

이번에 리뷰할 논문은 Self-supervised 방식으로 Video Hashing을 진행한 논문으로, 이번 CVPR 2021에 Accept된 논문입니다. 이름은 self-supervised video Hashing method based on Bidirectional Transformers (BTH)로 이전 CVPR 2019에 게재 되었던 Centralized Similarity Quantization 논문과 비슷한 주제로 나왔다고 생각하여 읽게 되었으나 실제로 꽤 다른 부분이 많았습니다. 다른 부분으로는 우선 1) Self-supervised 방식 이라는 것과, 2) Construction Loss를 사용했다는 것과, 3) Binary coding을 할 때 Sign Function을 사용하였다는 점이 있었습니다. 이러한 특징의 자세한 부분은 아래 작성된 리뷰를 통해 다루도록 하겠습니다.
1. Method
1.1 Bidirectional Transformer Encoder
- Bidirectional transformer layer
최근 Transformer 구조가 비디오 분야에서 특정 순서에 관한 correlation을 찾을 때 유용하다는 점을 기반하여 많이 도입되고 있습니다. 본 논문도 Transformer 구조를 활용하나, 기존 방법론들이 사용한 Unidirectional Transformer 구조는 프레임 간의 correlation이나 비디오 간의 유사도를 활용하기에는 부족한 관계로 Bidirectional Transformer 구조를 사용합니다. 또한 입력으로는 매 프레임을 patch로 나눠서 표현하는 것이 아닌 한 프레임에서 CNN을 활용해 프레임 feature를 추출한 후 이를 Tranformer의 입력으로 활용합니다. 이렇게 프레임 별로 표현된 프레임 feature는 각 프레임 내의 visual contents를 보다 자세하게 포함하게 됩니다. 또한 Transformer 구조의 특징 상 입력의 순서를 알 수 없다는 부분을 보완하기 위해 사용하는 Positional Encoding은 매 프레임 별로 Cosine과 Sine 함수를 활용해 적용됩니다.
- Hash Layer
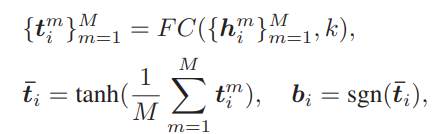
Hash Layer는 Transformer 구조 이후에 위치하여 차원 감소 및 이진화의 역할을 하게 됩니다. Transformer 구조에서 Embedding되어 크기가 Mxd 인 i번째 비디오의 프레임 feature(1, … , M) h가 FC Layer를 통과하며 이진화 될 벡터의 크기인 k 로 축소되며 Mean Pooling과 tanh 함수를 거친 이후 Sign function을 거쳐 이진화 된 벡터로 projection 됩니다.
1.2 Self-supervised Learning Tasks
- Visual cloze task
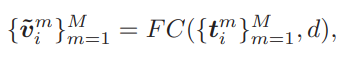
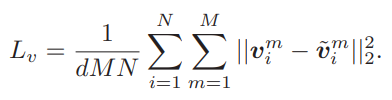
흔히 국어 시험이나 영어 시험에서 문장의 독해력을 평가하기 위해 특정 단어가 가려진 문장이 주어진 뒤 가려진 단어를 맞추는 문제가 출제되곤 합니다. 본 논문에 저자는 여기에 모티브를 얻어 한 비디오 내의 프레임 feature에서 일부를 masking 하여 이를 복원하는 Loss function 도입을 통해 representation 의 성능을 높이고자 하였습니다. 이는 프레임 feature에서 랜덤으로 선택하여 80퍼센트는 0 벡터로 10퍼센트는 학습데이터에서 선택된 랜덤 프레임 feature로 나머지 10퍼센트는 원래 프레임 feature를 그대로 사용해 대체하는 방식으로 적용되었습니다. 이렇게 적용된 후 앞선 식 (1)의 t 에서 FC Layer를 거쳐 나온 벡터를 원래의 프레임 feature v 와 MSE 연산으로 reconstruction Loss가 설계되었으며, 해당 Loss function을 통해 이진화 된 벡터들이 각 비디오의 visual contents에 해당하는 프레임 feature 내 정보를 잘 포함하도록 도와주게 됩니다.
- Similarity reconstruction task
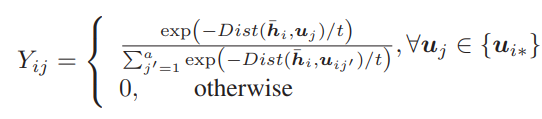
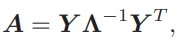
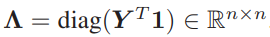
앞선 reconstruction Loss는 결과 값인 이진화 된 벡터의 visual contents 정보를 담는 것을 도와주긴 하나 벡터간 유사도를 보장하지는 못하기에 pairwise similarity constraint가 적용되었습니다. 적용에 앞서 본 논문의 방법론은 Self-supervised 방식이기에 유사한 pair를 만들고자 우선 BTH를 visual cloze task에서만 학습을 시켰습니다. 그리고 비디오 내의 매 프레임 별로 학습된 모델에서 Hash Layer로 들어가기 전의 latent vector를 추출하고 이를 Mean Pooling 하여 비디오 feature \bar{h}로 가공하였습니다. 이와 같은 방식으로 모든 비디오에서 \bar{h} 를 추출한 뒤 K-means clustering 방식을 활용해 각 cluster 중심으로 여러 개의 anchor set u를 구성하였고, 매 \bar{h} 에 대해 가장 가까운 anchor set u 를 선정한 뒤 식 (4)를 통해 truncated similarity matrix Y로 변환하였습니다. 여기서 Dist는 Euclidean Distance를 의미하며 t는 bandwidth parameter를 의미합니다. 변환된 Y를 식 (5)와 같이 다시 변환하여 approximate adjacency matrix A를 얻으며 이는 두 비디오 p, q 별 A_{pq}로 계산됩니다. 이 A_{pq}가 0 초과일 경우 두 비디오 간의 approximate similarity graph인 S_{pq}는 1로 설정되며 반대일 경우 -1로 설정됩니다.
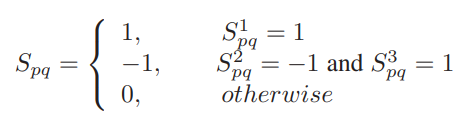
이와 같은 방식을 설계 후 Similarity 계산 시 효율적이고 높은 신뢰도를 위해 다음과 같은 조정과정을 거쳤습니다. 매 비디오 별로 가장 가까운 세가지 anchor a_{1}, a_{2}, a_{3} (a_{1}<a_{2}<a_{3}) 에 적용해 S^{1}, S^{2}, S^{3} 을 계산하며 이를 기반하여 식 (6)에서 처럼 해당 비디오 기준 다른 비디오와의 최종 Similarity S를 계산하게 됩니다.
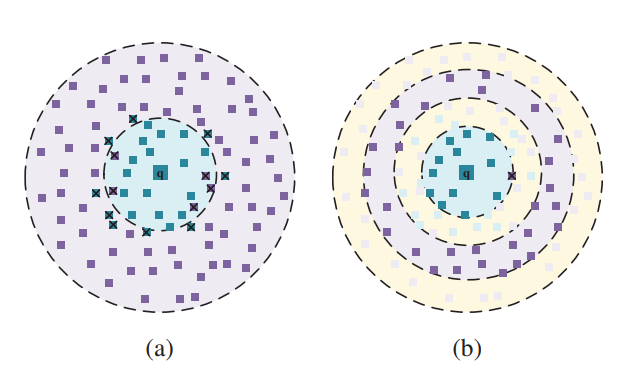
structure
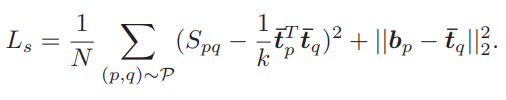
학습 시 매 비디오 별로 50퍼센트는 최종적으로 구한 S가 1인 관계의 비디오로 pairwise similarity 구조를 생성하며 나머지 50퍼는 S가 -1인 관계의 비디오로 선정됩니다. 이때 similarity reconstruction Loss function이 설계되며 이는 식(7)처럼 두 비디오 간의 유사도에 따라 tanh를 통과한 두 벡터의 곱(유사한 벡터 간의 곱은 1, 반대는 -1)의 term과 sign function을 통과하기 전 후의 reconstruction term으로 구성됩니다. 이와 같은 Loss 설계로 인하여 기존 Unsupervised similarity construction 방식의 Fig 3(a)보다 제안된 방식의 Fig 3(b)가 좀 더 discriminative representation 을 보였습니다.
- Cluster alignment task.
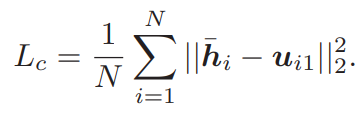
해당 논문이 제안하는 바는 Self-supervised 임에 동시에 label을 전혀 쓰지 않으므로 Unsupervised 입니다. 그러나 이러한 Unsupervised hash learning은 label 정보가 부족하기에 학습 시 특정 배치 내에서 전체 데이터 셋에 대한 본질적인 구조가 왜곡될 수 있다는 단점이 있습니다. 이를 막고자 구해둔 모든 anchor와 매 비디오마다 Transformer를 통과한 latent vector \bar{h} 간의 거리가 가장 가까운 anchor u_{i1}를 계산해 pseudo label로 사용하며 이를 할당하는 clustering Loss function도 식 (8)과 같이 추가하였습니다.
이에 더불어 식 (9)와 같이 앞서 구한 세가지의 Loss function이 weight sum되어 학습에 사용됩니다.
2. Experiments
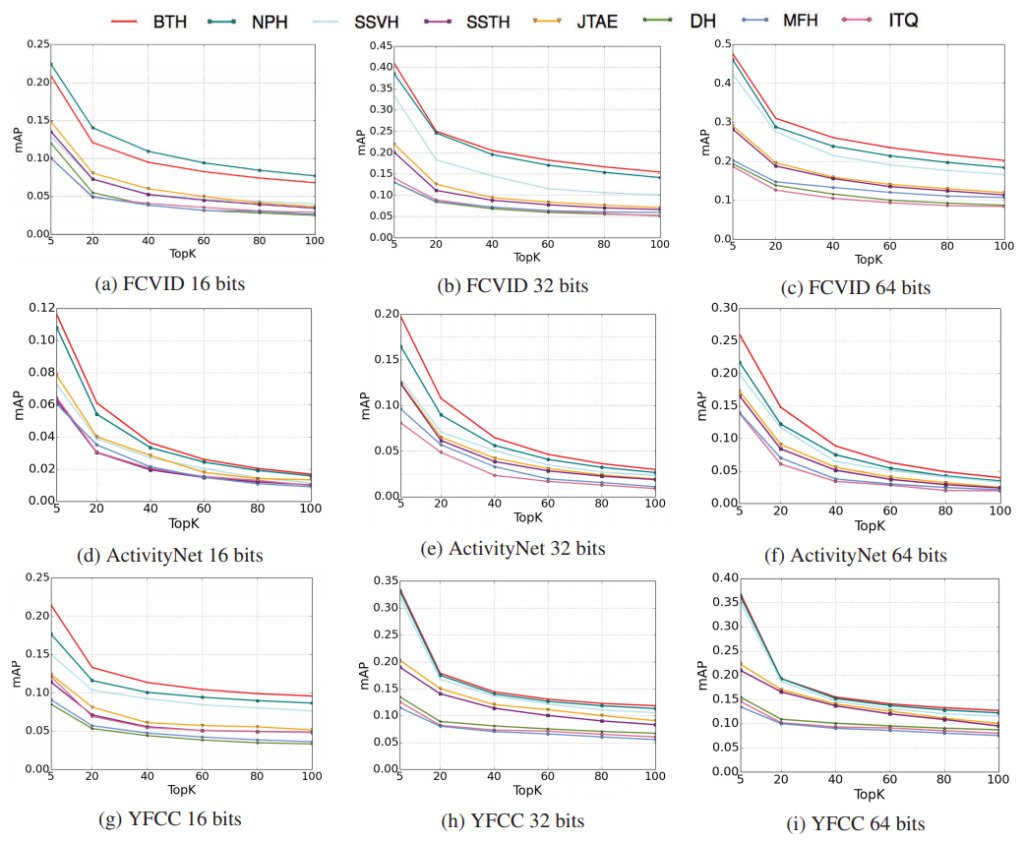
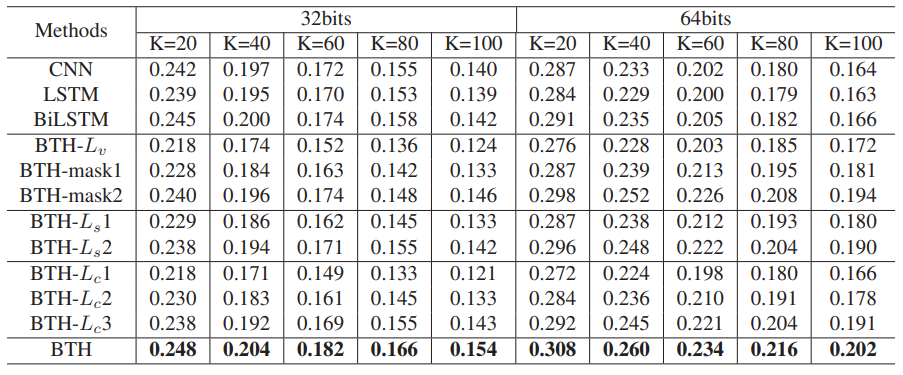
Fig 4와 Table 1은 각각 세 가지 혹은 FCVID 데이터 셋에서 제안된 BTH와 다른 방법론과의 성능 비교 그래프 및 표 입니다. Self-supervised 방식이라 그런지 대체적으로 성능이 낮으나 그래도 제안된 방식이 가장 좋은 성능을 보이긴 하였습니다.
Table 1에서 BTH-Lv 는 reconstruction Loss를 제거했을 시 성능이며, BTH-mask1은 한 비디오의 모든 프레임 feature를 복원하는 것이 아닌 masking된 부분만 복원하도록 설계했을 때의 성능입니다. BTH-mask2는 학습동안 masking 방식을 적용하지 않는 것을 의미합니다. 이 Visual cloze task와 관련된 실험을 통해 reconstruction Loss가 제거되었을 때 성능이 매우 하락하는 것으로 해당 부분의 중요성을 알 수 있습니다.
다시 Table 1에서 BTH-Ls1은 similarity reconstruction Loss가 제거되었을 때를 의미하며, BTH-Ls2는 추가 조정없이 처음 구해진 Similarity 를 바로 사용했을 때의 실험입니다. 이를 통해 reconstruction Loss로는 이진화 된 벡터 간의 유사도를 보장할 수 없어 도입된 해당 부분의 중요성을 확인할 수 있습니다.
마지막으로 Table 1에서 BTH-Lc1은 clustering Loss가 제거되었을 때를 의미하며, BTH-Lc2는 랜덤으로 pseudo center가 설정되었을 때를 의미합니다. 또한 BTH-Lc3는 bottlenect layer를 128에서 64로 줄였을 때를 의미합니다. 이를 통해 clustering Loss도 성능에 큰 영향을 끼치는 것을 확인할 수 있으며 전체 anchor 중 고른 pseudo center가 랜덤으로 고른 것에 비해 유효하다는 것도 알 수 있습니다. 또한 bottlenect layer의 차원을 줄일 시 visual information을 충분히 수용하지 못하여 pseudo center를 만드는 것에 영향을 미치는 것을 유추할 수 있습니다.
3. Reference
[1] https://openaccess.thecvf.com/content/CVPR2021/papers/Li_Self-Supervised_Video_Hashing_via_Bidirectional_Transformers_CVPR_2021_paper.pdf