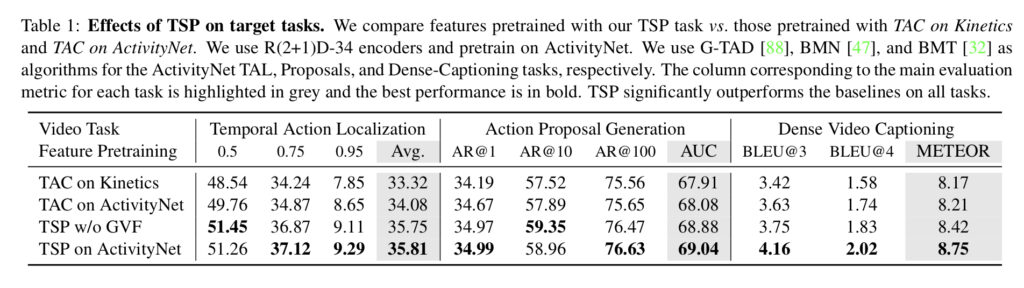
우선 각 Task 별 , TSP의 성능을 살펴보도록 하겠습니다.
Temporal Action Localization , Action Proposal Generation , Dense Video Captioning에 대한 성능들이 나와있고 , 각 Task에 대해서는 TAC와 TSP 같의 성능 차이를 확인할 수 있습니다.
본 저자가 얘기했던 대로 , 세 가지 Task에서 모두 성능이 조금 향상한 것을 확인할 수 있습니다.
추가적으로 언급하는 것은 성능 향상의 원인을 따져보면 결국 Temporal Region classification에서 온 것이라고 합니다. ForeGround와 BackGround를 구분해주는 것이 좋게 작용했나 봅니다.
서로 다른 Video encoder에 대해서도 비교를 한 Table입니다.
Temporal Localization Task에 대한 벤치마크이며 , TAC와 TSP의 성능을 비교하고 있습니다. 모든 Video Encoder에서 TSP가 평균적으로 더 높은 성능을 보여주는 것을 확인할 수 있습니다.
이러한 점은 다른 , 다양한 Encoder에서도 TSP를 적용하면 성능이 올라갈 수 있다는 점을 시사한다고 저자는 얘기합니다.
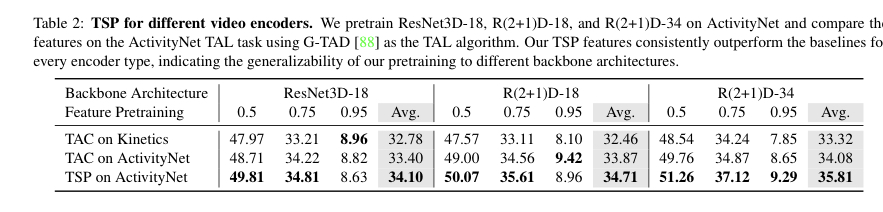
결국에 TSP를 적용하면 , Video Encoder를 다르게 하거나 , 다양한 Task에서도 모두 향상된 성능을 얻을 수 있다는 점을 확인할 수 있었습니다.
Video 관련 리뷰는 아직 아는 게 많이 없어서 내용을 서술할 때 부족한 점이 많았을 것이라고 예상이 됩니다.
최대한 자세하게 서술을 했지만 , 이해가 안 가는 점이나 , 내용상 잘못된 것 같다고 느끼는 부분은 댓글로 피드백 주시면 감사하겠습니다.