이번 리뷰 논문은 제목대로 stereo matching에 관한 방법론입니다. 해당 방법론은 서로 다른 데이터 셋 차이에도 강인하게 성능을 평가하는 대회 ECCV 2020 workshop “Robust Vision Challenge 2020 – Stereo task”에서 1st place를 차지한 방법론입니다. 또한 KITTI 리더보드에서도 39등의 성능을 가져 domain specific 에서도 준수한 성능을 보여주는 방법론입니다.
Intro
방법론을 설명하기 앞서 해당 논문에서 언급하는 Robust가 의미하는 바를 설명하고자 합니다. 딥러닝은 ImageNet Challenge를 통해 지도 학습의 효과를 확실하게 보여주었습니다. 하지만 지도 학습 기반의 딥러닝 모델은 학습한 데이터 셋과 다른 특성을 가진 데이터에서는 강인하지 못한 성능을 보여주어 실제 어플리케이션에 적용을 위해서는 전이 학습(가장 대표적인 방법으로 fine-tuning), 즉 적용하고자 하는 어플리케이션에 맞는 데이터 셋을 제작 및 가공하여 재 학습하여 적용하는 방법을 이용합니다. 이는 제작 비용으로 이어지며, 예상치 못한 환경에 대해서는 한계를 극복하지 못하기 때문에 딥러닝 방법을 제품에 적용하기에 있어 명백한 한계에 해당합니다. 최근 다양한 연구들은 지도 학습의 한계를 극복하고자 추론 중 학습을 하는 online learning, domain adaptation 등 다양한 방법론들이 연구되어지고 있습니다. 다양한 방법론 중에서 여기서 말하는 Robust는 서로 다른 환경과 목적으로 촬영된 데이터 셋, 즉 다른 domain에서도 성능이 불변하지 않고 강인한 성능을 보여주는 것을 의미합니다.
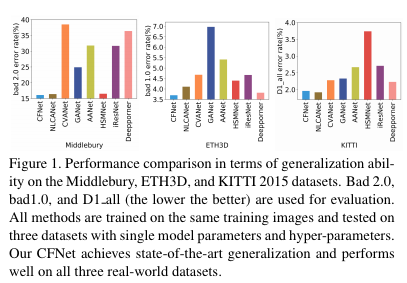
Fig 1(CFNet)과 같이 하나의 모델과 파라미터로 다양한 데이터 셋에서도 강인한 성능을 보여줌으로써, 실제 환경에서도 강인성을 증명합니다. 이로써 제품화 되었을 경우, 실제 환경과 학습 데이터간 domain 차이로 발생할 문제들을 극복 할 수 있다는 가능성을 보여줍니다.
++ 이해를 위해 각 데이터 셋에 대해 간단한 설명을 첨부하겠습니다.
– SceneFlow : Stereo matching과 optical flow를 위한 가상 데이터 셋(960 x 540; 35,454 training images; 4,370 test images;). 실제 환경은 아니지만 정확한 정보와 대용량의 데이터 셋에 해당합니다. CFNet에서는 기본적으로 해당 데이터 셋으로 사전 학습을 진행하였습니다.
– Middlebury : 고화질의 실내 stereo image datasets(13 train images; 15 test images). Disparity range : 0-400.
– KITTI 2012&2015 : 실외 주행 차량에서 수집된 stereo image datset(200+200(KITTI2015); 194+195(KITTI2012)). Disparity range : 0-230.
– ETH3D : 실외 및 실내 환경에서 촬영된 stereo image datasets(27 train images; 20 test images). Disparity range : 0-64.
CFNet
CFNet은 다른 방법론들과의 차별성을 크게 두가지 부분을 볼 수 있습니다. 하나는 다중 해상도를 가진 dense cost volume을 fuse함으로써, 강인한 구조적인 표현력을 가진 initial disparity를 예측합니다. 두번째는 disparity range space의 파라미터를 학습을 통해 얻어 다음 스테이지에 전달하여 적응적으로 다른 도메인간 발생하는 불균형적인 disparity distribution을 해결합니다.
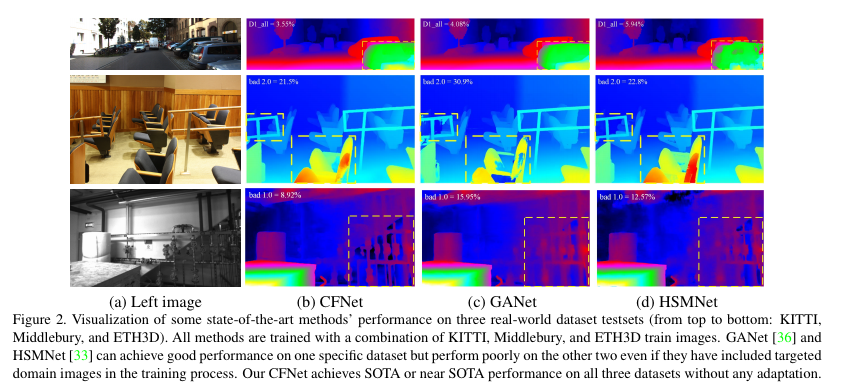
3가지 데이터 셋에서의 정성적인 결과를 보여주는 Fig 2를 보면 GANet과 HSMNet은 각각 KITTI와 ETH3D에서 좋은 결과를 보여줍니다. 하지만 3가지 데이터 셋에서는 비교적 강인하지 못한 결과를 보여주는 반면 CFNet은 3가지 결과에서 좋은 모습을 보여줍니다.
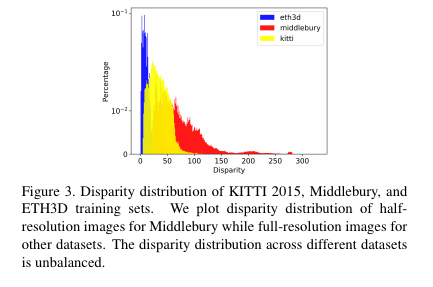
이는 Fig 3처럼 각 데이터 셋마다 disparity가 다른 범위를 가지고 있는 문제에 포인트가 있습니다. 기존의 방법론들은 사전 학습된 데이터 셋에서 disparity range를 결정한 상태에서 추론을 진행하기 때문에 fig 2와 같이 일정 데이터 셋에서 좋은 결과를 보여주는 모습을 보여줍니다.
Method
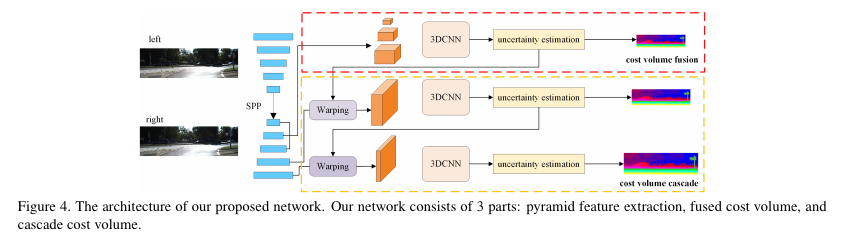
CFNet은 SOTA를 달성한 다른 방법론과 동일하게 4d-tensor(w*h*disparity*feature)의 cost volume을 이용하여 disparity를 예측합니다. 전체적인 모델 구조는 fig 4와 같으며, 크게 3가지로 나눠서 본다면 pyramid feature extraction, fused cost volume, cascade cost volume으로 나눠집니다.
먼저 pyramid feature extraction은 stereo image을 siamese unet-like encoder-decoder를 통해 multi-scale image feature를 추출합니다. 각 모듈은 5개의 residual block 형태를 가지며, SPP(Spatial Pyramid Pooling)을 통해 문맥적 정보를 통합하여 decoder에 전달되어집니다. 그 다음 multi-scale image feature는 나누어져 결합되고 cascade cost volume을 적용한 다음 disaprity를 예측합니다.
Fused Cost Volume
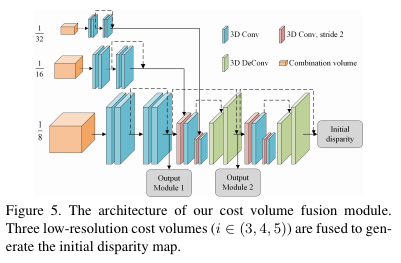
기존 방법론에서는 low-resolution은 효율적인 정보를 가지고 있지 못하기 떄문에 일반적으로 버리는 방법을 선택했습니다. 하지만 저자는 기존의 방법과는 반대로 low-resolution도 포함하여 결합할 경우, 전반적인 구조적 표현을 알 수 있으며, 기존의 방법인 higher-resolution sparse cost volume에 비해 보다 정확한 initial disparity map을 생성할 수 있다고 주장합니다. 그렇기에 fig 5와 같이 low-resolution을 가진 3d cost volume을 결합하여 생성합니다. 결합된 3d tensor는 3d-deconvolution layer를 가진 3d-hourglass network를 통해 4d tensor를 출력하고, 최종적으로 soft argmin을 통해 disparity를 예측합니다. 해당 모듈에서 initial disparity map을 출력합니다.
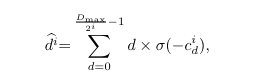
Cascade Cost Volume
기존 방법들은 사전 정의된 disparity range space에서 정의 진행했습니다. 이럴 경우 가려짐, 잘못된 위치, 데이터 셋 마다 다른 특성으로 불균형이 발생하여 정확성을 떨어지는 문제가 발생합니다. 저자는 이러한 문제를 해결하기 위해 이전의 stage의 disparity estimation을 사전 지식으로 이용하는 것을 제안합니다.
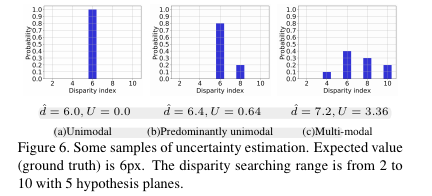
저자는 위의 문제를 해결하기 위해 적응적인 분산 기반의 disparity range uncertainty estimation을 제안합니다. 이전의 방법론들은 각 disparity index로부터 발생한 확률을 weight sum 혹은 다른 연산을 통해 최종적인 disparity를 추정하였습니다. Fig 6을 보면 이상적인 결과는 (a) Unimodal 처럼 한 index만 존재하는 경우, 오차 없이 결과를 추론이 가능합니다. 하지만 modal이 증가함으로써 GT 6px를 점점 벗어나는 것을 볼 수 있습니다. 저자는 이런 문제를 해결하기 위해 이전 연구 중 modal이 증가하면 발생하는 오차는 modal의 분산과 큰 상관관계를 가진 결과에 집중합니다. (쉽게 말하자면, 가려짐이나 잘못된 위치에서 예측하는 경우는 다양한 인덱스에서 예측값, 즉 fig 6의 기둥이 많아짐. 값이 할당된 Index(modal)이 많아지니 분산이 커진다는 말). 저자는 modal과 prediction error의 관계를 이용하여 정량적인 정도, uncertainty estimation을 제안합니다.
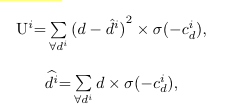
+ 위 수식을 간단하게 설명하자면, Fig 6의 평균(2열), 분산(1열)을 구한다고 보시면 됩니다. 위에서 설명한대로 predicted error와 modal의 분산이 큰 관계를 가지기 때문에 가능한 결과입니다.
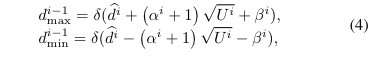
malization factors
수식 4에서 a, b는 학습이 가능한 파라미터에 속합니다.
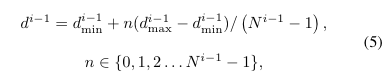
최종적으로 수식 5를 통해 disparity search space를 uncertaity score와 학습 가능한 a,b를 이용하여 적응적으로 조절이 가능해집니다.
Experiment
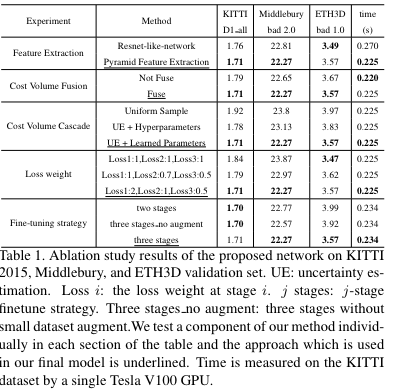
해당 방법론의 독특한 특성은 학습 방법에도 있습니다. 학습 진행 시, 3 stage로 학습을 진행합니다. Fig 4에서 나눠진 3 stage를 순차적으로 학습을 진행합니다. 각 stage의 loss는 L1 loss를 적용하여 학습을 진행하였습니다. 해당 방법론의 ablation study는 아래와 같습니다.
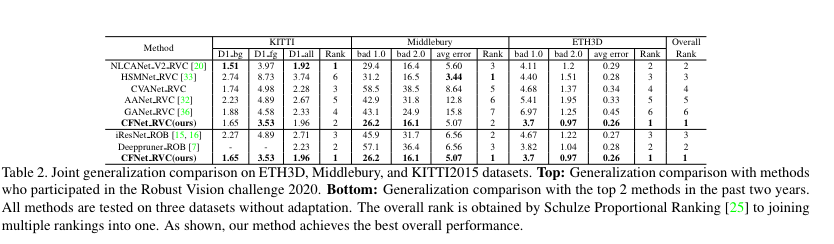
해당 방법론의 메인은 Table 2에 있습니다. 위의 결과는 Robust Vision Challenge의 결과 입니다. 해당 방법론은 모든 방법론에서 1등을 한 것을 아니지만, 놓친 부분은 2등을 달성한 것을 볼 수 있습니다, 또한 하단 3개의 행은 현존하는 SOTA 방법론과 비교한 결과에도 가장 좋은 결과를 보여줍니다. 해당 결과에서는 Sceneflow, KITTI, Middlebury, ETH3D에서 학습을 진행한 결과입니다.
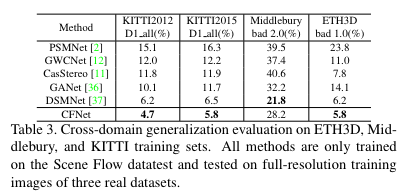
Table 3은 Sceneflow에서만 학습 후 다른 데이터 셋에서 보인 결과 입니다. 다른 방법론에 비해 월등히 높은 결과를 보여줍니다.
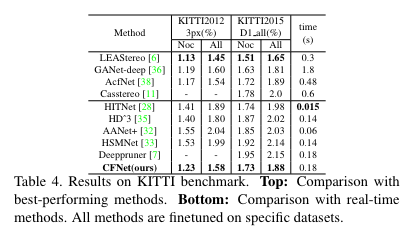
다음 결과는 일반적인 지도 학습과 동일하게 KITTI로 학습 후, KITTI에서 평가한 결과 입니다. 재밌는 점이 현재 KITTI Stereo 리더보드에서 39등을 보여주면 준수한 성능을 가져오며, 무엇보다도 해당 방법론과 동일하게 rosbust stereo matching 방법론인 Casstereo보다 3배 빠른 결과를 가져오며, 3등인 LEAStereo보다 좋은 속도를 보여줍니다.