해당 논문은 이미지 기반 unsupervised 방법론 모델을 통해 video에 대한 representation learning 실험을 진행한다.
이미지 기반 방법론은 SimCLR, MoCo, BYOL, SwAV를 이용한다. 이미지기반 unsupervised 방법론들은 하나의 이미지 A에 대해 Augmentation을 진행하여 positive pair를 생성하여 pair를 기반으로한 contrastive learning (군집내 유사도 최대화, 군집 간 유사도 최소화)를 진행하는데, 이러한 특징이 비디오를 일반화 시킬 수 있다고 보는것이다.
해당 논문을 제외하고도, video의 연관된 frame을 positive pair로 이용하고자 하는 연구는 많다. 이미지기반의 unsupervised 연구는 positive pair를 생성하기 위해 resize&crop, 컬러값 조정 등과 같은 변형을 하는데 (spatio 변형에 가까운 듯 하다) video의 각 프레임도 각도나 시간등의 차이를 둔 (temporal 변형) 변형으로 볼 수 있기 때문이다. 해당 논문에서는 이미지 변형을 artificial augmentation이라 하였고, video가 제공하는 변형들을 natural augmentation이라 언급하였다.
어쨌든 memory 기반 등을 이용하여 long-term 을 표현하는 것이나, 각 프레임들을 하나의 정보가 augmentation 된것으로 보는 것이나 video의 더 많은 프레임을 하나의 feature로 표현할 수 있다는 점에서 video level feature로 발전하려는 듯 하다. 해당 논문은 SlowFast 의 저자와 동일 저자의 논문이다. 해당 연구의 목적은 기존 이미지 기반 unsupervised 방법이 진행하던 crop image의 일반화를 비디오로 확장하여 video clip feature를 일반화하는 것이라고 한다.
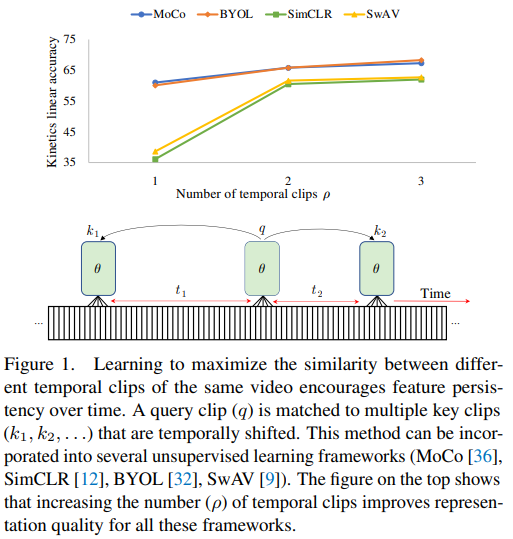
선정한 4가지 모델의 특성은 다음과 같다.
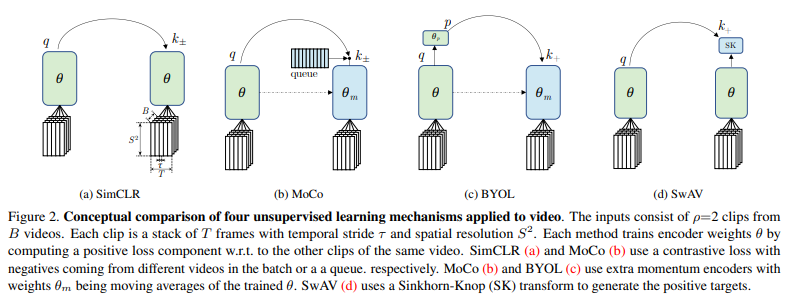
negative pair 사용 (군집 간 유사도 최소)유무
– contrastive approch (positive pair, negtive pair 사용)
– SimCLR, MoCo
– uncontrastive approch (positive pair 만 사용)
– BYOL, SwAV
실험에 사용한 encoder(video clip to feature)는 다음과 같다.
SlowFast network의 Slow only path와 같으며 3D ResNet-50 구조를 갖는다. 모델의 입력은 video clip인 3XTXS^2 이며(T: 시간, S: 프레임의 가로 세로) , B영상으로 구성된 minibatch에 대해 ρ 개의 clip을 생성하는데, 학습 방식은 위의 Figure1에 들어난것처럼, 같은 영상에서 생성된 B*ρ개의 positive pair들이 유사도가 높도록 각각의 방식을 통해 학습 하는것이다.
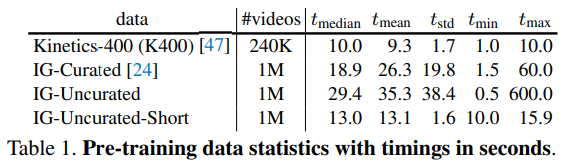
논문은 위와 같은 학습 방식으로 embedding 한 feature 들을 여러가지 다운스트림 (활용단의) 실험을 통해 유효성과 특징을 분석하였다. 데이터셋으로는 Kinetics-400 (K400), IG-Curated, IG-Uncurated, IG-Uncurated-Short를 사용하였다고 한다. “in-the-wild” 실험을 위해 Instagram video인 IG-??? 를 사용하였다고 한다.
- 시간적으로 지속성이 큰 (대표성이 큰) feature 학습방식 분석
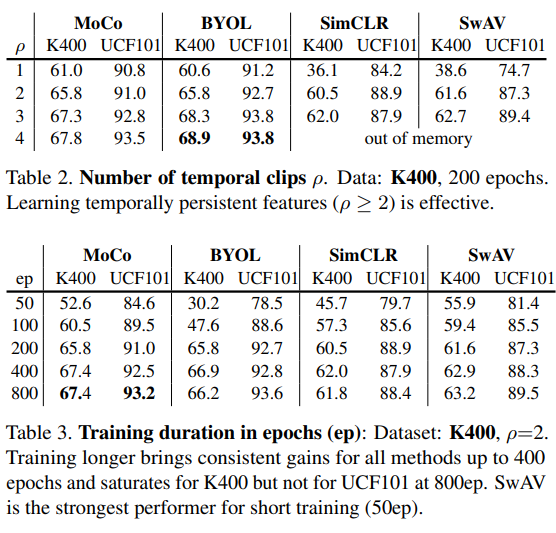
Tabel 2) 200epoch를 학습한 K400을 이용하여 temporal clip 갯수에 따라 성능을 측정한 실험으로 clip의 갯수가 많을수록 성능이 높아지는 경향이 있으며, 특히 SimCLR과 SwAV 의 성능 변화가 드라마틱하다. negative pair를 사용하는 SimCLR, MoCo와 positive pair만 사용하는 SwAV, BYOL의 성능 경향성이 서로 같지 않으니, negative pair가 feature 표현력에 거의 영향을 미치지 않음이 확인되었다. 즉 across video 를 통해 학습하는것이 별로 도움이 되지 않는다는 뜻이다.
Tabel3) Table 3의 실험은 K400에서 clip 갮수가 증가하는 것이 training cost가 크니 같은 epoch (tabel2의 200 epoch)로 실험을 비교하는것이 합당한지 알아보기 위해 epoch를 변화하며 실험한 결과이다. 확실히 오래 학습할 수 록 성능 향상이 있음을 확인할 수 있다. 이정도를 감안하고 보면 table2의 clip 갯수 증가에 따른 성능향상을 보정하고 볼 수 있을 것이다.
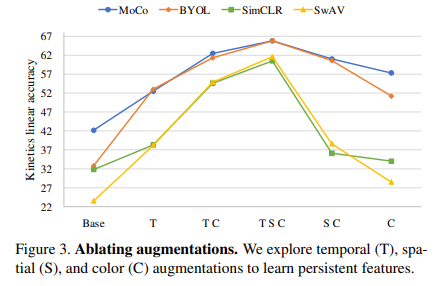
ablation study로 다양한 augmentation 방법을 논문해서 진행하였는데 (T: 시간/ S: 공간, 이미지 crop / C: 색, grayscale etc.) 해당 실험에서도 MoCo와 BYOL 방법론이 변화에 robust함을 알 수 있다.