이번에 리뷰할 논문은 CVPR 2021 OPEN ACCESS 페이퍼이며 object detectio관련 논문입니다. Object detection에서 주로사용되는 NMS 없이 네트워크를 구성하였고, 뭔가 general하게 사용될 수 있을 전략일거 같아서 한번 읽어보았습니다.
해당 논문에서는 기존에 존재하던 object detection에서는 prior을 여러개 만들고 Non Maximum suppression(NMS)을 통해 false positive를 제거하는 방식을 사용하였는데 이러한 방식은 fully 미분가능한 end-to-end network를 만드는데 방해요소로 작용한다고 말합니다. 그래서 end-to-end network만을 이용해서 object detection을 하기위해 NMS 없이 네트워크를 구성하는 방법을 취합니다. 그게 이 논문에서 핵심적인 전략이고, 이를 돕는 3D 필터링 기법을 사용합니다.
With these techniques, our end-to-end framework achieves competitive performance against many state-ofthe-art detectors with NMS on COCO and CrowdHuman datasets.
결론적으로 위에서 언급한 NMS를 떼어내고 One-to-one prediction을 취하는 전략과 3D max filtering 기법을 통해 NMS를 사용하던 SOTA모델들과 competitive한 결과를 얻었습니다. 평가는 COCO데이터셋과 CrowdHuman 데이터셋을 사용하였으며, 자세한 방법론에 대해서는 아래에서 좀 더 자세히 다루어보고 일단은 배경적인 얘기부터 해보겠습니다.
NMS는 휴리스틱하게 threshold를 설정하고 해당스코어기준으로 prior를 드랍해서 false positive를 제거하는 방식으로 아무래도 휴리스틱하게 설정해야하는 파라미터가 존재한다는 단점을 가집니다. 이에 기존 연구들에서도 NMS를 제거하기위한 시도들이 있었습니다. 예를들어 BBOX를 직접적으로 바로 예측하고, end-to-end learning으로 네트워크를 구성하는 방법들이 제안되었지만, 여전히 performance에서는 많이 떨어지고, small dataset에서만 validation을 하였기 때문에 설득력있는 결과가 없었습니다. 그리고 최근에는 DETR같은 소타 디텍터는 최근 대세인 attention 기법을 적용하여 기존의 prior를 많이 뽑는 one-to-many 방식이 아닌 one-to-one prediction을 하였고, end-to-end learning까지 가능하게 하였습니다. 그러나 DETR은 예측결과가 많은경우에 시간이 오래걸렸고, 작은물체에 성능이 떨어졌으며, 데이터셋이 큰경우 training duration이 오래 걸린다는 문제점들이 있었습니다. 해당 논문에서는 그러한 문제점들을 야기시키기 않으면서 fully differentiable이며 end-to-end network를 제안합니다.
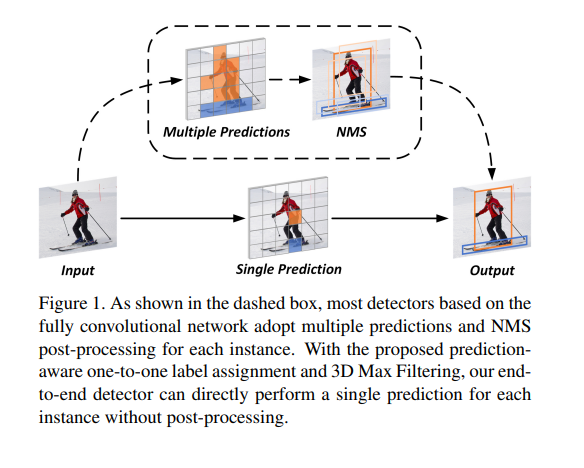
그래서 티저영상인데 해당 그림이 의미하는 바는 위에 dotted line으로된 box는 기존의 nms 과정을 통한 prediction을 이야기하고있는 것이고, 아래는 해당논문에서 사용하는 one-to-one, 즉 single prediction 방식입니다. 차이점이라고하면 기존에는 prediction값을 sliding윈도우를 태우는 방식으로 쭉 스캔하며 multiple prediction을 하였는데, 해당 논문에서 제안하는 방식은 only single prediction만을 하여 false positive를 제거하는 nms과정을 할 필요가 없다는 것에 있습니다.
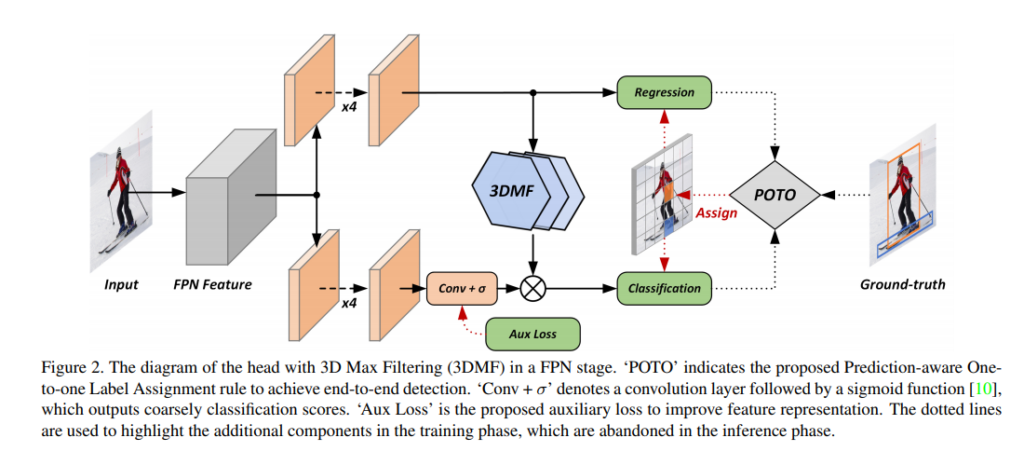
먼저 위에 아키텍쳐를 보시면 유명한 방법론중 하나인 FPN에서 나온 feature를 사용하여 feature를 뽑고 그를 이용하여 object detection framework를 구성하였습니다. 일단 기본적으로 regression과 classification을 하기위해 2개의 branch로 분리하여 feature를 보내주게 됩니다. 그리고 일반적인 cnn구조를 가지는데 특이한 component들이 몇몇개 추가되었습니다.
우선 가장 핵심적인 contribution인 3DMF라는 모듈이 가운데 있는데 이는 3D max pooling의 약자로 밑에서 다시 다루겠습니다. Inference를 할때는 점선영역이 사라지고, training할때는 점선도 포함하여 GT값을 이용한 loss를 최적화시키는 방향으로 학습합니다.
Prediction 결과를 보시면 1군데씩 prediction값이 나온것을 볼 수 있는데 이는 Prediction-aware one-to-one 방식을 취하는 해당 네트워크의 주요 특징입니다. One-to-one label assign을 하는 과정에서는 regression과 classification의 퀄리티를 보고 sample을 뽑습니다.
아래쪽을 보시면 Aux loss가 있는데 해당부분에 대해서는 Reference paper를 citing해두고 자세한설명이 생략되어있어서 일일이 다 읽어보진 못하였지만 컨셉적인면으로 one-to-many label assignment 방법론들에서 사용되는 이점을 가져가기 위해 loss텀으로 반영하였다고 이해했습니다. 즉, one-to-one은 less supervision이라 performance가 아무래도 좀 떨어지는데 이를 극복하기위해 loss텀을 정의한 것 입니다.
요약하자면 핵심적으로 one-to-one label assignment방식, 3DMF모듈, Aux loss텀을 설계하여 NMS없이도 비슷한 성능을 내는 네트워크를 구성한것이 해당 논문의 핵심 기여입니다.
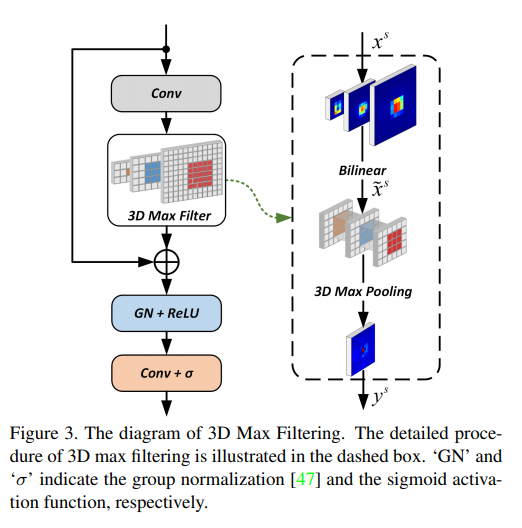
해당부분은 3D Max filtering이란 모듈로 아래의 불필요한 activation을 좀 더 없애주고, 필요한 것만 남기는데 사용됩니다. 원리는 a rank-based non-linear filter의 max filter를 사용하는 것으로 regional한 영역에서 불필요한 값들을 제거하는데 이용됩니다. 이러한 방식은 CenterNet이나 CornerNet에서도 사용되는 방식인데 해당 논문에서 제안하는 아키텍쳐에서는 feature를 FPN으로 뽑아냅니다. 그래서 동일하게 적용하는 것이 힘들었고, 이를 3D 화 하여 pyramid 형태의 feature에도 적용할 수 있도록 하였습니다. 그래서 최종적으로 제안하는 3D max filtering이 나옵니다. 아래 visualization된 결과를 보시면 이해가 좀 더 쉬울거 같아서 가지고 왔습니다.

결과를 보시면 기존이 위고, max filtering이후가 아래입니다. regional한 영역에서 activation map이 바뀌었음을 알 수 있습니다. 즉, 불필요한 false positive가 사라졌고, 이를통해 nms과정을 거치지 않아도 되게 된 것 입니다.
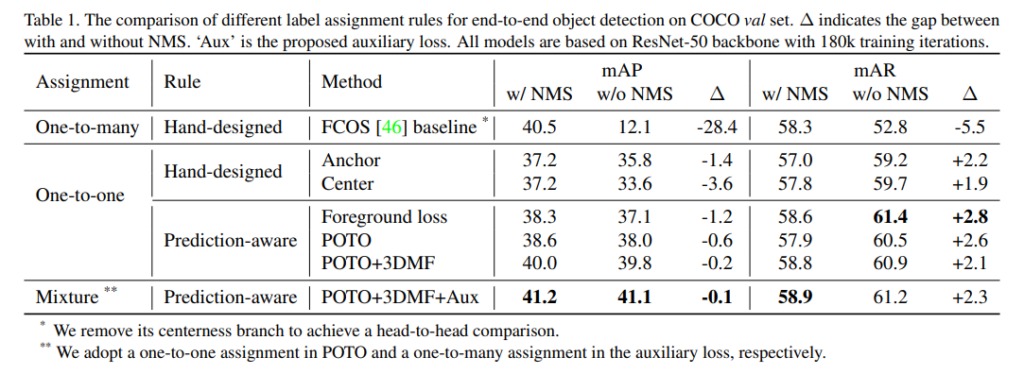
해당 논문의 프레임워크는 FCOS와 흡사하기 때문에 이를 베이스라인으로삼고 비교실험을 한 결과입니다. 기존에 NMS를 사용하는 FCOS와는 달리 one-to-one label assignment, 3D max pooling, aux loss를 이용하여 nms를 제거하였고, 이 3가지가 모두 포함되었을때, coco데이터셋에서 FCOS보다 더 좋은 성능이 나왔습니다. 이는 곧 nms를 사용하지 않고도 비슷하거나 더 좋은 성능을 낼 수 있다는 소리입니다.
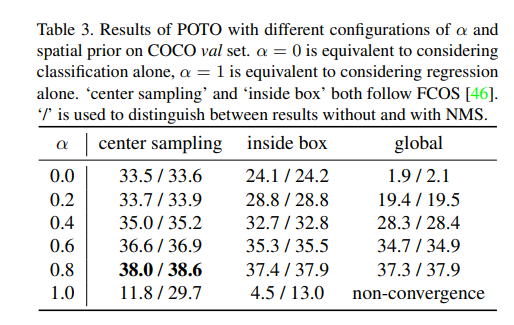
그밖의 ablation study에서 참고하는 regression과 classification의 비중에 따른 spatial prior의 성능에 대한 분석입니다. 해당 논문에서는 reg와 cls의 quality에 따라서 one-to-one label을 assign하였기 때문에 그 quality를 보는 비중을 다르게하는 알파값의 차이에 대한 분석을 한것이고 0.8 일때, 가장 높았습니다. 그리고 해당 결과에서 center sampling을 하는 이유는 베이스라인으로 사용한 FCOS논문을 잠깐 살펴본결과 prediction값을 4D의 벡터로 내뱉는데 이때 그 4개의 차원중 한개가 center값이기 때문입니다.
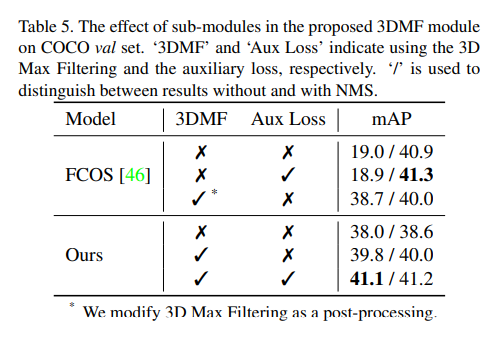
위의 또다른 ablation study의 결과를 보면 제안하는 모델에서 nms를 사용하지 않고 sub-module들이 모두 적용되었을때, FCOS베이스라인에서 Aux loss만 적용되고 nms를 사용하였을때와 0.2밖에 차이가 안납니다.
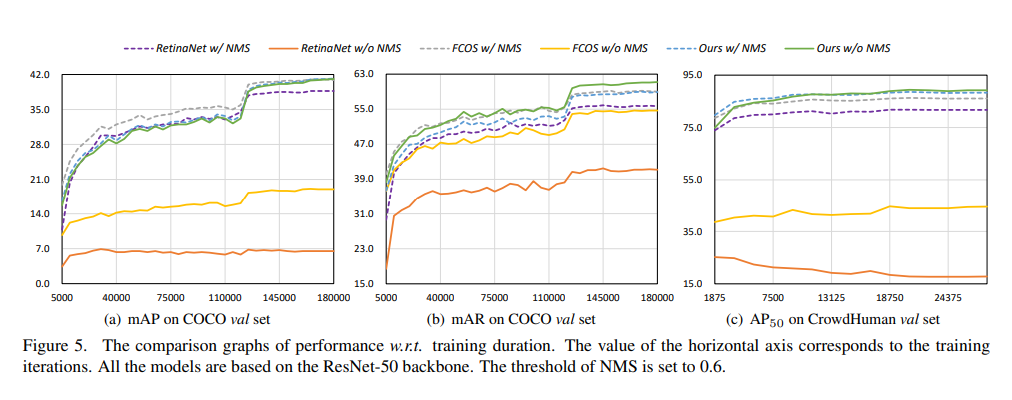
Ours w/o NMS이 다른 nms를 포함하는 방법론들과 견줄만한 성능을 보여주기 위한 plotting결과입니다.
전체적인 총평으로 전체적으로 논문의 흐름을 파악하는건 어렵지않았지만, reference만 걸고 일부분은 설명이 생략된 부분이 많아서 디테일한 부분까지 이해하기에는 진입장벽이 높았던거 같습니다. 앞으로 근 몇달간 revisit을하며 멀티스펙트럴 od쪽만 팔거같아 아마도 x-review도 그쪽으로 작성하지 않을까 싶습니다. 일단은 이번에는 일반적인 od였는데 다음부턴 multispectral쪽도 한번 리뷰해보는 시간을 가져보겠습니다.
안녕하세요 좋은 리뷰 감사합니다
물체의 중심을 기준으로 detection을 진행한 것으로 이해하였는데
물체의 디테일을 잡는 정도까지 기존 성능을 유지하였나요? 그러한 분석이 혹시 논문에 있는지 알고싶습니다..!
둘째로 figure2의 POTO 모듈이 GT를 해당 모델의 결과값에 맞추어 변환 해주는 부분으로 이해했는데 해당 부분은 어떻게 진행되는지 알고싶습니다
감사합니다
리뷰 잘읽었습니다. 몇가지 질문 드리겠습니다.
1. “ One-to-one label assign을 하는 과정에서는 regression과 classification의 퀄리티를 보고 sample을 뽑습니다.” 해당 내용에서 퀄리티의 의미가 POTO와도 이어지는 부분으로 추측되어 집니다. POTO와 함께 어떻게 얻어지는지 조금만 더 자세한 설명 부탁드려도 될까요?
2. 3DMF에 대해 궁금한 점이 있습니다.
2-1. 무엇을 3d로 사용하는 것인가? Regression에서 내려오는 모듈이라 w, h, cx, cy라고 추측했지만 이러면 4차원이니깐 아니고…
2-2. 왜 3d max pooling을 사용하는 것인가? 설명 혹은 해당 부분에 대해 ablation study가 있는지 궁금합니다,