
이번 CVPR2021 workshop 에서 열린 Monocular depth estimation 대회 중 Semi supervised 부문에서 1등을 기록했습니 다. 굉장히 영광스러운 결과이며 언제 또 이런 결과를 얻을 수 있을 까 싶은 성과이긴 합니다. 물론 많은 사람들의 관심이 없어서 제가 1등을 할 수 있었던 것 같습니다. 이러한 대회 결과에 맞춰서 이번에 리뷰할 논문은 Semi supervised depth estimation을 포문을 연 논문을 가져와 봤습니다.
대회에서 좋은 결과를 얻었지만 semi supervised 가 무엇인지도 모르고 있었어서 그와 관련해서 찾아보면서 발표준비를 했던 것 같습니다. 먼저 이 Semi supervised를 알려면 supervised 와 self-supervised 가 무엇인지를 알아야합니다.

설명을 위해서 제 발표자료를 첨부했습니다. supervised는 D(x) (= 모델으로 추론된 깊이영상) 과 GT( =Lidar)를 직접적으로 비교해서 Loss를 계산합니다. 그리고 self-supervised 같은 경우는 D(x)와 GT를 직접 비교하지 않고 D로 생성된 무엇(요기선 I’이 되겠죠)과 실제 I와 비교를 통해서 loss를 계산합니다. 즉 self-supervised의 경우 task에서 원하는 결과 값 (Depth estimation 에 경운 Depth 가 되겠고 Object detection의 경우 물체의 위치와 class 정보를 뜻합니다) 이 아닌 값을 실제 비교 대상으로 사용해서 학습하는 방식을 뜻하고 supervised의 경우는 원하는 결과 값을 직접 비교해서 학습하는 것입니다. 그럼 semi-supervised가 무엇이냐 ? 하신다면 위의 그림의 하단을 보시는 것과 같이 supervised와 semi supervised가 합쳐서 loss로 사용하는 것을 뜻합니다. 즉 두 가지 학습의 장점을 조금 씩 혼합하겠다는 것을 의미합니다. 그럼 Semi-supervised에 대한 간단한 설명이 였고 Depth estimation에서 어떻게 Semi-supervised가 제안 되었는 지 이 논뭉을 통해서 설명드리도록 하겠습니다.
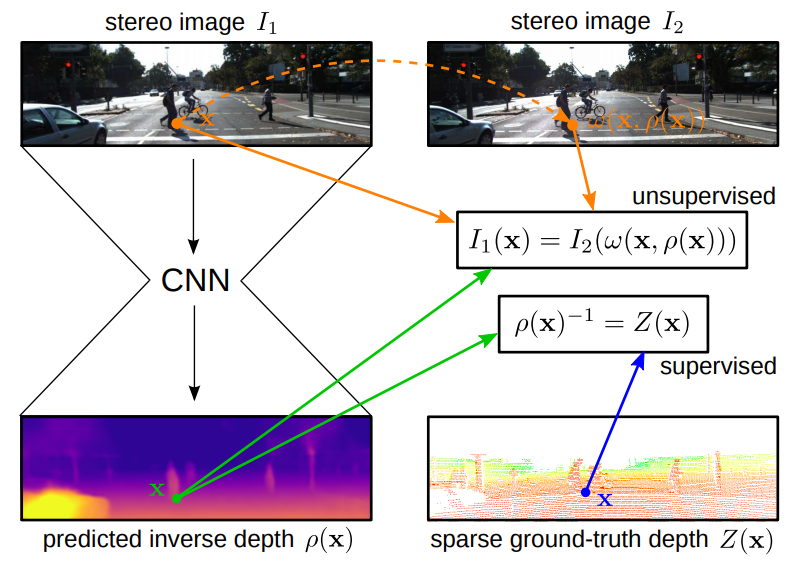
딥러닝 학습에 있어서 데이터를 얻는 것은 다양한 테스크에서 중요한 문제이자 어려운 문제로 다뤄지고 있습니다. 특히 Depth estimation에서는 dense depth map을 얻는 것은 굉장히 어려운 문제 입니다. 특히 실제 야외 환경에서 얻는 다는 것은 불가능에 가깝다고 합니다. 또한 lidar 의 경우 Sparse 하여 dense depth map을 뽑기 위한 GT로는 알맞지 않았었습니다. 하지만 때마침 2017년도 당시 dense depth map을 학습에 사용하지 않고 Disparity와 Depth의 관계를 활용한 self-supervised 방식이 나왔습니다. 이러한 self-supervised 방식과 기존에 사용되기 어려웠던 lidar를 활용하면 더욱 정교한 Dense depth map 을 얻을 수 있었고 이 성능은 당시 KITTI에서 SOTA를 달성했다고 합니다.
- Method
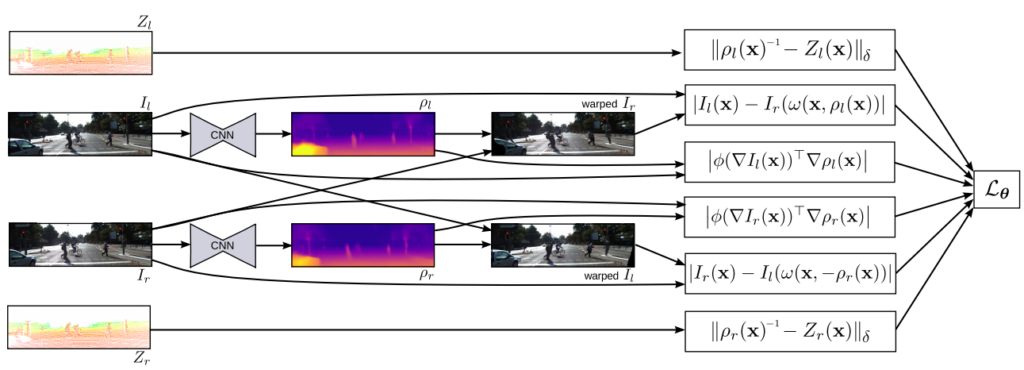
학습 방식은 사실 4년이나 지금 보면 굉장히 간단합니다. 바이블과 같은 Monodepth 와 Lidar를 Supervised로 비교했다는 것 두개만 알면 사실 방법론은 다 안다고 생각하시면 됩니다.
학습을 위한 loss로는 정말 딱 세개만 아시면 됩니다. Supervised term, Unsupervised term, Smooth term 이 세가지 입니다.
Supervised term
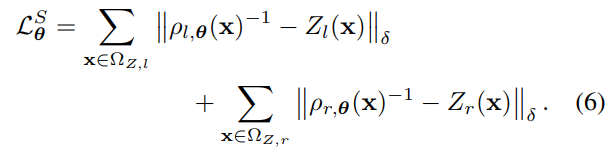
위의 식은 Supervsed term의 Loss 입니다. 모델을 통해 예측한 inverse depth 와 Z(x)( Lidar)를 비교해서 loss를 구하는 것입니다. 물론 Lidar는 sparse하니까 lidar point 가 있는 곳에서만 Loss계산을 합니다.
Unsupervised loss ( self -supervised term)
2017년도 당시에는 Monodepth 의 방식을 Unsupervised로 불렀었는데 많은 논쟁을 거쳐 self-supervised로 불립니다. 암튼 이 논문에서 사용된 self-supervised term의 로스는 아래와 같습니다.
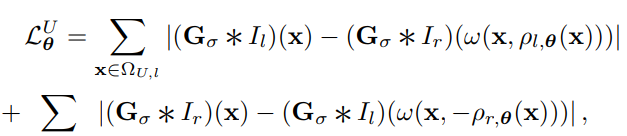
Monodepth에서 제안된 것과 같이 left-right consistency 방식을 활용해 texture 문제를 잡았습니다
Smooth term
많은 depth estimation 에서 사용하는 loss term 이빈다. 생성되는 depth에 구멍이 생기지 않도록 하는 Loss term 입니다.
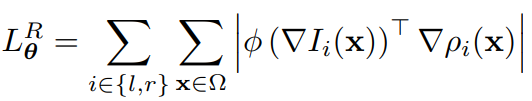
식은 다음과 같습니다.
1.2 Network

네트워크는 Residual 방식을 사용하지 않는 네트워크인 FlowNet에서 영감을 받고 Residual 하도록 변경하여 사용했다고 합니다. ResNet-50과 호환이 될 수 있도록 네트워크 구조를 encoder 를 변경하였고 ImageNet을 pretrained 한 weight를 가져다가 사용함으로써 성능향상을 보았다고합니다.
2. Result
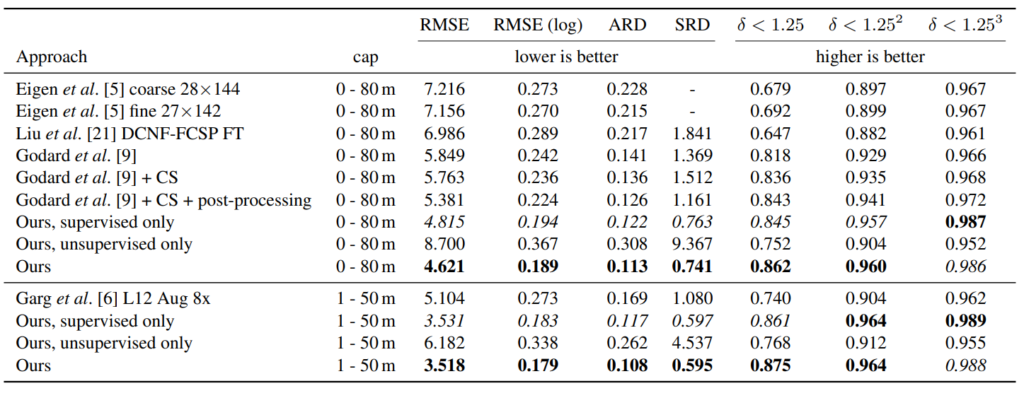
위 결과는 KITTI에서 당시 방법론들과 비교 결과 입니다. Monodepth 가 Godard et al 입니다. 당시 Monodepth가 KITTI에서 SOTA였었습니다. 그걸 감안 하고 보시면 Ours가 semi로 했을때 기존 방법론들을 다 이기는 것 뿐만 아니라 Ours supervised 방법도 이기는 것으로 Unsupervised의 boosting을 확인 할 수 있습니다.
지금 보면 굉장히 라이브하고 간단한 방법론이고 간단한 생각일 수 있습니다. 하지만 당시에 Monodepth가 얼마 안나오고 인지라 Supervised 와 Unsupervised 방식의 혼합에 대한 당위성과 타당성을 잘 포함하고 있으며 성능 또한 잘 도출해낸 것 만으로도 대단한 논문이라 생각이 됩니다. 보니까 이 논문 저자가 이번 챌린지 관리자더군요. 그래서 Semi 또한 eval metric으로 넣은 것 같습니다.