아카이브 : https://arxiv.org/pdf/2103.16237.pdf
깃허브 : https://github.com/xinzhuma/monodle
Introduction
해당 논문은 단일 이미지 기반으로 3D Object Detection을 수행할때, 성능향상을 저지하는 가장 큰 요인중 하나인 ‘Localization error’에 대해 설명하고 수치적으로 분석하고 있습니다.
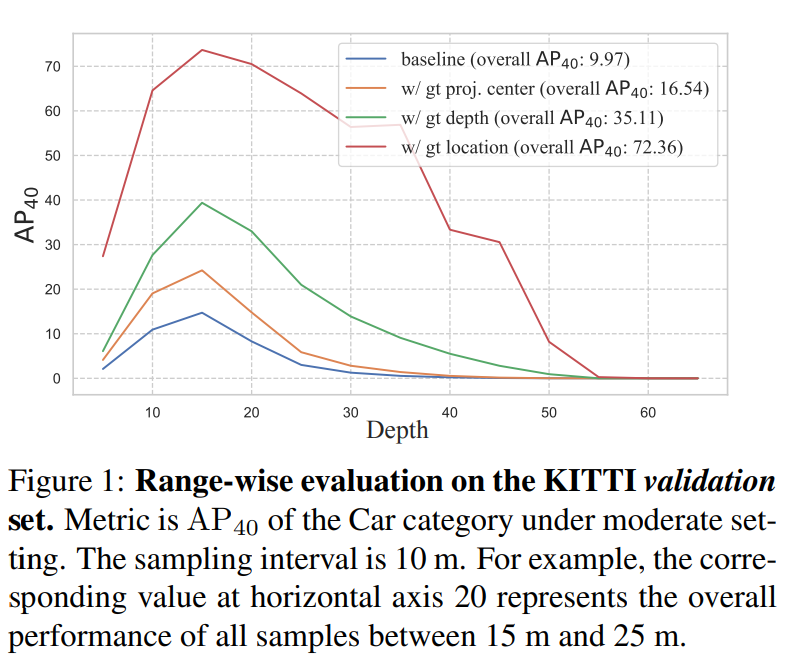
위에 그림을 보시면 AP(40)에서 베이스라인은 9.97%이지만 projected center GT, depth GT, location GT 등을 사용하면 성능이 크게 향상하는 것을 확인할 수 있습니다. 다시말하면 GT에 가까운 projected center, depth, location을 예측할 수 있다면 위의 그림과 같은 성능향상을 이룰 수 있음을 이야기 합니다. 특히 location의 관점에서 GT와 매우 유사한 prediction이 가능하다면 가장 큰 폭의 성능 향상을 이룰 수 있습니다. 하지만 현재 제안되던 단일 이미지 기반의 3D Detection은 localization error를 줄이지 못해서 성능향상에 한계가 있었다고 저자는 설명합니다. 즉 localization error를 줄이는게 단일 이미지 기반 3D Detection을 수행하는데 키가 됩니다.
여기서 잠깐 해당 내용에 대해서 과거 비슷한 내용을 포함했던 논문을 리뷰했던 적이 있습니다.
3D와 2D의 center gap을 줄이려는 align conv를 제안한 M3DSSD
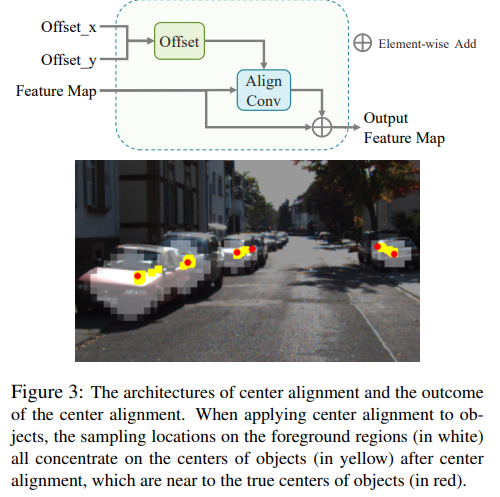
동일한 내용을 담았던 Monocular Quasi-Dense 3D Object Tracking
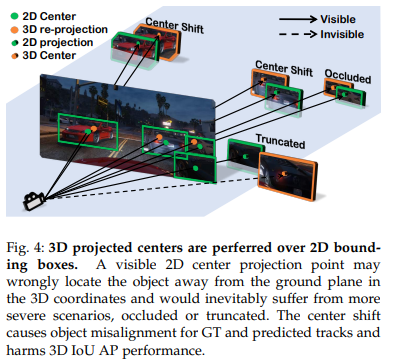
이외에도 많은 논문들이 있습니다. 그렇다면 해당 논문에서 주장하는 자신들의 차별점은 무엇일까요? 저자는 다음과 같이 설명합니다.
In this work, by intensive diagnosis experiments, we quantify the impact introduced by each sub-task and found the ‘localization error’ is the vital factor in restricting monocular 3D detection.
설명하기에 앞서 해당 논문에서 나타낸 수식들에서 사용하는 변수들을 알아보겠습니다. 그냥 c는 coarse center로 본 논문에서 사용하는 detection 모델의 백본인 Centernet의 결과로 나오는 스코어맵에서 뽑은 센터지점 입니다. 그리고 c^(i)는 2D 이미지에서의 center이며, c^(w)는 3D 물체의 센터입니다.
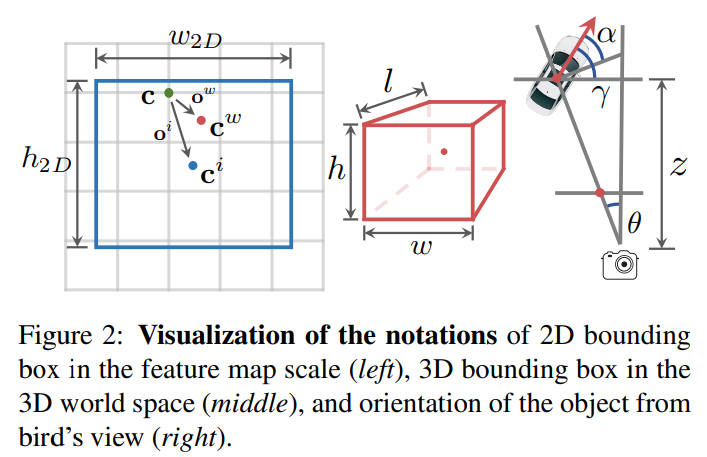
그리고 이에대한 실험은 다음과 같이 표로 나타내는데…
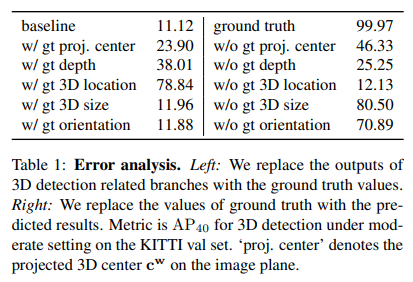
본 논문의 내용이랑 다른 수치라서 표가 잘못된것 같은데.. 저자는 논문에서 다음과 같이 이야기합니다.
As shown in Table 1, if we replace projected 3D center c predicted from baseline model with its ground-truth, the accuracy is improved from 11.12% to 18.97%. On the other hand, depth can improve the accuracy to 38.01%.
설명하면 project 3D center c^(w)의 값을 모델이 예측한게 아닌 GT를 입력했을때 정확도가 11.12%에서 18.95로 향상했다고 합니다. (근데 위에는 99.97%로 되어있네요..) 또한 depth도 38.01%로 향상했다고 합니다.
이처럼 3D Detection을 진행하는데 각 부분들을 GT 값으로 대체하여서 성능이 어느정도까지 오를 수 있는지 확인하고 이를 각 sub-task에 맞춰 성능을 비교 분석한 것이 contribution 중 하나에 속합니다. 추가로 여기에 더해서 실제 center 값을 쉬프트하여서 성능 차이가 어느정도까지 나타나는지 확인하였습니다.
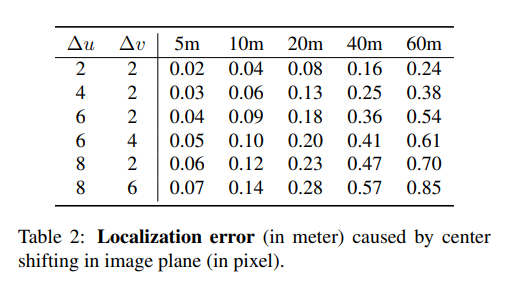
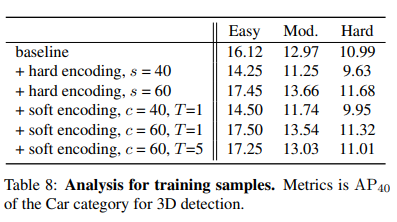
해당 표는 location shift에 따른 inaccurate center detection 성능을 나타냅니다. 거리가 멀어질수록 조금만 shift가 발생하여도 부정확성이 증가하는 것을 알 수 있습니다. 저자는 이러한 분석을 토대로 coarse center c에서 3D center와 2D center를 estimate 하기위한 offset을 예측하는 center detection을 제안합니다. 저자는 이를 통해서 2D와 3D 특성 모두를 배울 수 있다고 합니다. 동시에 거리가 멀리있는 object에 대해서는 학습과정에서 제거하는 형태의 학습방식을 이야기합니다. (Training Samples) 이때 거리의 기준은 60m로 설정하였고, hard coding과 soft coding 2가지 스키마를 이용해 설계하였습니다.

마지막으로 IoU Oriented Optimization을 제안하였는데, 해당 부분에 대해서는 추후에 다시 설명드리겠습니다. (다른논문과 함께)
Experimental Results
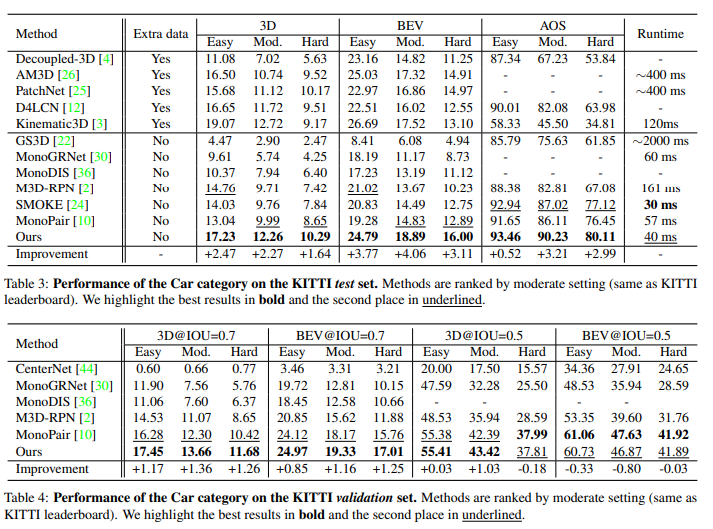
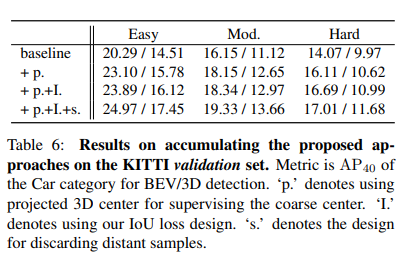
페이퍼의 contribution이 revisit하여 기존 mono기반 방법론들의 localization error의 문제에 대해 지적하고, 이를 해결하기위한 localization error를 야기하는 sample들을 제거하는 방법론과 localization error에 영향을 덜 받는 3D IoU oriented loss를 제시하였다고 요약할 수 있나요?