오늘 리뷰로 작성할 논문은 CVPR2021에 통과된 HistoGAN입니다. 제목만 보셔도 알 수 있다시피, Color 히스토그램을 이용해 만들고자 하는 영상의 색상을 조절하는 논문으로 보입니다.
Introduction
기존의 Color Transfer 방법론들 중 GAN을 이용해 Image based Example 방식이 대부분 좋은 결과들을 보이곤 했었습니다. 하지만 이 방법은 입력 영상과 출력 영상의 의미론적 유사성을 닮게끔 하는 것에 너무 집중한 나머지 Color 뿐만 아니라 텍스쳐 정보같은 것들도 닮게끔 하는 경우가 종종 보이곤 했습니다.
그래서 저자는 오직 영상의 Color 정보만을 이용해 새로운 영상을 생성해보자! 라는 목표를 가지고 해당 HistoGAN을 제안하게 됩니다. 이 모델은 Target 영상이 필요하지 않으며, 단지 Target 영상에서 추출한 Color Histogram만을 가지고 새로운 영상을 생성할 수 있게 됩니다.
즉 오직 컬러 정보만을 사용하기 때문에 입력 영상과 Target 영상 사이에 Texture나 심지어 Content같은 의미론적 유사성이 닮아지는 문제가 현저히 줄어들겠죠?
Histogram feature
일단 Histogram Feature에 대해서 먼저 알아봅시다. Histogram은 잘 알다시피 영상의 픽셀 값들의 분포를 나타낸 것입니다. 흑백영상에 대해서 히스토그램을 계산하면 0~255 분포를 가지는 막대 그래프 형식으로 표현할 수도 있겠구요, 컬러 영상에 대해서 히스토그램을 표현한다면 각 채널별(R,G,B)로 0~255 분포를 가지는 막대 그래프 3개를 만들 수도 있을 것입니다.
이 논문에서는 영상의 컬러값들을 Log-chroma Space로 투영시켜서 2D 히스토그램을 만들었습니다. 이 Log-chroma Space는 하나의 채널을 주 채널로 정의한다음에, 다른 두 채널로 normalize 함으로써 정의할 수 있습니다.
저자는 R, G, B 각 채널에 대하여 위에 방법을 모두 적용하여 3개의 칼라 히스토그램을 생성하고 이를 모두 합쳐서 Histogram Feature를 생성하였습니다. 즉 H = h \times h \times 3의 Tensor를 생성한 것이죠.
Log-chroma Space로 투영시키는 방식에 대해서 조금 더 자세히 알아보자면, 먼저 입력 영상 \bold{I}에 대하여 주 채널을 정해야 합니다. 해당 예시에서는 R 채널을 주 채널로 정한다면 나머지 두 채널(G, B)를 통해 주 채널을 normalizing해주어야 하며 이는 다음과 같습니다.
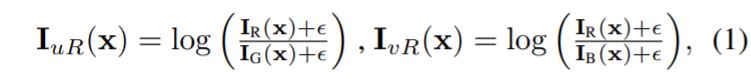
먼저 R, G, B는 당연하게도 입력 영상 \bold{I}의 각 컬러 채널을 의미하며, \epsilon 은 수식적 안정성을 위해 추가하는 아주 작은 상수(1e^-6)입니다. x, uR, vR 는 각각 픽셀 인덱스와 주 채널인 R의 uv 좌표계를 의미합니다.이러한 방식으로 주 채널이 G, B인 경우 \bold{I_{uG}}, \bold{I_{vG}},\bold{I_{uB}},\bold{I_{vB}}를 구할 수 있게 됩니다.
여기서 한가지 중요한 점이 있습니다. 히스토그램을 Feature로 사용하기 위해서는 반드시 미분이 되어야만 하지만, 아쉽게도 일반적인 히스토그램은 미분이 불가능한 형식입니다.(저도 그래서 히스토그램을 영상 생성에 사용하고 싶었지만 이 부분에서 막혀 적용을 제대로 못해보았죠 주륵..)
그래서 저자는 RGB-uv 히스토그램이 미분가능하도록 하기 위해 아래와 같이 Kernel Weighted Contribution 연산을 사용했다고 합니다.
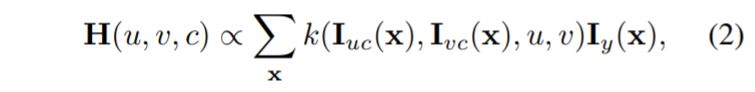
c는 R, G, B 각 채널들을 의미하며 k(\dot) 는 Pre-trained Kernel을 의미합니다. 해당 커널은 가우시안 커널을 사용해도 무방하나, 저자는 특별히 아래 수식과 같이 정의된 Inverse-quadratic Kernel을 사용했다고 합니다.
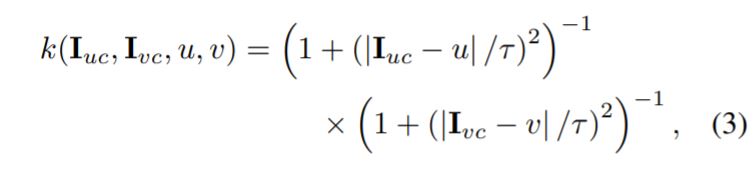
\tau 는 히스토그램의 빈의 스무딩을 결정하는 파라미터 입니다. 이러한 Inverse-quadratic Kernel을 사용하게 된 이유는 해당 커널이 학습 안정성을 많이 향상시켜주기 때문이라고 그러네요.
아무튼 수식(2)를 통해 생성된 Histogram feature \bold{H}는 아직 normalize가 되지 않은거라, 마지막으로 normalize를 적용해 모든 값이 다 더하면 1이 되게끔 만들어주면 끝이나게 됩니다.
Color-controlled Image Generation
제안하는 모델의 구조는 StyleGAN의 구조를 본따왔다고 보시면 될 것 같습니다.
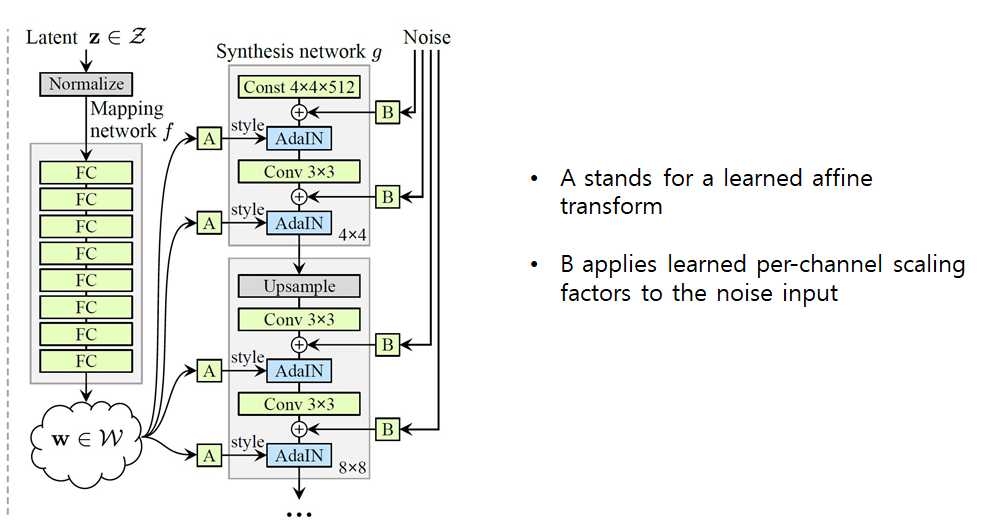
StyleGAN은 워낙 유명하나 모르시는 분들을 위해서 잠깐 설명을 드리자면 위의 그림과 같이 Latent code z를 바로 입력으로 사용하는 것이 아닌, FC layer를 여러번 태워서 새로운 임베딩 공간으로 투영시킨 후 각 block별로 Adaptive Instance Normalization을 수행하여 생성하고자 하는 영상의 스타일을 해석 가능하도록 만든 방법론입니다.
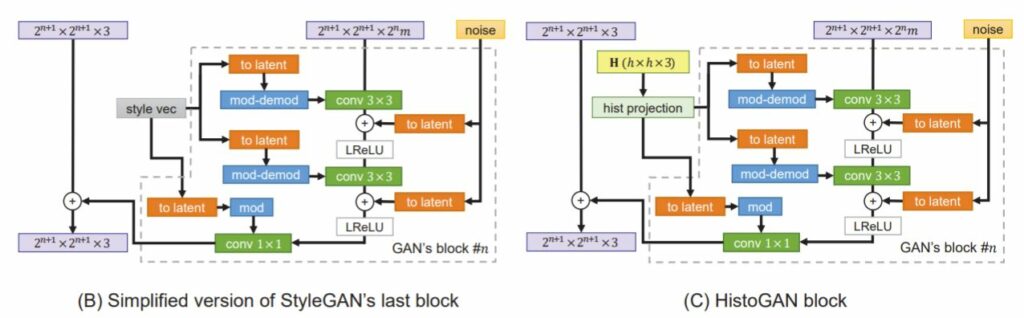
여기서 HistoGAN은 기존 StyleGAN이 Style Vector를 AdaIN하는 것을 참고하여 마지막 2개의 Block에서만 Style Vector 대신 Histogram Feature를 사용하고자 했습니다.
해당 Histogram Feature는 먼저 Hist Projection이라는 8개의 FC Layer로 구성된 네트워크를 통과하여 저차원 공간으로 새로 투영되게 됩니다. 이는 아무래도 StyleGAN이 Latent code z를 FC Layer를 8번 태워서 새로운 Latent code w를 만들고자 한 것과 동일한 것으로 판단됩니다.
그 후에는 위에 그림 속 주황색 블록에 해당되는 “to latent” 블록으로 통과하게 되는데, 이는 각 블록의 latent space에 히스토그램을 투영시키는 의미를 가진다고 보면 될 것 같습니다. 해당 블록은 단일 FC Layer로 구성되어 있으며 출력되는 벡터의 차원은 2^{n}m입니다. (n은 블록 개수를, m은 네트워크 전체 용량을 통제하는 파라미터)
Loss Function
HistoGAN에서 학습을 위한 Loss Function은 크게 Discriminator를 통해 판별되는 real/fake 값, 생성된 영상의 히스토그램과 Target 영상의 히스토그램을 비교한 값으로 총 2개의 목적함수를 사용합니다.
논문에서 제안하는 Histogram Feature는 미분이 가능하므로 두 히스토그램의 차이를 비교할 수 있는 어떠한 loss를 사용해도 상관이 없습니다. 논문에서는 아래 수식과 같은 Hellinger Distance를 사용했다고 합니다.
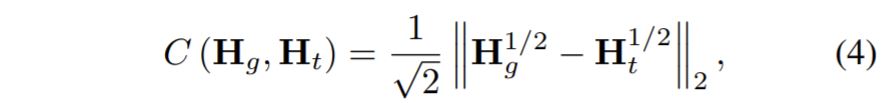
먼저 element-wise square root를 취한 두 히스토그램에 대해 Euclidean Norm을 계산한 후 다시 2의 제곱근을 나눠주게 됩니다. 그래서 최종적으로 Loss 함수는 다음과 같이 표현할 수 있겠네요.
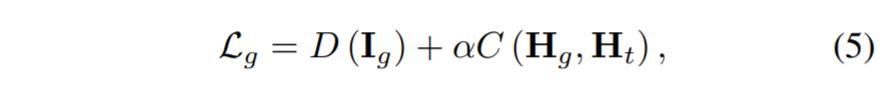
D(\bold{I_{g}})는 Discriminator를 통해 계산된 loss 값입니다.
여기서 한가지 중요한 점이 존재합니다. 수식(4)를 자세히 살펴보시면 생성된 영상의 Histogram( H_{g})과 타겟 영상의 히스토그램(H_{t})을 비교하게 되는데요. 여기서 타켓 영상의 히스토그램은 어떻게 만드면 될까요?
이러한 히스토그램 GT를 만들어주기 위해, 저자는 학습 데이터 셋으로 부터 랜덤하게 두 장의 영상을 선택한 후 각각의 히스토그램( H_{1}, H_{2}를 계산하였다고 합니다. 이렇게만 하면 아 그냥 단순히 랜덤하게 골라서 비교하는구나 라고 생각하실 수 있으시겠지만, 여기서 중요한 작업을 하나 더 진행하게 됩니다. 바로 두 타켓 히스토그램에 대하여 랜덤하게 보간을 진행하는 것입니다.
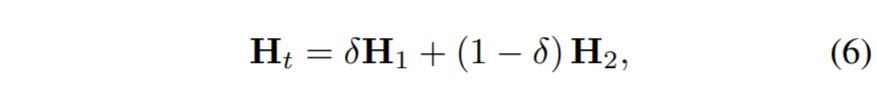
위에 식(6)이 바로 보간을 진행하는 방식에 대한 수식입니다. 원래 히스토그램이 다 더하면 1이 된다고 했었죠? 그래서 델타 값을 통해 두 히스토그램을 적절히 섞더라도 총합이 1이 되도록 하는 것으로 델타 역시 0~1사이에 값을 가지게 됩니다.
이러한 과정은 학습 영상의 히스토그램에 과적합되는 현상을 방지하여 새로운 영상으로 추론할 때 좋은 결과를 보인다고 합니다.
아무튼 결과적으로 이렇게 Target 영상의 히스토그램 분포와 생성된 영상의 히스토그램 분포가 유사해지도록 모델은 학습하게 되며 아래 그림과 같이 Target 영상이 무엇이 주어지냐에 따라 영상이 새롭게 생성되는 모습입니다.

Experiments
다음은 실험 결과입니다.
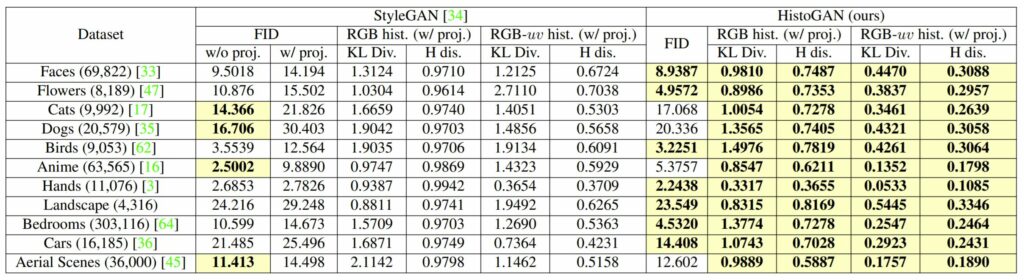
아무래도 HistoGAN이 StyleGAN의 구조에서 Histogram Feature를 사용하는 기법을 새로 추가하다보니 실험 리포팅도 기존 StyleGAN과 비교하는 모습입니다. 먼저 첫번째 열은 Image Generation을 하고자 하는 카테고리를 나타낸 것이며, 평가 메트릭으로는 FID 그리고 RGB, RGB-uv 히스토그램이 있습니다. FID를 제외한 두 히스토그램 메트릭은 생성된 영상과 Target 영상의 히스토그램에 대하여 Hellinger Distance와 KL Divergence를 계산하여 color error 값을 추정한 것입니다.
또한 표를 잘 보시면 w/proj이라고 적혀있는데, 이는 StyleGAN에서 Color Histogram Projection을 시켜 StyleGAN이 생성된 영상의 color를 잘 통제할 수 있는지를 보고자 한 것이라고 합니다.
저자는 ResNet을 학습시켜서 생성된 영상을 다시 Fine-style Vector로 변환시키게끔 하였으며 해당 Fine-style Vector는 StyleGAN의 마지막 두 블록 내에서 AdaIN을 통해 사용되게 됩니다.
아무튼 결과를 살펴보시면 HistoGAN이 대부분의 Dataset에서 FID 성능이 좋은 모습을 보이고 있으며, 생성된 영상과 Target 영상의 히스토그램 에러의 경우 모든 데이터셋에서 월등히 좋은 모습을 보이고 있습니다.

다음은 정성적인 결과입니다. 첫번째 열은 Target 영상이며 이를 통해 생성한 이미지들이 2번째 열부터 존재하게 됩니다. 타겟 영상의 컬러 히스토그램에 맞추어 생성되는 영상들의 색도 알맞게 잘 적용된 것을 확인할 수 있습니다.
결론
해당 논문은 생성하고자 하는 영상을 히스토그램 분포로 접근하여 보다 사실적으로 영상을 생성하고자 하였습니다. 해당 논문을 고르게 된 이유는 아무래도 영상의 히스토그램 분포를 닮게하면 열화상 영상 역시 RGB 영상을 잘 만들 수 있지 않을까 라는 생각을 가지게 되어 히스토그램을 적용하는 연구에 관심이 많았기에 읽어보게 되었습니다.
히스토그램이 미분이 불가능하다는 점으로 인하여 많은 어려움이 있었던 찰나에 해당 논문을 통해 다시 한번 히스토그램을 이용한 영상 생성 방법을 적용해볼 수 있을 것 같네요. 또한 해당 논문은 StyleGAN이 다양한 Style을 조절하여 새로운 영상들을 만들 수 있긴하지만, 이는 구조적 관점에서 잘 동작하지 Color 관점에서는 제대로 해내지 못한다는 것을 잘 보이기도 합니다.
마지막으로 이 논문은 저가 리뷰에서 설명한 내용 외에도 Image Recoloring에 대하여 깊이 있게 다루고 있습니다. 궁금하신 분들은 한번 읽어보시면 좋을 듯 합니다.
좋은 리뷰 감사합니다. 그림3에서 보면 색을 입히는 타겟영상은 어떤 이미지 영상인가요? 다시말하면 타겟으로 gray 이미지가 주어져도 되는건가요?? 색의 히스토그램이 유사하게 한다는건 기존의 밝기변화 같은 정보가 포함된 이미지가 있어야 기존 이미지의 정보를 통해서 히스토그램이 유사하도록 변경이 가능할 것 같은데, 열화상에서 나타는 픽셀변화는 조도나 색에 영향이 없는 온도차이에 의한 것이라서 열화상 영상에도 이러한 내용을 적용할 수 있을지 궁금합니다.
그림 3번의 예시에서는 색을 입히는 타겟 영상이 따로 존재하지 않습니다.
이는 StyleGAN과 같이 Latent space에서 임베딩 벡터를 가져와 새로운 영상을 생성하는 것이기 때문에 Colorization처럼 회색 영상을 입력해서 컬러를 입히는 그런 개념은 아닌 latent vector를 통해 새로운 영상을 생성할 때, 생성하고자 하는 영상의 색 분포를 지정한다고 생각하시면 좋을 것 같습니다.
이 때문에 열화상 영상을 target으로 하여 색 분포를 따라가게 하기는 다소 어려울 듯 싶으나, 영상의 컬러 히스토그램을 source 영상에 맞추어서 학습시킨다는 컨셉을 이용하면 다른 방법론들에 비해 더 좋지 않을까 합니다.