Abstract
end-to-end로 학습할 수 있도록 attention 모듈을 쌓아서 Residual Attention Network를 만든다.
각 모듈을 통해 attention-aware feature를 생성한다.
Introduction
Residual Attention Network는 CNN 네트워크로 깊은 구조에 적용 가능하다. 각 모듈은 attention-aware feauture를 생성하며 다음의 특성을 가진다.
- 모듈 수가 증가할 수로 성능이 지속적으로 향상된다.
– 다른 특징들을 광범위하게 수집하므로 성능이 향상된다. Fig 1에서 하늘에 대한 attention mask는 배경을 죽이고 열기구 풍선에 대한 attention mask는 풍선의 아래 부분을 강조한다. - SOTA 네트워크에 end-to-end로 통합될 수 있다.
– 이로 인해 깊이가 수백 레이어로 깊어질 수 있다.
Contribution
- Stacked 네트워크 구조
– 여러 모듈을 쌓는 stack구조로 여러 종류에 대해 attention하는 구조가 가능 - Attention Residual Learning
– 그냥 stack으로 쌓으면 성능이 하락하므로 attention residual learning이라는 mechanism 제안 →수백층의 레이어로 학습 가능 - Bottom-up top-down feedforward attention
– bottom-up(feedforward 과정) 과 top-down(feedback 과정)을 단일 feedforward방식으로 모방하여 end-to-end로 학습 가능하도록 함

Residual Attention Network
attention 모듈을 쌓아 구성한 네트워크로 각 모듈은 2개의 branch로 나뉜다.
- trunk branch
feature processing역할을 수행하고 다른 SOTA 네트워크 구조를 적용할 수 있다. - mask branch
x를 입력으로 하는 trunk branch의 output이 T(x)라 할 때 bottom-up top-down구조를 이용해 같은 크기의 M(x) 마스크로 softly weight을 주어 학습시킨다.
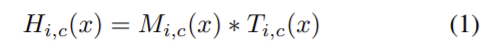
attention 모듈의 출력은 (1)의 식으로 i는 위치를, c는 채널의 인덱스를 의미하고 전체 구조는 end-to-end로 학습된다.
attention 모듈은 forward inference동안 feature selector역할을 하고 back propagation과정 동안 gradient update filter역할을 한다.
soft mask branch에서 마스크의 입력 feature에 대한 gradient는
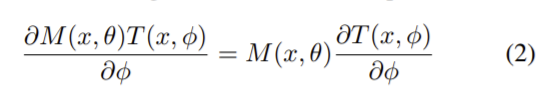
로 θ는 mask branch에 대한 파라미터이고 ϕ는 trunk branch에 대한 파라미터이므로 잘못된 가중치를 막아주어 noisy label에 강인한 특성을 가진다. (mask branch M(x,θ)가 있으므로.)
단순한 stack 구조가 아닌 spatial transformer와 비슷한 방식으로 soft weight mask를 생성하면 복잡한 배경과 복잡한 이미지, 큰 외관 변화에 대해 각각 다른 attention 모듈이 필요하고, 단일 attention 모듈은 feature를 한번만 조정하므로 한번 잘못하면 바로잡기 어렵다는 단점이 있다. 이는 trunk branch에 각각 mask branch가 있어서 그 feature에 특화된 attention을 학습할 수 있고 여러 모듈을 쌓으면 복잡한 이미지에 대해 조정할 수 있다.
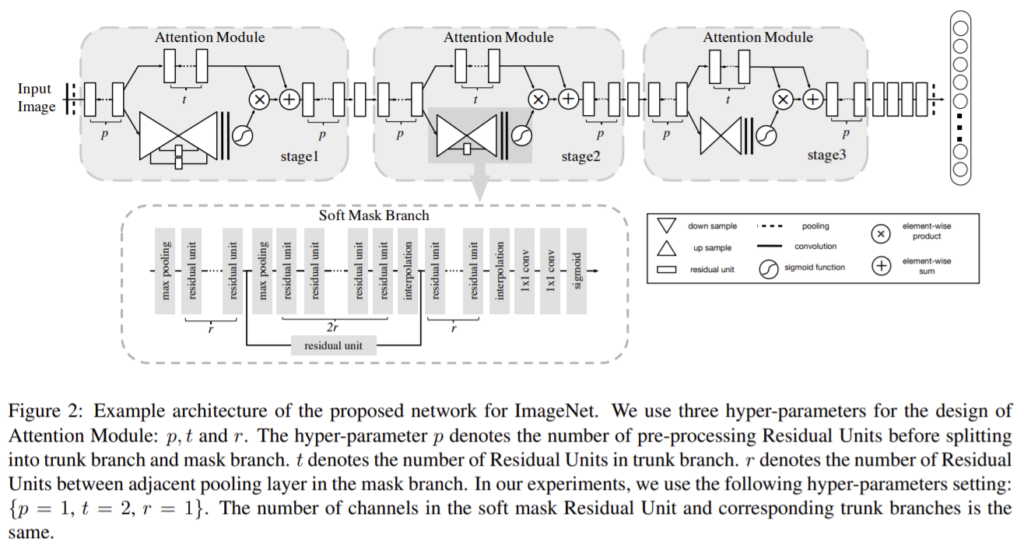
1. Attention Residual Learning
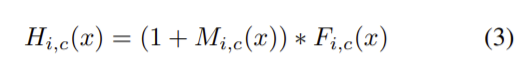
H는 attention 모듈의 output이고 M(x)는 [0,1] 의 값으로 0으로 수렴하면 H(x)는 F(x)(original feature)로 수렴한다. F(x)는 feature를 나타내고 M(x)는 마스크 branch의 값으로 feature selector역할을 해 trunk branch에서 나온 좋은 특징은 강화하고 노이즈는 약화시키는 역할을 한다.
또한 여러 attention 모듈을 쌓아 attention residual learning을 보조하여 좋은 특성은 유지하고 보조 통로를 이용해 mask branch의 특징 선택 능력을 약화시켜 feature를 fine-tunning하는 역할도 한다.
2. Soft Mask Branch
mask branch는 fast feed-forward sweep을 통해 전체 이미지에서 전역 정보를 빠르게 모으고 top-down feedback step을 통해 전역 정보를 original feature map에 합친다.
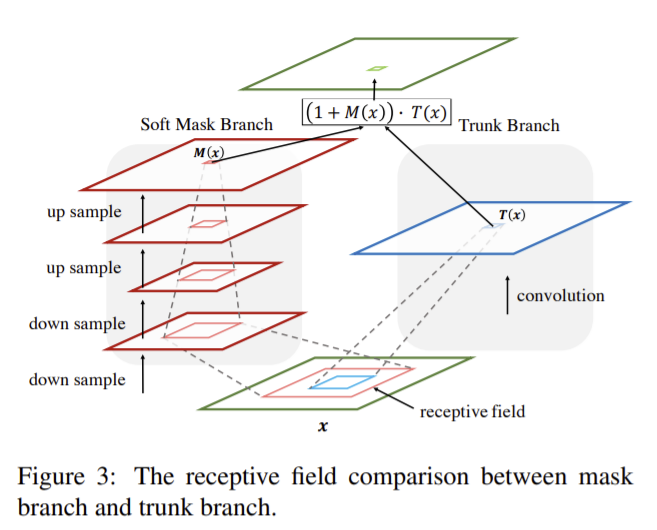
입력단에서 몇번의 maxpooling을 통해 receptive field를 빠르게 증가시키고 이를 통해 얻은 전역 정보를 대칭적인 top-down 구조를 통해 input feature의 각 위치에 알려준다.
선형 보간으로 up sampling을 진행하고 이때 maxpooling의 개수와 bilinear interpolation의 개수를 같게 하여 output의 크기가 input의 크기와 같도록 한다.
이후 2개의 1×1 conv 레이어를 통과한 후 sigmoid 레이어로 normalize를 해 [0,1]의 값을 같도록 한다.
또한 bottom-up과 top-down 사이에 skip connection으로 추가하여 다른 scale에서의 정보를 얻는다.
3. Spatial Attention and Channel Attention
mask branch의 attention은 trunk branch에 따라 달라진다. 하지만 soft mask의 출력 전에 활성함수에서 정규화 방식을 바꾸면 mask branch에 attention을 바꿀 수 있다.
- mixed attention f1: 단순히 sigmoid로 정규화 → 채널, 공간 정보 활용
- channel attention f2: 모든 채널의 각 위치에서 공간적 정보를 제거하기 위해 L2로 정규화 → 채널 정보에 집중
- Spatial attention f3: 각 feature map에 대해 정규화 해준 값이 시그모이드 함수를 통과하도록 정규화 → 공간 정보에 집중
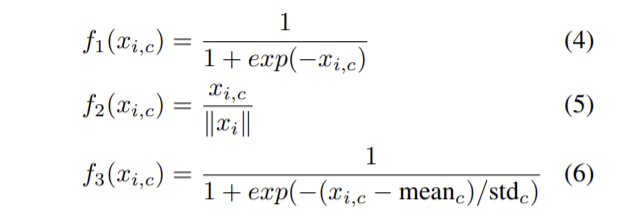
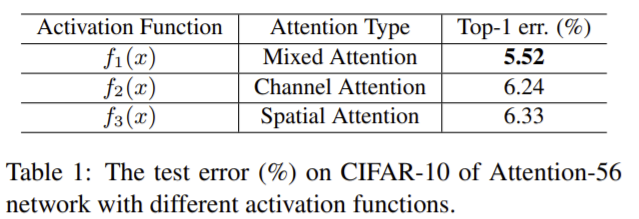
식은 위와 같고 각각의 정규화 방식에 따른 성능은 다음과 같다. mixed attention이 가장 성능이 좋았다. 이전까지는 크기나 위치 중 하나에 대해 attention을 했는데 그 방식보다 이 실험에서 제안한 feature에 따라 적절한 것에 대해 attention 하는 것이 성능을 향상시킨다.
Experiment 1 – CIFAR
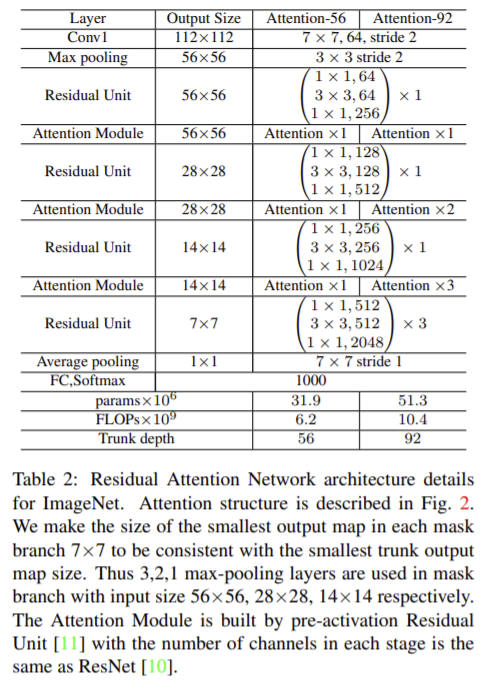
**fig2에서 하이퍼 파라미터 참고
- 각 구성 요소의 효과를 확인하기 위한 실험
ResNet을 baseline으로
- Attention Residual Learning
attention residual learning (ARL)개념이 새로운 것이므로 naive attention learning(NAL)과 비교함. 이때 NAL은 attention residual learning없이 바로 feature과 soft mask가 dot product한 것
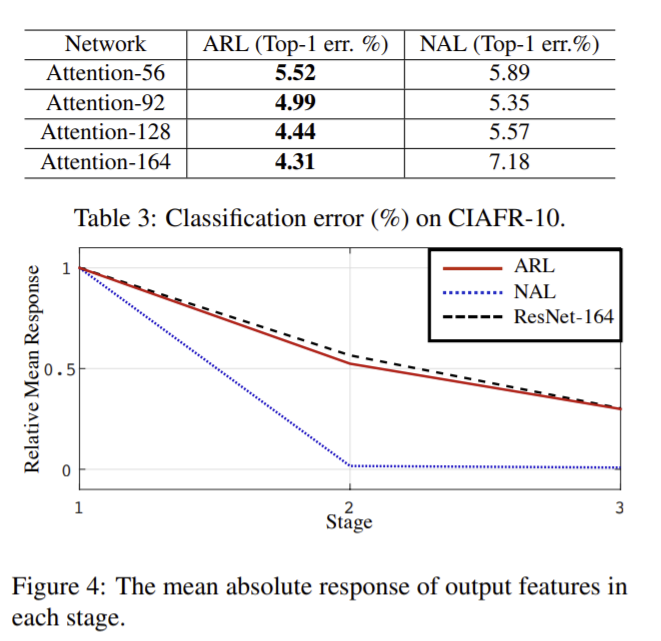
- mask structure에 대한 비교
local convolution(up/down sampling이 없는 3개의 같은 수의 FLOPs를 이용하는 residual unit)과 비교함.

2. 노이즈 강인성 실험
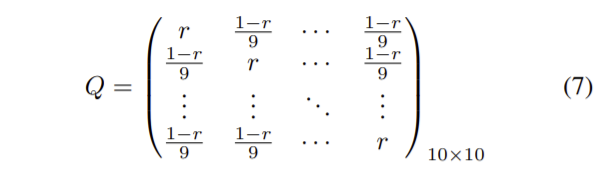
confusion matrix Q는 식 (7)과 같고 r은 전체 데이터 셋에서 clean label의 비율을 의미한다. 실험 결과 높은 노이즈 비율에서도 잘 학습된다.
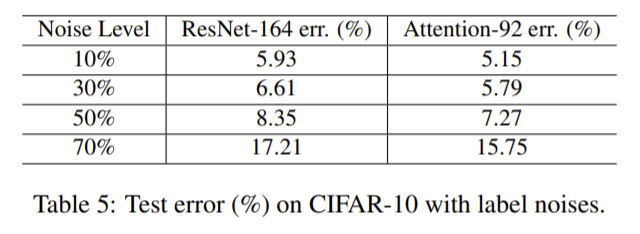
- SOTA와 비교
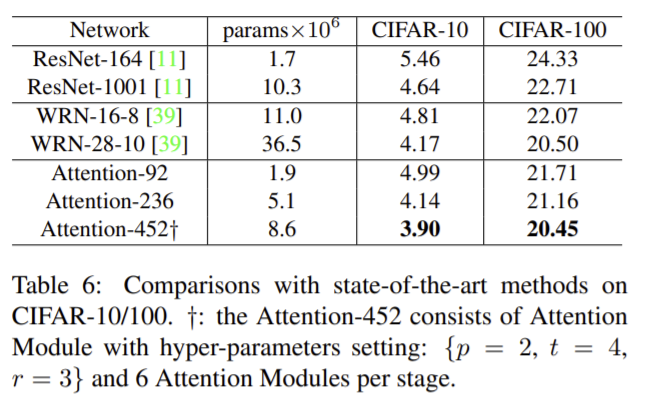
Experiment 2- ImageNet Classification
table2의 하이퍼 파라미터 참고
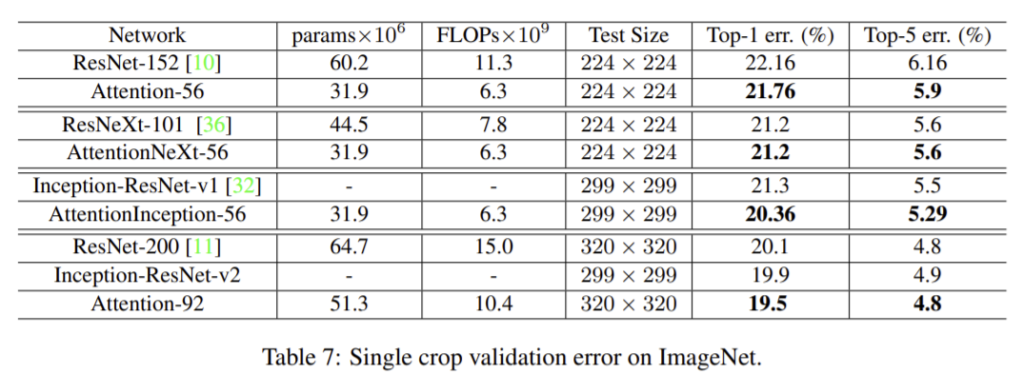
이 실험에서 3가지의 다른 basic unit인 Residual Unit, ResNeXt, Inception을 이용함
Discussion
이 논문은 다음 2가지의 이점 때문에 여러 Residual Attention Network 를 쌓아 사용하기를 제안한다.
- 다른 attention 모듈은 다른 특징을 포착해 학습하도록 한다.
– mixed attention에 대한 실험으로 이를 증명했다. - 각 모듈에서 encoding top-down attention이 bottom-up top-down feedforward conv구조로 바뀌어 기본 attention 모듈이 결합되어 큰 네트워크 구조를 형성하도록 하고 Residual attention learning으로 “very deep”한 구조가 학습될 수 있게 한다.
참고: https://www.stand-firm-peter.me/2021/02/27/res-attention/