오늘 논문은 저번 CornerNet에 이은 CenterNet입니다. CornerNet을 기반으로 생성한 모델로 기존 CornerNet의 단점을 보완한 Anchor Free 기반 Object Detection 방법론입니다.
Introduction
기존 Anchor 기반의 방법론은 사전에 정의한 크기의 직사각형 박스(anchor box)를 이미지에 배치하고, GT를 이용하여 원하는 위치 및 크기의 box를 구하는 과정을 가진다. 그러다 이런 Anchor 기반의 방법론은 다음과 같은 단점이 있다.
- 많은 수의 anchor가 필요하다.
- anchor box의 크기를 직접 설정해주어야 한다.
- anchor box의 픽셀과 convolutional feature가 서로 misalign 되어 정확하지 않다.
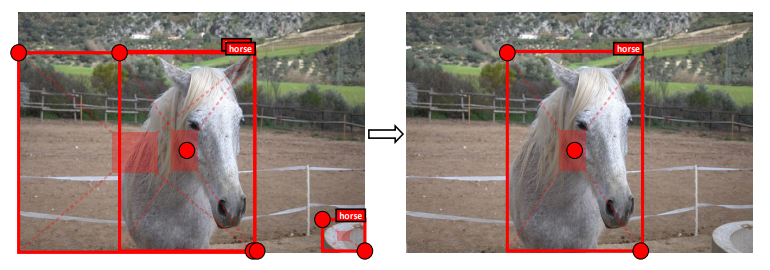
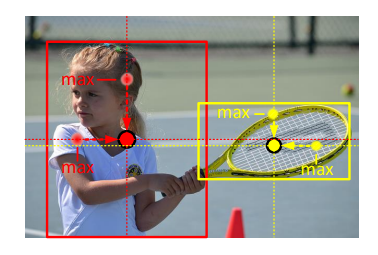
이 단점을 극복하고자 CornerNet이라는 방법론이 제안이 되었는데, 한 쌍의 keypoint(object의 left-top, right-bottom 점)를 이용하여 각 object를 나타내는 방법이다. (자세한 과정은 이전 CornerNet 리뷰를 참고해주세요) 그러나 CornerNet에서의 keypoint는 그림 1과 같이 object의 외부에 존재하므로 (1) object의 내부 패턴 및 정보가 없어 global한 정보를 활용하는 데에는 제한적이고, (2) left-top 점과 right-bottom 점은 bounding box의 edge를 예측하는 데에만 민감하게 반응하기 때문에, 각각의 keypoint를 서로 동일한 object에서 발생했다고 그룹화하는 정보가 부족하기도 하다. 그 결과 그림 2와 같이 부정확한 bounding box를 생성하기도 한다.


따라서 본 논문에서는 object의 정보를 활용할 수 있도록 keypoint가 생성한 region에서의 중심점 정보를 활용한 CenterNet을 제안한다. CenterNet은 예측된 바운딩 박스가 GT box와의 높은 IoU를 가진다면, 중앙 region의 class는 GT와 동일한 class를 가질 확률이 높을 것이라는 것을 이용한다. 즉, 두 쌍의 특징점으로 예측한 바운딩 박스의 중심 구역에 존재하는 중심점이 실제로 GT와 동일한 Class 인지를 확인한다. 그림 3에서 볼 수 있듯, 각 개체를 나타내는 keypoints 한 쌍이 아닌 세 점을 사용하여 bounding box를 예측하는 것이 CenterNet의 메인 아이디어다.
이를 위해 본 논문에서는 개선된 성능을 위해 Center와 Corner에 object에 대한 정보를 더 많이 가지도록 2가지의 방법을 제안한다. 자세한 방법론은 뒤에서 자세하게 알아볼 것이다.
- Center Pooling
- center 점을 예측하는데 사용된다.
- Cascade Corner Pooling :
- 기존 CornerNet에서의 Corner-Pooling보다 object의 내부 정보를 더 많이 가질 수 있도록 개선된 방법
- precision and recall 모두 향상
CenterNet
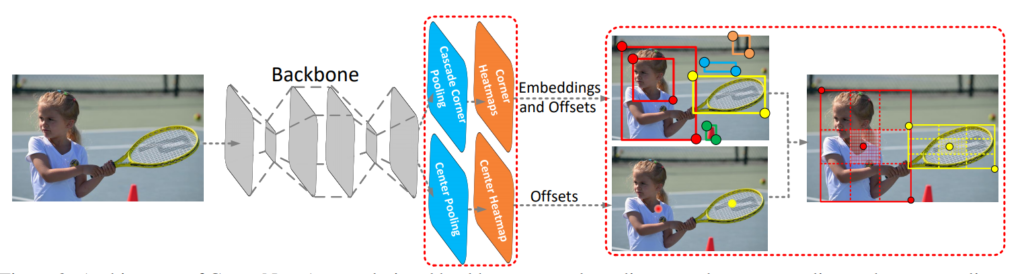
Baseline
CenterNet은 CornerNet 기반의 모델이다. CornerNet에서는 backbone의 output을 통해 두 개의 heatmap이 생성된다. 하나는 left-top heatmap, 나머지 하나는 right-bottom heatmap 이다. 각 keypoint에 대한 confidence score 역시 할당된다. 그리고 ConerNet은 서로 다르게 추출된 각 점들이 하나의 object로부터 생성된 것임을 알려주는 embedding과 heatmap을 원래 input image의 크기로 remap할 때 정보손실을 최소화하기 위해 offset을 예측한다. ( CornerNet의 동작 원리는 기존 리뷰를 참고하시면 이해가 용이합니다 ! )
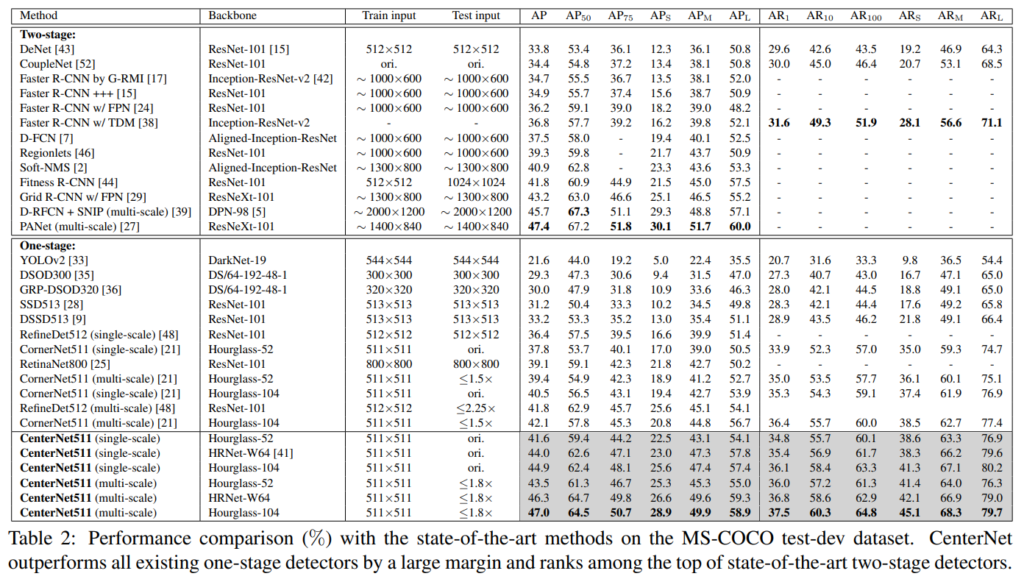
표 1에는 MS-COCO validation dataset에 대한 False 발생 비율에 대한 정량적 평가가 나타난다. 이를 통해 CornerNet은 낮은 IoU threshold 에서도 잘못된 bbox를 다수 생성해낸다. 심지어 작은 bounding box에서는 60.3%라는 높은 비율의 incorrect 한 bounding box를 생성해낸다. 논문에서는 이 원인이 CornerNet이 bounding box의 내부 영역을 평가할 수 없기 때문이라고 한다. 따라서 CenterNet은 ConrerNet의 keypoint를 그대로 사용하면서 object의 내부 영역도 같이 평가할 수 있도록 center 점까지 총 세 개의 점을 사용한다.
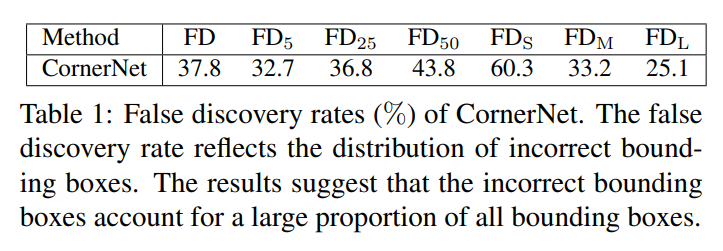
FD = 1 − AP, where AP denotes the average precision at
IoU = [0.05 : 0.05 : 0.5] on the MS-COCO dataset.
Object Detection as Keypoint Triplets
중심점을 예측하기 위해 CornerNet에서 중심점에 대한 heatmap와 offset을 예측한다. 이 때 incorrect한 bbox를 효과적으로 필터링하기 위해 center keypoint를 활용하며, CenterNet의 동작원리는 다음과 같다.
- score가 높은 k개의 center keypoint를 선택한다
- 이 center keypoint를 input image에 다시 mapping한다. ( 이 때, offset을 사용 )
- top-left, 그리고 right-bottom keypoint를 이용하여 생성한 bbox의 center region을 정의한다.
- 정의된 center region에 center keypoint가 있는지 확인한다.
- 이 때, center keypoint가 GT의 class가 동일하고 중심 구역에 존재한다면, 해당 bbox를 유지한다.
center region에 center keypoint가 존재하지 않거나, class가 동일하지 않다면 해당 bbox는 삭제한다. - 그리고 bbox의 score은 3개의 keypoints의 score의 평균으로 대체된다.
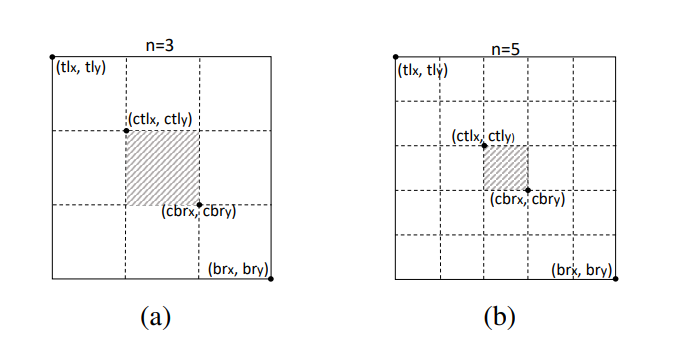
이 때, bbox의 central region 크기가 detection 성능에 큰 영향을 준다. 크기가 작으면 작은 bbox의 recall이 작아지고, 반대로 central region의 크기가 크다면 큰 bbox의 precision이 작아진다. 따라서 적절한 central region의 크기를 설정해야하는데, 본 논문에서는 이를 위해 scale-aware central region을 제안한다. scale-aware central region은 작은 bbox에서는 상대적으로 큰 central region을, 큰 bbox에는 상대적으로 작은 central region을 생성하는 경향이 있다. central region을 발생시키는 관계는 수식 1.에 나와 있다.
( 본 논문에서는 n을 150보다 작거나 큰 경계 상자 눈금의 경우 각각 3과 5로 설정하였다. 그림 5는 각각 n = 3 및 n = 5일 때 두 개의 중심 영역을 보이는데, 수식 (1)에 따라 scale-aware central region 확인 후 central region에 center keypoint가 포함되어 있는지 여부를 확인할 수 있다. )
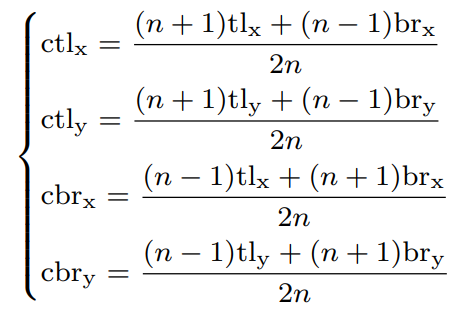
Enriching Center and Corner Information
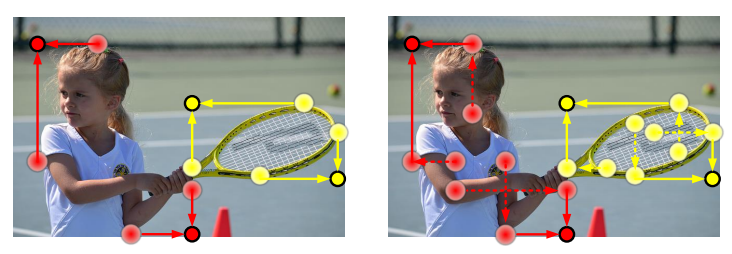
Center Pooling. object의 기하학적 중심은 object를 대표하는 visual pattern을 전달하지 않는다. ( 예를 들어, 전신의 사람 이미지가 있을 때, 머리는 명확한 visual pattern을 포함하지만 보통 중심점은 몸 쪽에 존재 ) 따라서 이런 문제를 해결하기 위해 풍부하고 더 인지할 수 있는 visual pattern을 캡처할 수 있는 Center Pooling을 제안한다. 그림 6과 같이 Center Pooling은 backbone이 생성한 feature map에 존재하는 center keypoint를 찾기 위해 수평, 수직 방향의 max 값을 탐색 후 다 더한다.
Cascade corner pooling.
Cascade corner pooling은 left-top, 그리고 right-bottom의 keypoint를 찾는 방법이며, CornerNet에서 사용하는 corner pooling을 보완한 것이다. 기존에는 object의 경계에 존재하는 pixel의 max 값을 활용했다면, Cascade corner pooling은 object bbox의 안쪽 정보까지 활용한다. 그림 7에서의 왼쪽은 Corner Pooling의 예시이고, 오른쪽은 지금 제안한 Cascade corner Pooling의 방법이다. Cascade corner pooling 동작원리는 다음과 같다.
- boundary를 따라 최대 boundary 값을 찾는다.
- box 내부의 max 값을 찾는다.
- 그리고 두 최대값 다 더해 두 개의 keypoints를 찾는다.
이를 통해 object의 visual patterns와 boundary information 둘 다 가진 corner를 얻을 수 있다.
Training and Inference
Inference Speed
CenterNet은 최소한의 비용으로 제안된 각 영역 내의 시각적 패턴을 탐색한다. NVIDIA Tesla P100 GPU에서 CornerNet과 CenterNet의 추론 속도를 테스트를 해본 결과는 다음과 같다.
- CornerNet 511-104 vs CenterNet 511-104
- 평균 추론 시간 : 이미지 당 300ms / 이미지 당 340ms
- CenterNet 511-52
- 각 이미지를 처리하는 데 평균 270ms가 소요. -> CornerNet 511-104보다 빠르고 정확
그림 8은 CenterNet에 대한 정성적 평가를 보여준다.

Cascade corner pooling 부분에 대해 질문해도 될까요?
박스 내부의 max값을 찾아서 이용한다고 설명해주셨는데 안에서 max값을 골라 left top과 right bottom을 찾는다면 경계값을 이용해 left top과 right bottom을 찾는 것 보다 부정확할 수 있지 않을까요?
질문해주셔서 감사합니다.
CenterNet은 CornerNet 의 모델로 코너점을 찾는 것은 동일합니다.
그러나 기존 CornerNet에서 코너점을 찾는 방식인 Corner Pooling은 경계에만 민감할 뿐 object에 대한 global한 정보가 없기 때문에, 코너점이 부정확한 경향성을 띄게 됩니다. 따라서 이를 개선하고자 CenterNet에서는 Cascade corner pooling을 제안하였습니다.
질문주신 것과는 달리 내부의 점만을 사용하여 코너점을 찾는 것이 아니라,
내부의 점과 경계의 점을 동시에 활용하는 것입니다.
그 결과 object 에 대한 global 한 정보도 함께 참조할 수 있기에 논문에서는 Enriching Corner Information 이라고 표기하더군요. 질문에 답변이 되었기를 바랍니다.