저는 이번 CVPR 2021 Workshop에서 주최하는 Depth Estimation 대회에 참가하게 되었습니다. I2I task를 구준히 하다가 갑자기 챌린지에 참여하게 된 이유는 좀 새로운 도전을 잠깐 해보고 싶다는 생각이 들어서 참여 하게 되었습니다.
이번 챌린지에서 제공하는 데이터셋은 DDAD(Dense Depth for Autonomous Driving) 으로 소개할 논문에서 공개된 데이터셋입니다. 이 데이터셋과 함께 공개된 방법론이 Self-Supervised 이고 Semi-Supervised 에서 실험도 해서 그런지 대회도 두가지 테스크로 나눠서 성능을 체크합니다. 저는 Self-Supervised를 먼저 시도 해볼 예정 입니다. 그 외에 데이터셋에 0대한 설명은 아래에서 다루도록 하겠습니다.
그럼 이 챌린지에서 베이스로 다루고 있는 방법론과 데이터셋에 대해서 알려드리겠습니다 : )
이 논문에서는 크게 세가지의 contribution이 있고 다음과 같습니다.
- PackNet이라는 Depth Estimation을 위한 새로운 뉴럴 아키택쳐를 제안합니다. packing과 uppacking 블록을 제안하며 이는 3D 컨볼루전을 활용해 조밀한 외관과 기하학적 정보를 최대한 학습할 수 있도록 합니다.
- 카메라의 스케일이 모호한 모노큘라 비전의 문제를 해결 하기 위한 새로운 Loss를 제안함
- DDAD를 공개함. 멀티카메라와 long range Lidar를 calibration을 제공하며 다양한 방법으로 평가해봄
Method
- Self-Supervised Scale-Aware SfM
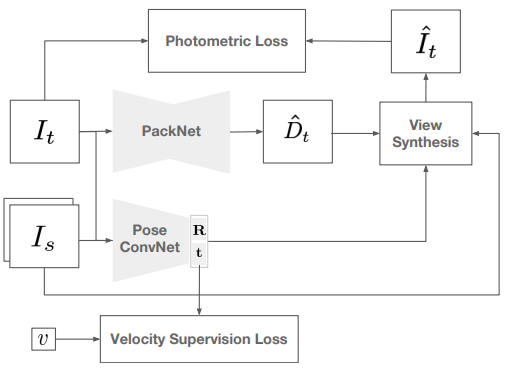
제안된 모델 PackNet의 아키텍쳐는 다른 최근 Self-Supervised Depth Estimation 방법론들과 동일한 양상을 띄고 있다. 보면 기준 영상을 생성 모델로 Depth를 얻고 기준 영상의 앞뒤 영상을 PoseNet에서 얻은 pose정보를 이용해 기준영상을 생성하고 비교를 한다. 이 아키텍쳐에서 다른 모델들과의 차별점은 뎁스 생성보델 PackNet과 보다 정확한 Rt 생성을 위한 Velocity Supervision Loss라고 보면 된다. Loss 또한 Velocity Supervision Loss외에는 monodepth2와 거의 동일하다고 생각하면 된다.
1.1 Scale-Aware SfM
기존 방법론에서 사용됐던 Depth 와 Ego motion을 이용한 방법론은 모호한 scale factor만을 추정가능하다. 이는 전체 로스 계산에 많은 영향을 끼치며 성능 저하를 일으킵니다. 이러한 문제를 막기 위해서 제안된 방법이 Velocity Supervision Loss이다.
최근 많은 시스템들은 순간 속도정도는 잴 수 있는 센서를 갖추고 있다 따라서 속도를 이용한 로스 설계는 유의미하다고 한다. 따라서 예측된 translation 즉 위치 값들과 GT로 실제 속도 값을 이용하는 것은 가능하다고 할 수 있다. 그럼 속도를 어떻게 이용했는지 보면 다음 식을 보면된다.
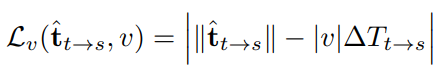
t 햇은 predict된 값이고 T는 실제 translation 값이다 이것에다가 실제 속도값을 곱해서 예측된 값의 scale까지 고려할 수 있게 된다.
2. PackNet: 3D Packing for Depth Estimation
많은 CNN 방법론들은 Receptive field 를 늘리기 위해 공격ㅈ인 stride와 pooling을 사요한다. 하지만 이는 결국 성능 저하를 일으키며 특히 Depth estimation이나 Segmantation 같은 pixel level prediction에서는 많은 성능 저하를 보인다. 이를 해결하기 위한 네트워크를 이 논문에서는 제안한다. 제안된 방법론은 Packing과 unpacking block을 사용해 깊이 추정에 필요한 공간정보손실을 막는다. 이는 최근 모델의 점진적인 확장과 수축은 광범위하게 성능을 향상시킨다는 연구를 바탕으로 한다.
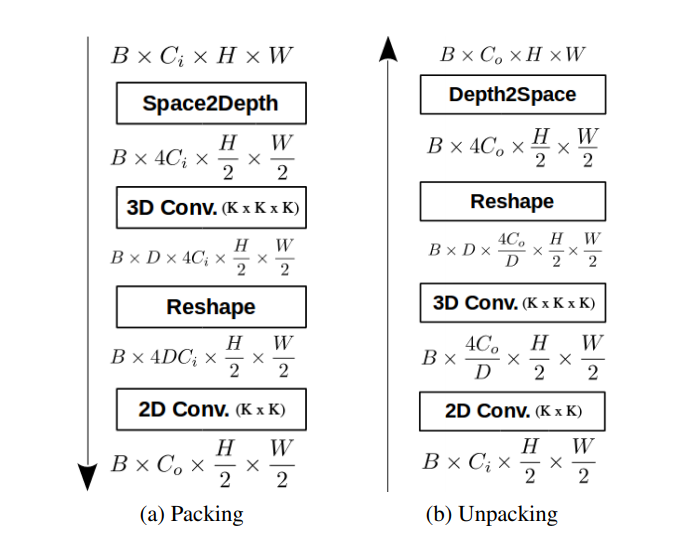
2.1 Packing Block
Packing block은 Space2Depth를 이용해 영상이 feature공간으로 가는 것으로 시간 한다. 이 결과는 stride와 pooling과는 반대로 손실이 없다. 그 다음 공간을 압축하기 위한 방법으로 여러 실험을 통해서 3D conv를 사용하는 것이 더욱 손실을 막는 다는 것을 알아 냈고 이를 적용한 아키텍쳐를 제안했다.
2.2 Unpacking Block
packing block과 반대로 Decode를 진행하여 손실을 최대한 막으며 Depth를 Estimation 하게된다.
3. DDAD


다양한 도시에서 촬영된 이 데이터셋은 한가지 뷰의 카메라만이 아니라 자동차 주위로 여러 대 카메라 뷰를 제공하며 그와 동시에 그에 맞는 라이타데이터를 제공한다. 또한 모든 카메라는 calibrate 됐다.
총 17050장의 학습데이터 그리고 4150 장의 평가 테이러를 제공한다. 물론 전면 카메라 기준이다. 이 데이터셋은 다른 데이터셋들 보다 현실적이며 Dense lidar를 이용한 평각를 제공한다.
3. Result
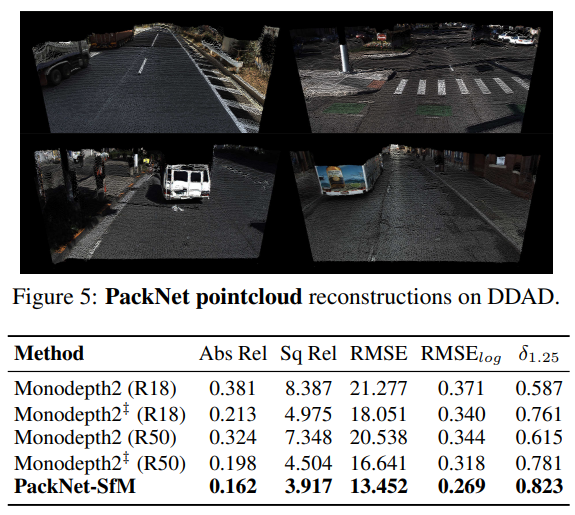
당시 self supervised depth estimation에서 SOTA라고 할 수 있는 Mondepth2 와 비교한 성능 평가이다. DDAD 데이터셋에서 했으며 이 성능을 넘는 것이 일단 내 목표라고 할 수 있겠다.
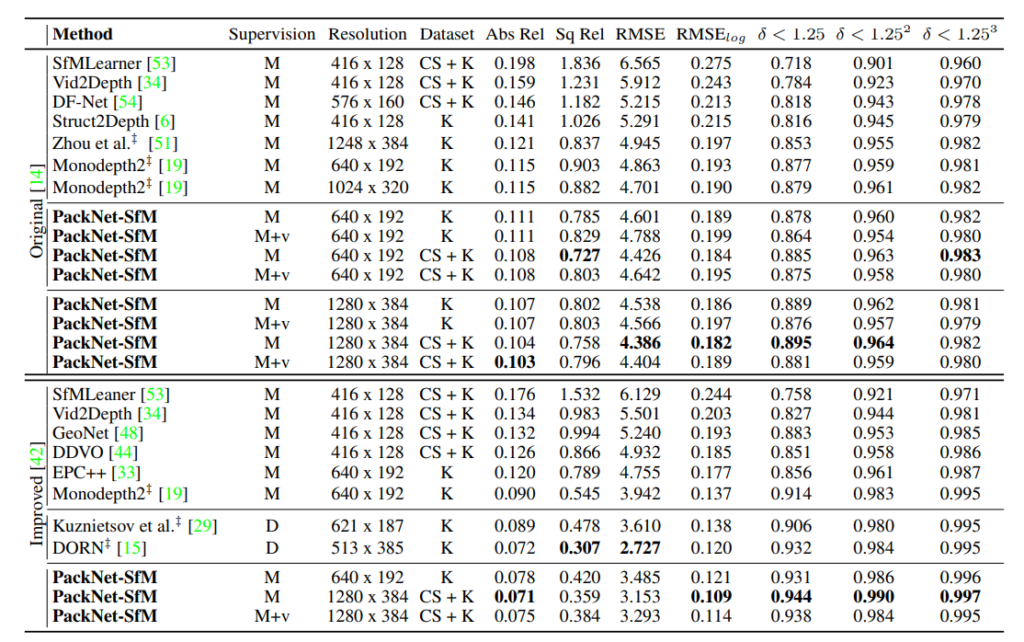
KITTI에서 다른 방법론들과 비교해도 좋은 것을 알 수 있다.
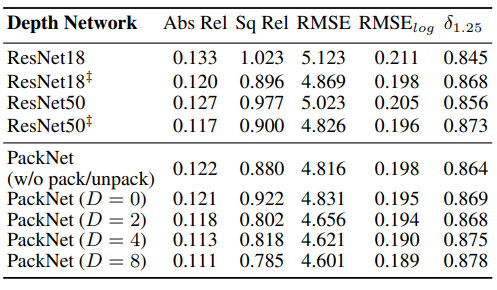
PackNet의 Ablation Study 결과이다. 단순히 Resnet을 사용했을 때와 packing을 점점 넣을 수 록 성능이 향상 되는 것을 볼 수 있다.
글 잘 읽었습니다.
몇 가지 질문드리겟습니다.
1. poseNet을 통해 R,t를 추정하여 가상의 뷰를 만들어 depth에 활용하는 방법이 해당 방법론이 처음이였나요?
2. Velocity Supervision Loss 수식에서 v를 고려한는 것이 어떻게 scale의 모호성을 줄이는 건지 좀 더 자세히 설명 부탁드립니다.
3. Packing block이라는 방법이 3D feature 에서 2D feature 로 reshape하여 연산한다는 것인가요? 제목이 ‘packing for…’인데… 될 수 있다면 추가적인 설명 부탁드립니다.