해당 논문은 Semantic Similarity의 범위에 대해 논하는 논문이다. 처음 논문을 선택한 이유는 similarity의 범위에 대해 분석하고 있는 내용인지 궁금하여 선택하였다. 해당 논문에서 다루는 video retrieval은 video to caption retrieval이다.
Abstract

- 논문에서 제시하는 문제점
기존의 video retrieval task에서는 single caption과 하나의 query video가 쌍이 된다는 것을 가정으로 진행되었다. 그러나 이러한 가정은 모델의 검색 성능을 정확히 비교하지 못한다고 주장한다. - 논문에서 제시하는 해결책
multiple video/caption으로 진행하자
쿼리와의 유사도 기준으로 검색된 비디오의 순위를 매기자
현재 비디오 검색 벤티마크의 단점
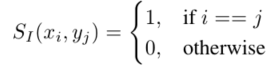
기존 유사도 식의 경우 하나의 caption 당 하나의 연관 비디오를 갖는다. 즉, 어느 caption도 유사성을 갖지 않는다는 가정이 있다는 것이다. 논문에서 이러한 검색을 instance-based video retrieval (IVR) 이라고 한다. 그러나 GT가 되는 annotation들은 annotator 혹은 비디오에 포함된 캡션으로 생성된다. 즉 y value(label, caption)간의 유일성을 보장 할 수 없다는 것이다. 이러한 문제점을 짚기 위하여 논문에서는 몇가지 실험으로 정성적으로 검토하였다.
- Dataset 분석
데이터셋의 크기에 따라 혼잡도가 달라져 발견하고자 하는 문제점이 출연확률이 달라지므로 데이터셋의 크기에 따라 정렬 후 실험하였다고 한다. 논문에서는 large test set을 갖는 MSR-VTT, YouCook2, EPIC-KITCHENS를 실험에 사용하였다고 한다. 아래 FIgure 2 가 검색 결과의 예시히며 각 이미지에 나열된 caption 중 굵은 글씨가 evaluation때 GT로 사용되는 캡션이다. 그러나 아래 얇은 글씨의 caption역시 video와 상당한 연관이 있음을 알 수 있다.
opening sauce bottle이 GT라면 opening vinegar/oil bottle >> cutting a tomato (연관성)이어야 한다는 것이다. 그러나 현재 존재하는 벤치마크를 수정하는 것은 비용이 너무 많이 드므로 유사도를 이용한 proxy 조취를 취해야 함을 밝힌다.
제안: Similarity Video Retrieval (SVR)
- 기존에 사용되는 지표
– Recall@K:
multiple items을 다룰 수는 있지만 임계값이 필요하다. 또한 K개를 선출하는 작업은 relevant items수가 K보다 클 수 있으므로 신중해야 한다.
– mAP:
query와 검색된 item 사이의 연관정도를 이진화 해야한다.
- 정의
기존의 방식은 0, 1로 유사도를 분류 형식으로 정의했다면, 제안하는 방식은 비교가능한 값(non-binary similarity)으로 유사도의 정도를 나타낼 수 있도록 한다.
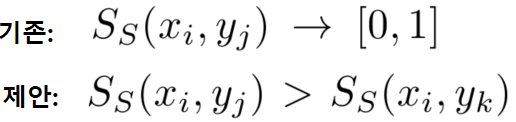
- normalised Discounted Cumulative Gain (nDCG)
nDCG는 DCG score를 normalising한 값이다. 본 논문에서는 evaluation metric 으로 Recall@k나 mAP 방식이 아닌 nDCG로 평가하였다.
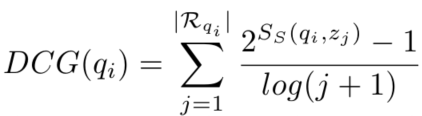
학습
제안하는 Semantic Similarity 계산방식은 학습과정의 distance metric 대신 사용하여 학습에도 적용할 수 있다. 또한 학습을 위한 GT 생성시 proxy measures를 사용할 수 있다. 식1에 유사 정도가 표현되지 않았던 쌍들에 대해 캡션관의 유사도를 측정하여 S’ score를 이용하는 것이다. S’ score는 논문에서 제시하길 (Bag-of-wards semantic similarity, Part-of-Speech Semantic Similarity, Synset-Aware Semantic Similarity, METEOR Similarity를 사용하였다고 한다.)

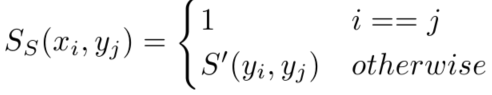

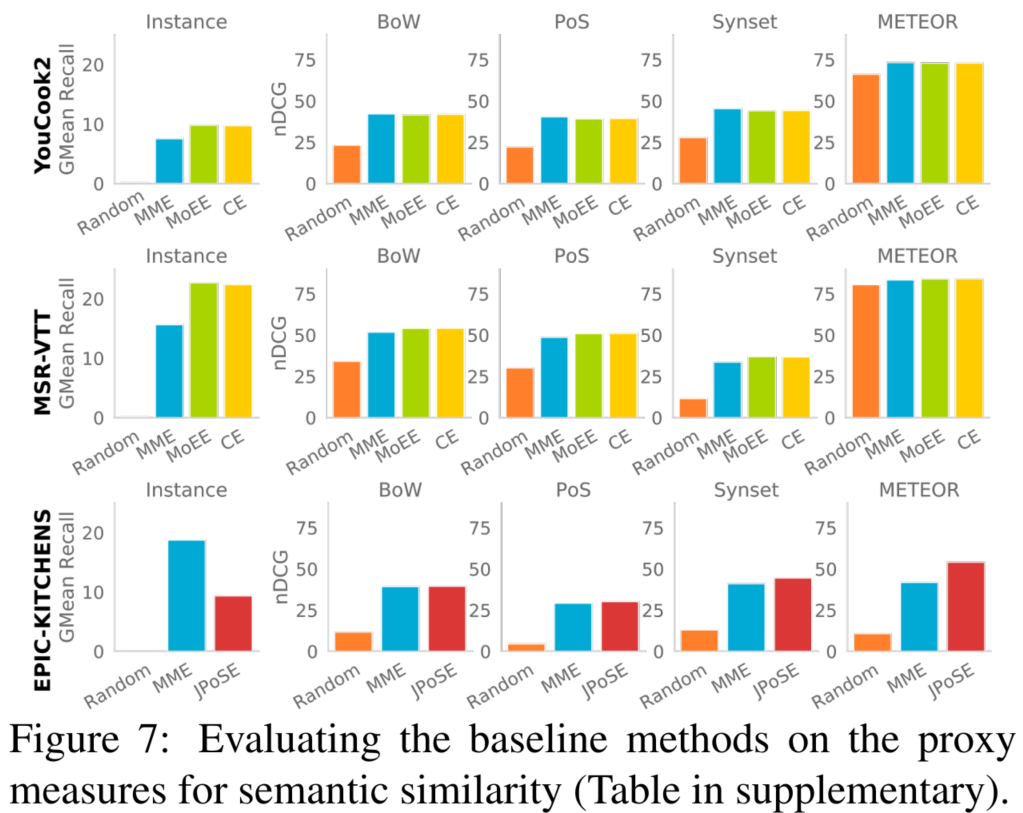
마무리하며
해당 논문은 기존 벤치마크의 문제점을 지적하였다.
해당 논문에서 중요한것 중 하나는 CVPR21에 해당 논문이 Accept 되었다는 점인듯 하다. 평가 지표의 문제점을 공식적으로 인정하면서 앞으로 해당 문제점을 반영한 평가지표가 더욱 인기를 끌 것이라고 생각된다. video to caption 검색 뿐 만 아니라, video to video 검색에서도 기존의 instance based similarity(gt가 서로 연관관계없이 유일하다)는 지양하고 semantic similarity video retrieval 지표를 더 추구할 것 이라 예측된다.
결과적으로 이 논문에서 제시하는 것이 동영상 당 단일 라벨을 사용하는 것은 학습에 악영향을 끼치니 멀티라벨로 가자는 것 같은데 맞나요..? 그럼 제가 이해한바가 맞다면, 기존에 단일 라벨로 주어진 데이터셋을 멀티라벨로 변경은 어떻게 한건가요 ? 그리고 학습할때 S score 란 것을 새로 정의해서 Loss로 사용했다는 것으로 이해하면 될까요?
Caption에 대한 좀 더 자세한 설명을 해주 실 수 있나요?
해당 논문은 특정 네트워크를 제안한 것이 아닌 semantic similarity에 대해 정의한 논문이 맞을까요?