안녕하세요 이번 주 리뷰에서는 멀티스펙트럴 기반 보행자 인식의 기초가 되는 논문을 소개 하겠습니다. 몇몇의 연구원 분들은 친숙한 논문일텐데요. X-review를 찾아보니 아직 리뷰를 하신분이 없더라구요. 이번에 여름방학동안에 하게될 프로젝트의 일환으로 해당논문을 비롯한 멀티스펙트럴 보행자 인식 논문들을 읽게되었는데, 그중에 가장 먼저 읽었던 논문이기도해서 이렇게 리뷰를 하게 되었습니다.
음 먼저 기술적인 분석에 앞서서 논문의 배경을 좀 설명을 드리겠습니다. 해당 논문은 미국에 있는 Rutgers University에서 진행한 연구이며 보행자인식 분야에서 최초로 멀티스펙트럴(적외선 + 가시광선)을 동시에 사용하였습니다. 그전까지는 적외선, 가시광선 따로 적용하는 경우가 있긴했어도 이렇게 동시에 적용한 것은 최초라고 합니다. 지금 생각하면 정말 당연한 시도인데, 2016년에 최초로 해당 연구를 하였다는걸로 미루어보아 멀티스펙트럴 기반 보행자인식의 역사가 오래되지 않았음을 체감할 수 있네요.
인공지능이란 분야의 특성상 1~2년만 지나도 최신기술동향에 뒤쳐지는 경우가 참 많은데요. 해당 논문은 무려 5년이란 시간이 지났습니다. 그럼에도 최초로 시도했단데에 의의가있고 아키텍쳐 구조가 비교적 단순하여 학습하는데 도움이 많이 되는거 같습니다. 코드를 따로 공개를 하고 있진 않지만, 기존 Faster-RCNN코드를 바꾸면 되서 원복실험을 해보면 의의가 있을거 같습니다. 해당 논문을 읽은 목적도 이번에 하계 논문작업의 일환인 카이스트 데이터셋을 인용한 논문들중 핵심논문들의 성능을 리포팅하고 리더보드를 만드는데 필요했기 때문입니다. 이번에 X-review에서는 해당 논문을 정독하고 요약한다음, 이제 조만간 하게될 실험 중 해당논문의 원복실험 및 어노테이션 및 평가지표를 통일한 fair comparison기반의 리더보드 생성 작업에 참고할 생각입니다.

해당페이퍼에서는 기존에 시도하지 않았던 적외선, 가시광선 영상을 DNN기반으로 퓨전하는 기법에대한 연구를 하고 성능을 비교합니다. 기존에는 퓨전을하여 detection을 하는 연구가 아예 없었다는점에서 해당 논문의 contribution을 인정받습니다.
해당 논문에서는 해당 시기에서 좋은 성능을 보이던 Faster-RCNN을 기반으로 ConvNet이라는 간단한 네트워크를 구성하고, 해당 네트워크에서 적외선과 가시광선영역의 이미지를 퓨전하는 방법을 달리함에 따라서 성능을 비교합니다.
핵심 컨트리뷰션은 4개로 아래와 같습니다.
- Faster-RCNN 기반으로 만든 convolutional stages, fully-connected stages, decision stage로 구성된 ConvNet에서 퓨전되는 방법을 low-level, middle-level, high-level, confidence-level로 세분화하고 카이스트셋에서 기존 베이스라인을 넘김
- Middle-level fusion(Halfway fusion)을 기반으로 두개의 모달리티를 퓨전했을때 가장 높은 성능을 보임을 실험적으로 증명함
- 기존 Faster-RCNN 베이스라인보다 miss-rate가 11% 더 낮게 나왔음
- Caltech PD 셋에서 SOTA이며, Faster-RCNN을 PD분야에 사용한건 처음으로 간주됨
이렇게 논문에서 총 4개로 주장하는데, 사실 핵심 컨트리뷰션은 fusion 기법에 대한 연구라고 생각을 합니다. 이번에 저희가 IEEE RA-L 저널에 IROS 옵션으로 제출한 논문도 해당 fusion기법에 대한 연구를 참고하였습니다.
Vanilla ConvNet
먼저 해당논문에서는 Faster-RCNN을 기반으로 ConvNet을 구성하였습니다. Faster-RCNN은 대표적인 two-stage기반의 방법론중 한개라 아마 다들 잘 아실텐데요. 저는 아직까지 가져다 쓰는 논문을 보긴 했어도 아키텍쳐를 제대로 공부해본적이 없었어서 이번기회에 좀 자세히 살펴보았습니다.
![갈아먹는 Object Detection [4] Faster R-CNN](https://blog.kakaocdn.net/dn/bUjRYz/btqAWb0p8cv/dx8Ky33sdZtb2RKQ8sQxZK/img.png)
간단하게 설명하자면, 위의 그림처럼 원본이미지로부터 conv layers를 태워 feature maps을 뽑고, 해당 피쳐맵을 Region Proposal Network에 태워 각각의 픽셀마다 사전에 정의한 bbox에 object가 있는지 없는지 여부를 IoU기준으로 판단합니다. 사전에 정의해둔 prior box의 aspect ratio(3개), multi-scale(3개) 등을 이용하여 각 픽셀을 중심으로 9개의 box를 치고, 해당 박스들중에 IoU가 일정 임계치를 넘어서 물체가 있는걸로 판단되는 경우에는 True positive(TP) 박스로 분류하고, 물체가 없는 경우에는 False Positive로 분류를 하여 물체가있는 TP만을 region proposal합니다. 즉 해당 TP 박스만을 Region of Interest(RoI)로 사용합니다. 이 때, 해당 RoI는 원본이미지에서의 RoI이기 때문에 feature map사이즈에 맞춰 resize된 후 RoI풀링을 통해 fixed size로 뽑아냅니다. 이렇게 fixed size로 뽑아냄으로써, arbitrary한 보행자의 크기를 다룹니다.
사실상 Faster-RCNN은 기존 Fast-RCNN과 크게 다르지 않고, RPN만 추가되었다고 생각하셔도 됩니다. 이 때, RPN에서 각각의 box가 어떠한 class에 속하는지 multi-class로 classification하는 것이 아닌 물체가 있는지 여부만을 binary하게 학습함으로써 학습속도를 키웠다고 합니다. 300개의 proposal을 뽑아내는데 약 0.3초밖에 걸리지 않는다고 하네요.
아무튼 본론으로 돌아와서 해당논문에서는 이러한 Faster-RCNN구조를 기반으로 ConvNet을 설계하였습니다. 기존 Faster-RCNN에서 기존 앞단 VGG-14모델의 앞부분 4번째 pooling layer를 제거하였다고 합니다. 이유는 small object를 다루기 위함인데요. 풀링레이어가 제거됨으로써, 피쳐맵의 크기가 커지고, small object를 다루는데 이점이 있다고 하는데 trade-off관계에 있다고 생각이 되어지는데 아마도 실험을통해 최적점을 찾은거 같네요.
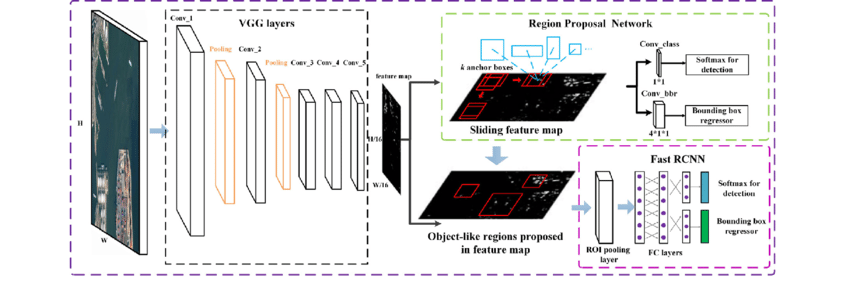
위의 그림은 Faster-RCNN 논문에 있는 사진은 아니고, 구글링해서 찾은 아키텍쳐 모습입니다. 원본임에도 해상도가 좋지 못한점 양해 부탁드립니다. 해당 그림이 이해하기 쉽게 나와있어서 가지고 왔는데, 위의 그림에 나와있는 VGG layers에서 4번째 pooling layer를 삭제하고 사용한 것을 하였습니다. 이외에도 아키텍쳐적인 변화가 아닌 하이퍼파라미터, finetuning, 한 방법 등에 대한 명시가 페이퍼에 나와있습니다. 이렇게 만든 vanilla ConvNet을 베이스로 multispectral 퓨전 연구를 진행을 하는데 아래서 설명하겠습니다.
Multispectral Fusion Study
이번에는 이제 해당 논문에서 핵심인 multispectral fusion 방법에 대해서 논의해보겠습니다.
위에서 설명했던것 처럼 해당 논문에서는 Faster-RCNN 기반으로 만든 convolutional stages, fully-connected stages, decision stage로 구성된 ConvNet에서 퓨전되는 방법을 low-level, middle-level, high-level, confidence-level로 세분화하고 카이스트셋에서 실험을 진행하였습니다. 그리고 각각의 퓨전기법들이 성능에 어떠한 변화를 주는지에 대해서 확인해보았습니다. 위에서 ConvNet이 어떤식으로 구성되었는지 설명을 드렸고, 이제 그 ConvNet을 어떤식으로 활용하여 퓨전을 하였는지 그 방법들에 대해서 좀 더 자세히 알아보겠습니다.
그 전에 저자가 말하는 2가지 질문에 대해서 생각해봅시다.
- When strong ConvNet based detectors are involved, does color and thermal images still provide complementary
information? - To what extend the improvement should be expected by fusing them together?
퓨전연구를 함에 있어서 직관적인 질문들이며 이에 대한 답변을 하기위한 실험이 페이퍼에 주된 내용입니다.
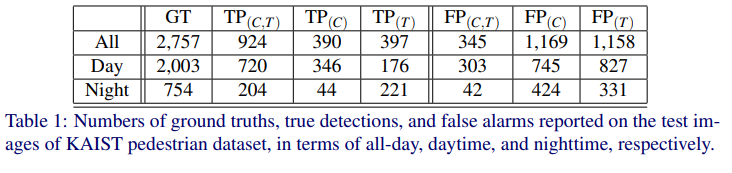
먼저, 해당 논문에서는 위에서 설명했던 ConvNet을 기반으로 각각의 도메인에서 학습하고 비교실험을 합니다. 위의 표에서 TP, FP는 True positive, False positive를 각각 의미하고, C, T는 각각 color와 Thermal을 의미합니다. 또한 카이스트 데이터셋의 특성을 살려 All, Day, Night scene에 대해서 세분화하여 성능을 평가했습니다. 해당 실험의 의의는 과연 color영상과 thermal영상이 상호보완적인 관계를 가지는가에 대해 알아보기 위한 실험입니다.
해당 결과로서, night타임에는 조도가 충분히 확보되지않아 color영상이 더 불리하고, 낮에는 태양광이 노이즈로 작용하여 thermal영상이 더 불리함을 유추할 수 있습니다. 그래서 두개의 채널을 퓨전하여 사용하면 FP를 줄이는 효과가 나올 잠재적인 가능성이 있음을 주장합니다. 지금에서는 당연한 논리지만, 해당시기에는 그 직관적인 논리를 실험으로써 입증해야 하였음을 알 수 있습니다.
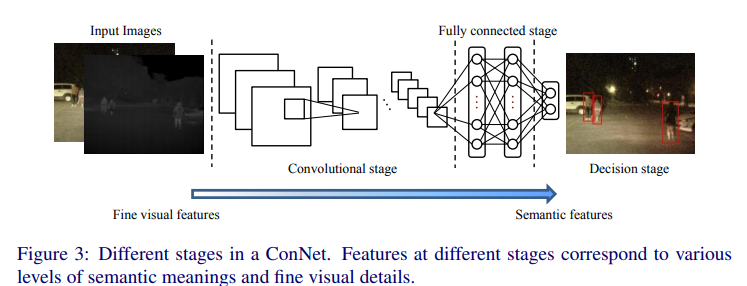
Faster-RCNN 기반으로 만든 ConvNet은 위와 같이 convolutional stages, fully-connected stages, decision stage로 구성되어있고, 뒤로갈수록 semantic한 피쳐를 다루고, 앞에서는 visual feature를 다룬다고 언급합니다.
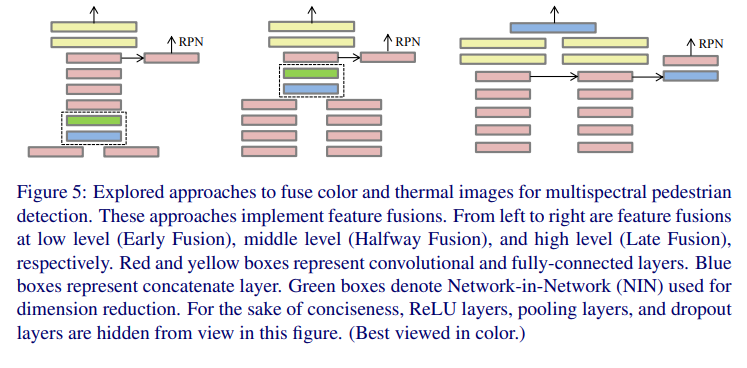
또한 논문에서는 위의 그림처럼 fusion이 일어나는 feature level에 따라서 Early Fusion, Halfway Fusion, Later Fusion으로 명칭하고 있습니다. 그냥 일반적으로 2개의 독립적인 ConvNet을 사용하는것보다 이렇게 퓨전을 이용하여 사용하는 것이 더 좋은가? 더 좋다면 어떠한 방법으로 퓨전을 하는것이 제일 좋은가를 알아보기 위한 실험설계입니다.
먼저 Early Fusion부터 살펴보면 첫번째 conv layer뒤에 바로 두개의 모달리티를 fusion하는 것을 볼수가 있습니다. 이때, fusion을 concatenate 하는 방식으로 합쳐지고, 합쳐진 feature는 Network-in-Network(NIN)을 사용하여 128차원으로 줄입니다. 이때, NIN은 1*1 conv layer를 주로 사용한다고 논문에 명시되어있는데 1×1 이 아닌 경우도 있는지는 잘 모르겠습니다.
다음으로 Halfway Fusion에서는 위에 Early Fusion과 매우 흡사하며, 한가지 차이점이라고는 Conv4레이어 이후에 Fusion을 진행하는 것을 알 수 있습니다. 그 이후 concatenate, NIN과정은 동일하게 진행됩니다.
Late Fusion에서는 high level feature를 사용합니다. 즉, 7번째 레이어인 FC레이어를 이후로 동일과정을 반복합니다. 아키텍쳐에서 보여지듯이 각각의 브랜치는 동일한 RPN에 태워져서 RoI를 찾습니다.
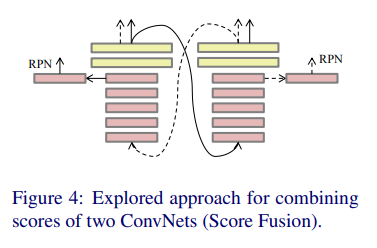
또한 마지막으로 score fusion의 경우 위의 그림과 같이 cascade 구조를 가지고있는데, 먼저 color 이미지로부터 detection을 한다음 해당값이 thermal쪽 ConvNet으로 전달되어지고, 마지막에 나온 score 까지 총 2개의 detection score를 같은 weight로 merge하여 최종 prediction값을 얻습니다.
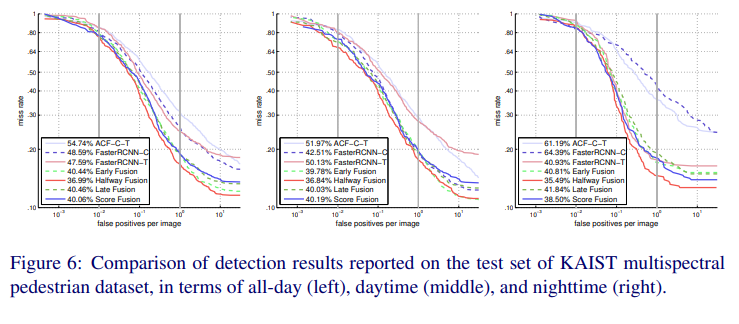
그렇게 해서 나온 결과 입니다. FPPI 10^-2 ~ 10^0 구간에 대한 miss rate의 평균을 고려할때, Halfway Fusion 방식이 카이스트 데이터셋의 All, day, night 모두에서 가장 좋은 성능을 보였습니다.
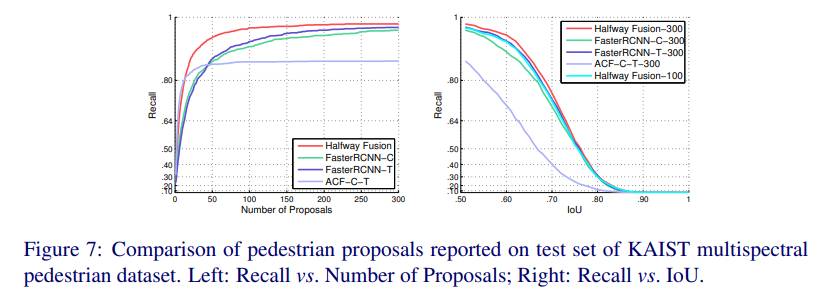
그래프를 보시면 알 수 있듯 Halfway Fusion이 더 작은 proposal에서 더 높은 Recall을 달성했음을 알 수 있습니다.
오른쪽 그래프를 보시면 300개의 proposal이 있을때 IoU 0.6에서 93%정도의 Recall을 보입니다. 또한, proposal이 100개 있을때의 recall을 비교해봐도 다른 모델들과 비슷한수준의 Recall을 보이는 것을 알 수 있습니다.
이러한 지표들을 근거로 Middle-level feature에서 feature map을 cancatenate해주는 Halfway Fusion 방식이 가장 좋은 성능을 보임을 보였습니다.

정성적 결과입니다.
개인적으로 컨셉은 쉬운편이라고 생각이드는데 과연 원복할때 쉬울지는 해봐야 알거 같네요.
리뷰 잘 읽었습니다.
score fusion 부분이 잘 이해가 안되어 질문 드립니다.
“먼저 color 이미지로부터 detection을 한다음 해당값이 thermal쪽 ConvNet으로 전달되어지고”
이 부분에서 detection을 한 다음 해당 값이라고 하면 RoI pooling이 진행된 feature map을 thermal ConvNet이 다시 연산한다고 이해하면 될까요??
color와 thermal끼리 서로 주고 받고 주고 받고 하는 형태인 것 같은데 맞나요?
좋은 리뷰 감사합니다.
modality fusion에 관련해서 질문이 있습니다.
본 논문에서 소개된 fusion 방법론들이 최근까지도 사용이되는 방법론들인가요? 또한 보통 fusion 방법론들을 연구할때는 이론적인 접근을 통해 설계하는 편인가요? 아니면 실험적인 접근을 통해 설계하는 편인가요?