

오늘 리뷰할 논문은 2021년 4월 arXiv에 올라온 “Self-supervised Video Retrieval Transformer Network”라는 논문으로 줄여서 SVRTN이라고 불립니다. Alibaba에서 나온 논문으로 2019년부터 FIVR-200K 데이터 셋에서 SOTA를 달성해온 ViSiL을 제치고 새로운 SOTA를 달성하였습니다. 특이하게 해당 논문은 Self-supervised Learning 방식과 frame-level feature를 clip-level feature로 aggregation하는 방식을 사용하여 좋은 성능을 보였으며, 이에 Binarization까지 적용했다고 합니다. 자세한 내용은 아래서 설명드리겠습니다.
1. Method
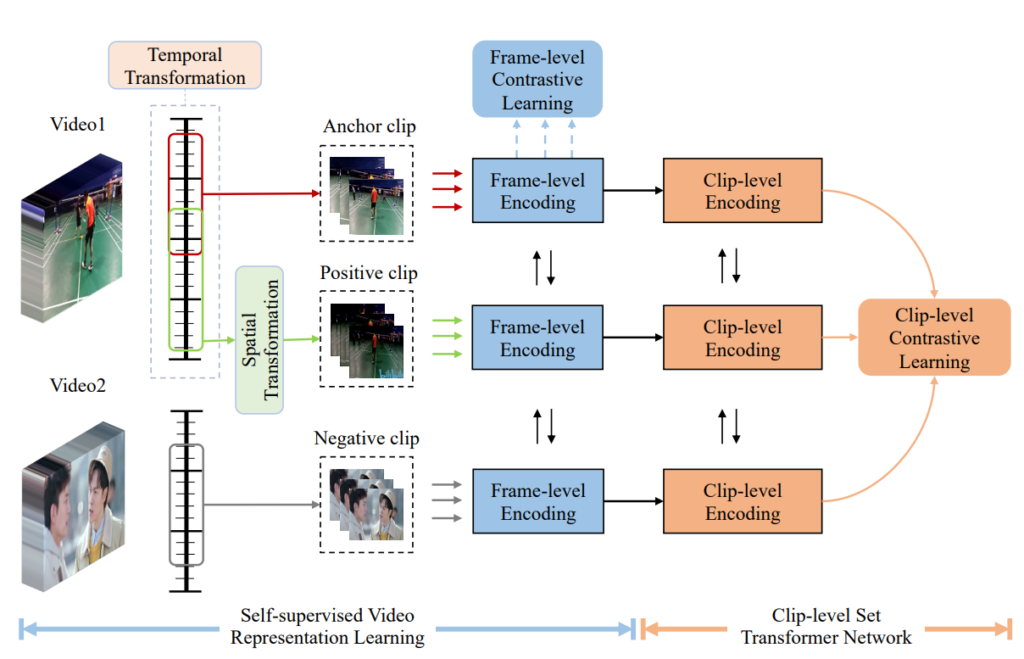
1.1 Self-supervised Video Representation Learning
최근 비디오 관련 분야에서 좋은 feature representation을 하기 위해서는 많은 양의 비디오 데이터가 필요로 합니다. 그러나 이 과정을 모두 Supervised Learning 방식으로 하기 위해서는 모든 비디오에 라벨링이 되어있어야하고 이는 매우 비용이 큽니다. 본 논문에서는 이를 해결하고자 라벨링이 필요없는 Self-supervised Learning 방식을 도입하였습니다.
- Self-generation of Training Data
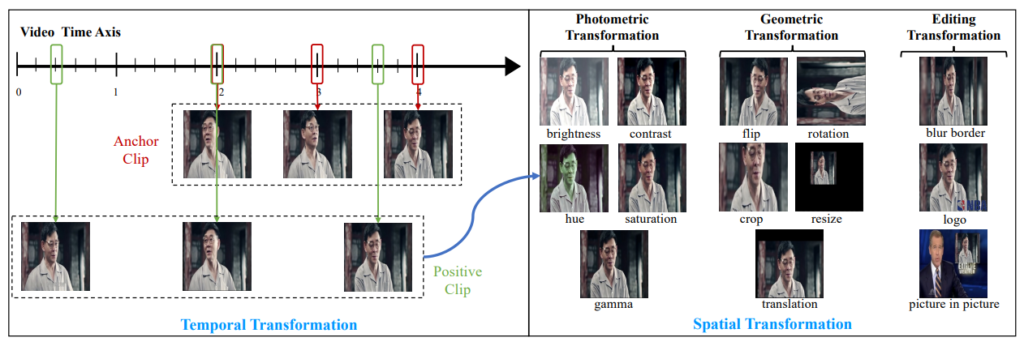
Self-supervised Learning 방식으로 학습을 하기 위해 많은 양의 비디오를 웹사이트에서 모은 후 Temporal Transformation과 Spatial Transformation을 적용하였습니다.(모은 비디오에 대한 정보는 https://www.youku.com/에서 다운 받은 3000시간의 비디오라는 것을 제외하면 따로 나와 있지는 않습니다.)
우선 positive clip에 속하는 프레임을 선별하기 위해 Temporal Transformation이 적용되었습니다. 한 비디오에서 interval r로 uniform하게 N개의 프레임을 추출하고 이를 anchor clip으로 설정하였으며, positive clip을 만들기 위해 anchor clip에서 임의로 한 프레임을 선정하여 positive clip의 중간 프레임으로 선정하였습니다. 그리고 중간 프레임 기준 앞뒤로 interval r_{+}의 uniform한 (N-1)/2 개의 프레임을 선택하여 positive clip을 생성하였습니다.
Positive clip이 생성된 이후 Spatial Transformation이 적용되었습니다. Spatial Transformation의 종류로는 크게 Photometric Transformation, Geometric Transformation, Editing Transformation이 존재하며 세부적인 Transformation은 Fig 3에서 확인하실 수 있습니다.
- Video Representation Learning
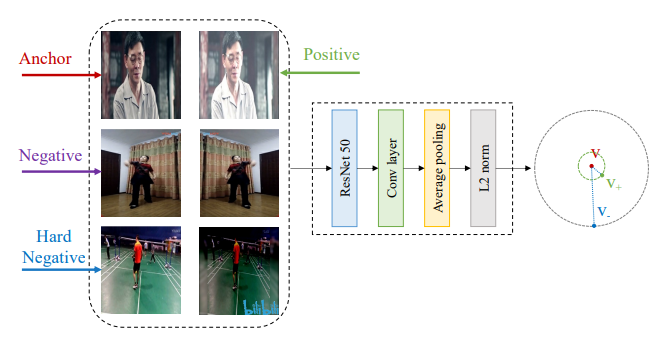
앞선 방식으로 pair를 선정한 뒤 frame-level feature로 먼저 학습시킵니다. 참고로 Fig 2와 Fig 4에서 나온 negative clip의 경우 따로 설명이 없으나 anchor clip이 속한 비디오와 다른 비디오에서 얻어진 것으로 추측되며 hard negative clip의 경우도 따로 설명이 없습니다.
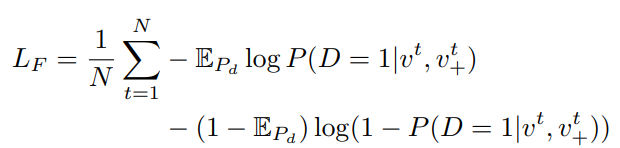
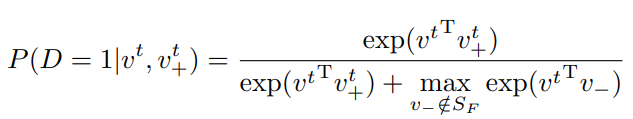
각 clip에서 프레임 단위로 ResNet50-Conv layer-Avg Pool-L2 norm 의 구조를 가진 간단한 모델을 통해 frame-level의 feature을 추출합니다. Anchor clip에 속한 N 프레임의 feature는 v^{t}(t=1부터 N)이고 positive clip에 속한 N프레임의 feature는 {v_{+}}^{t}(t=1부터 N) 일 때 식 (1)과 같은 noise constrastive estimation loss로 학습이 진행되었습니다. 여기서 P_{d}는 실제 데이터의 분포(라고만 나와있습니다) 이며, E_{P_{d}}=1 는 anchor clip과 positive clip에 속한 프레임들이 서로 동일하다는 것을 의미합니다. 또한 S_{F} 는 anchor clip에 속한 frame-level feature와 positive clip에 속한 frame-level feature의 집합을 의미합니다.
1.2 Clip-level Set Transformer Network
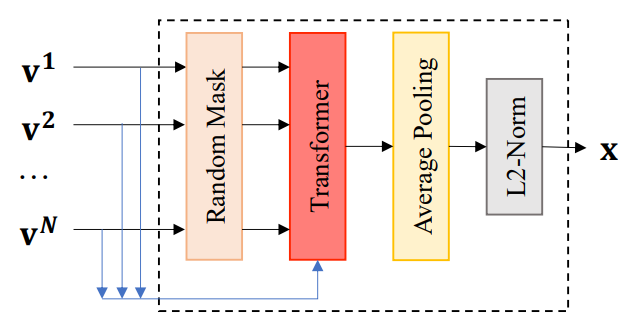
앞서 학습한 frame-level feature에서 프레임 간의 상호보완적인 정보를 찾아내고자 frame-level feature를 clip-level feature로 aggregate 합니다. Aggregate할 때, Fig 5와 같은 clip-level set transformer network를 거쳤다고 합니다. 여기의 Transformer 구조에서는 https://arxiv.org/pdf/2003.11794.pdf 이 논문의 set retireval의 아이디어를 적용하였다고 하며 8개의 attention head로 구성된 하나의 encoder layer를 사용하고 positional embedding은 사용하지 않았다고 합니다.
- Clip-level Encoding
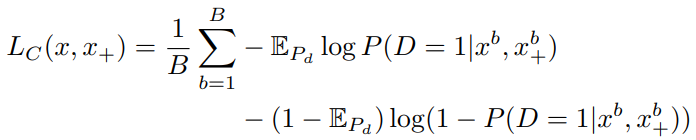
한 배치 내의 B 개의 clip 중 anchor clip의 clip-level feature를 x^{b}(b=1부터 B), positive clip의 clip-level feature를 {x_{+}}^{b}(b=1부터 B) 라고 했을 때 식 (1)과 유사한 식 (2)의 Loss function으로 clip-level contrastive learning이 진행되었습니다. 이러한 Loss function으로 Transformer 구조의 모델을 학습시켜 clip내의 프레임 간 상호보완적인 정보를 학습시킨다고 합니다.
- Clip-level Encoding with Masked Frame Modeling
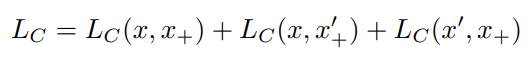
앞선 학습 방식에 더불어 좀더 강인함을 clip-level feature에 추가하고자 Ramdom mask 방식이 적용되었습니다. 주어진 clip에서 임의로 프레임을 제거하여 프레임 블러 현상이나 clip cut 현상을 막고자 하였으며, Random mask가 적용된 anchor clip의 clip-level feature를 x', positive clip의 clip-level feature를 x_{+}'라고 했을 때 식 (3)과 같은 최종 Loss function이 설계되었습니다.
1.3 Video Similarity Calculation
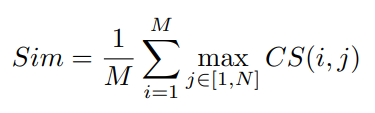
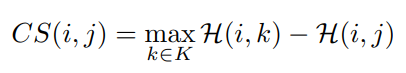
앞서 설명한 모델 구조 이전 비디오 별로 shot boundary detection을 통해 segment를 나눴으며 segment를 나눠 clip을 생성하였다고 합니다.(다른 설명은 없습니다.) 이후 제안된 모델을 통해 clip-level feature를 생성한 후 IsoHash라는 다른 논문에서 제안한 방식으로 binarization을 하였다고 합니다. 이후 식 (4)를 통해 retrieval이 진행되었으며 H는 Hamming distance를 의미하고 M은 한 query 비디오 내의 clip, N은 database에 속하는 한 비디오 내의 clip, K는 모든 clip(나와있지는 않지만 아마 MxN 을 의미하는 듯 합니다.)을 의미합니다.
2. Experiments
dataset.
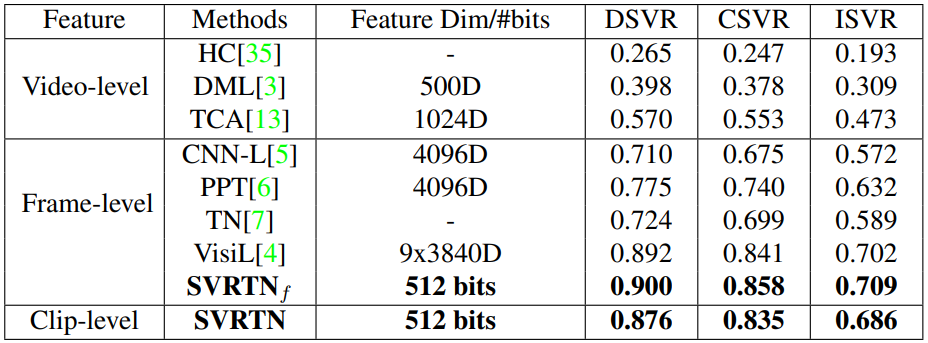
Table 1은 FIVR-200K에서의 성능, Table 2는 SVD 에서의 성능입니다. Self-supervised Learning 방식과 binarized feature로 SOTA의 성능을 달성한 것이 놀랍지만, Self-supervised Learning을 위해 다운 받은 비디오와 이를 segment로 나누고 clip을 생성한 과정이 자세하게 나와있지 않아 성능에 대한 약간의 의구심이 들긴하며 reproduction이 가능할지에 대해서도 의문이 생깁니다.
dataset
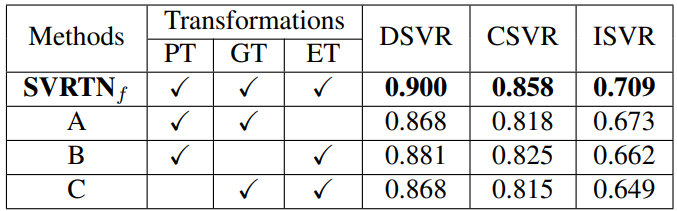
Table 3은 FIVR-200K에서 Spatial Transformation에 따른 ablation study이며 제안된 모든 Transformation을 사용했을 때 가장 높은 성능을 얻었다고 합니다.
modeling
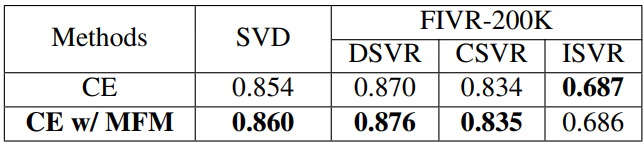
Table 4는 SVD와 FIVR-200K에서 Random mask 모듈에 대한 ablation study 입니다. 눈에 띄게 높은 수치는 아니나 약간의 성능 향상을 보였다고 합니다.
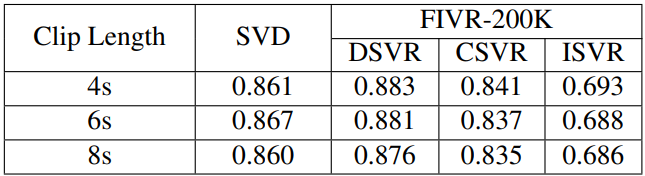
Table 5는 두 데이터 셋에서 clip의 길이에 따른 ablation study 입니다. 결과를 통해 제안된 clip-level set transformer 구조는 clip의 길이에 크게 민감하지 않았기에, 효율성을 고려하여(긴 clip이 한번의 처리하는 양이 많아 빠르기에) 다른 실험에서 clip의 길이로 8초를 선정하였다고 합니다.

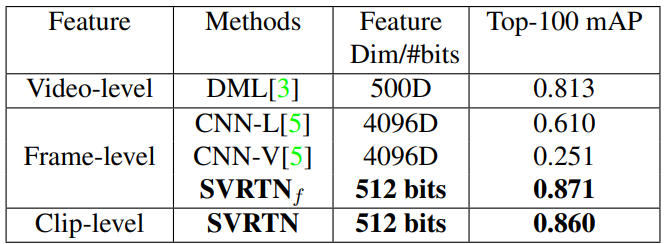
마지막으로 Table 6에서 frame-level feature와 clip-level feature 간의 retrieval도 가능하다는 것을 실험을 통해 보였습니다. 기존 다른 방법론들은 frame-level feature에서 video-level feature로 넘어갈수록 feature의 representation 성능이 저하되는 현상을 보였는데, 본 논문의 방법론은 video-level feature 까지는 아니더라도 clip-level의 feature가 frame-level feature와 비슷한 성능을 보이는 것으로 상황에 따른 flexible한 retrieval 방식을 적용할 수 있다고 합니다.
3. References
[1] https://arxiv.org/pdf/2104.07993.pdf