오늘 리뷰도 즐거운 I2IT(Image to Image Translation)논문을 가져왔습니다. Abstract 내용을 살펴보면 proxy task를 사용한 style encoder를 제안한 점과, multi modal I2IT task에 사용되는 서로 다른 loss term의 효과등을 연구했다고 하네요.
Introuduction
I2IT에 대한 설명은 이전 리뷰들에서부터 계속 다루었던 얘기라 넘어가도록 하고, Multi-modal Image Synthesis에 대해서 조금 알아봅시다.
Multi-modal Image Synthesis는 쉽게 말해, 하나의 입력 영상으로 다양한 도메인의 영상을 만들고 싶은 것입니다. 어찌보면 I2IT랑 같은거 아닌가 싶기도 하시겠지만, 조금은 다른게 일반적으로 I2I는 A 도메인에서 B 도메인으로 변환시키는 one to one mapping이라, 하나에 모델이 A에서 B, C 또는 D 등 한번에 다양한 도메인으로 변환을 하지 못합니다.
그정도의 차이가 있다는 것만 알아두시면 될 것 같고, 아무튼 Multi-modal Image Synthesis를 하기 위해서 가장 일반적인 방식으로는 Generator에 입력으로 입력 영상 뿐만 아니라 어떠한 조건을 같이 넣어주는 방식입니다.
이러한 추가적인 입력으로 가장 쉽게 생각할 수 있는 것은 랜덤한 노이즈일텐데, 이러한 랜덤 노이즈는 효과적으로 multi-modal 결과를 생성하지 못한다고 합니다. 이는 Generator가 입력에 함께 들어간 노이즈를 무시한 채로 학습되어 특정 도메인들에 대한 결과가 붕괴되는 mode collapse 문제가 발생한다고 합니다.
그래서 BicycleGAN은 I2IT 네트워크와 더불어 Encoder network E를 함께 학습시키는 방법을 제안하였습니다. 이는 Generator의 입력으로 random noise 대신, E에서 나온 latent vector z를 입력으로 넣기 위함이며, 해당 z는 Generator가 생성 가능한 서로 다른 출력 영상의 분포를 표현하고 있습니다. BicycleGAN은 supervised 형식이기에, MUNIT이나 DRIT이 BicycleGAN의 컨셉을 가지고 unsupervised 형식으로 만들었구요.
하지만 이러한 방법론들도 문제는 존재하겠죠? 바로 상당히 복잡하다는 것입니다. 예를들어 BicycleGAN은 conditional Variational AutoEncoders (cVAEs)과 conditional version of Latent Regressor GANS (cLR-GANs)의 loss를 모두 합쳐야하며, MUNIT이나 DRIT의 경우 여기서 추가로 unsupervised 학습을 위한 setup들을 더 추가해야 할 것입니다.
즉 고려해야할 loss들도 많고, 네트워크도 복잡하니 고쳐야할 하이퍼 파라미터들이 많으며 동시에 해당 파라미터들을 세세히 조절하지 못하면 학습 결과가 좋지 못한다고 합니다.
그래서 해당 논문의 저자는 weakly-supervised 방식의 사전학습 전략을 제안합니다. 해당 전략은 multi-modal I2IT을 위한 latent space가 효과적으로 학습될 수 있게끔 하는 방법으로, 다음과 같은 이점들이 존재합니다.
- 사전학습된 latent space는 학습 데이터 셋에서 잘 표현하지 못한 드문 스타일도 캡처할 수 있으며, 복잡한 스타일 보간을 통해 더 좋은 스타일 표현이 가능합니다.
- 학습된 style embedding은 target dataset에 의존적이지 않아서 multi domain들을 잘 표현할 수 있다고 합니다. 이는 학습 데이터가 제한적인 경우에 특히 더 유용하게 동작합니다.
- 스타일에 대한 사전 학습은 더 적은 목적 함수를 사용함으로써 학습의 속도를 빠르게 하며, 목적에 대한 복잡성을 낮춥니다.
또한 제안된 스타일 사전 학습은 weakly-supervised이며 어떠한 메뉴얼 labeling이 필요하지 않다고 합니다. 대신에 사전 학습이 된 VGG network로 부터 label을 받아서 지도학습을 진행한다고 하네요.
즉 방대한 양의 supervised dataset(Image Net)을 통한 visual recognition이나 unsupervised task와 같은 proxy task를 사전에 학습한 후, 우리가 하고자 하는 I2IT task로 fine tune 하는 것입니다.
Method
제안하는 방법론의 전체적인 흐름에 대해서 가볍게 알아봅시다. 먼저 저자의 목표는 출력 영상이 다양한 도메인의 분포를 모델링할 수 있도록 하는 latent embedding을 효과적으로 학습시킴과 동시에, 학습 과정에서 사용하는 objective들을 최대한 간단하게 해보자는 것이죠.
그래서 일단 저자는 스타일의 정의는 기존 Neural Style Transfer에서 사용하던 Gram matrix를 가져왔다고 합니다. 하지만 gram matrix를 스타일로 바로 사용하기에는 상당히 고차원이기에 바로 사용하지는 않았습니다.
대신에 I^{B} 영상의 스타일을 포착하는 임베딩 벡터 z = E(I^){B}를 최적화하기 위해 보조적인 task를 수행하는 인코더 네트워크를 분리하여 학습시켰다고 합니다. 이렇게 사전 학습된 latent space를 시각적으로 보면, 제안하는 방법론의 인코더는 마치 유사한 스타일을 가지는 영상들끼리의 군집처럼 출력 영상의 분포를 잘 모델링합니다.
그러고 나서, 영상을 합성하기 위해 Genrator에 입력 영상과 latent vector z를 넣게 되면 끝이죠.( \hat(I^{B}) = G(I^{A}, z)) 해당 논문에 전체 파이프라인은 다음과 같습니다.
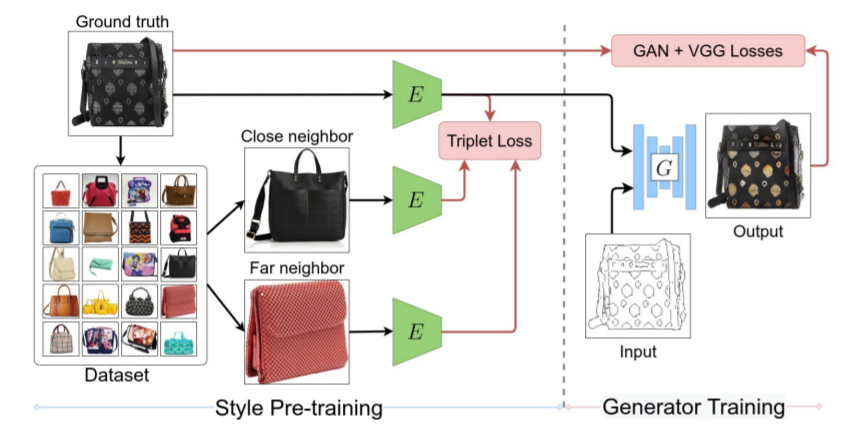
먼저 첫번째로 출력 도메인 B에서의 영상 임베딩을 저차원 style latent space로 최적화하는 proxy task를 통해 Encoder를 사전학습 시킵니다. 이러한 style latent space는 유사한 스타일의 영상들이 가깝게 분포하는 군집화된 공간으로 생각하시면 될 듯 합니다.
그 후에 고정된 인코더 E를 가지고 Generator G를 학습시킵니다. G는 출력 영상의 스타일과 style embedding z를 연관 짓는 방식을 학습합니다.
마지막으로 E와 G 네트워크를 동시에 finetune하게 되는데, 이는 타겟 도메인에 대한 영상 합성 목표가 알맞게 합성되도록 스타일 임베딩을 재조정 하는 것으로 보시면 됩니다.
Weakly-supervised encoder pre-training
인코더 E를 사전 학습하는 것의 목표는 바로 타겟 영상 I^{B}의 스타일로부터 latent style code z로 맵핑하는 것입니다. 이러한 style latent space를 정의할 때 가장 이상적인 것은, 영상들의 스타일이 유사하면 조밀조밀하게 뭉쳐있고, 서로 다르면 멀리 떨어지도록 하는 것이겠죠?
그래서 저자는 임베딩을 지도 학습하기 위하여, style loss에 대해 distance metric을 사용하였으며 이를 통해 두 영상 사이에 스타일 유사성을 추정하였습니다. 그리고 나서 스타일 인코더 네트워크 E는 triplet loss를 사용하여 학습하는데, 이는 입력이 3장의 영상( (I_{a}, I_{p}, I_{n})[l/latex]이며 이때 [latex] I_{a}, I_{p}는 서로 스타일이 유사하고, I_{a}, I_{n}는 다른 스타일을 보유하고 있습니다.
E의 학습을 위한 목적함수는 다음 수식과 같습니다.
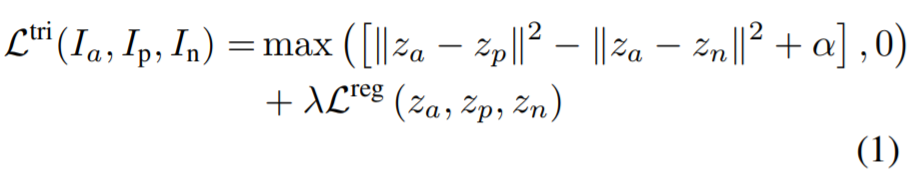
\alpha, \lambda 는 각각 margin과 loss 가중치에 대한 하이퍼 파라미터입니다.
Triplet selection
자 그러면, triplet loss를 사용하기 위해서 anchor에 대한 positive와 negative를 어떻게 구분지으면 좋을까요? 논문에서는 각각의 앵커 영상 I_{a} 과 style loss를 계산함으로써, k_{c}개의 가장 가까운 이웃들과 k_{f}개의 가장 멀리 떨어진 이웃들의 집합을 구했다고 합니다.
그 다음에, 각각의 앵커 영상 I_{a}에 대하여, 위에서 구한 closet, furthest 집합에서 랜덤하게 positive 영상과 negative 영상을 샘플링하였습니다.
위에 과정이 만약 방대한 데이터셋에서 진행할 경우 각 영상들마다 style loss 계산을 진행해야하므로 시간적으로 무리가 있지 않을까 싶은데, 저자는 자신들이 해보니깐 괜찮다고 합니다.
다만 한가지 문제점으로 고려할 것이, outlier에 속하는 스타일을 가진 영상들을 어떻게 처리할 것인지 입니다. 이러한 outlier image들은 대부분 가장 멀리 떨어진 이웃 영상들에 속하게 되는데, 이렇게 되면 모델이 단순히 outlier image들을 분리된 군집으로 투영함으로써 잘못된 학습을 진행할 수 있게 됩니다.
이를 해결하고자, 저자는 방대한 furthest neighbors 집합으로 부터 negative style image를 다시 샘플링하였으며, 반대로 positive image는 closet neighbors의 작은 집합으로부터 샘플링했다고 합니다.
이게 무슨 말일까 곰곰이 생각을 해보니, furthest neighbors 집합안에는 outlier style에 속하는 영상들이 종종 분포하고 있을테니, 보다 의미있는 negative 영상들을 선정하기 위해서 집합의 크기를 크게 예를들어(50개 furthest neighbors set) 중 1개를 고르면 10개의 furthest neighbors set에서 1개를 뽑는 것보다 outlier가 뽑힐 확률이 줄어들게 될 것입니다.
반대로 positive의 경우는 크기가 작은 closest neighbors set에서 뽑아야 스타일이 anchor image와 가장 유사한 아이들끼리 학습을 할 수 있겠죠?
Generator training
Style Encoder를 학습시키고 나면, 이제 다음 단계로는 Generator를 학습시켜야 한다고 했었죠? Generator는 출력 도메인의 영상으로부터 맵핑된 style embedding z = E(I^{B})를 입력 영상 I^{A}와 함께 입력 받습니다.
이러한 style embedding이 입력으로 함께 들어가는 방식은, generator가 output image의 스타일을 이와 대응되는 스타일 임베딩과 연관지어 학습시키는 것이며, 단순히 style을 모방하는 기존의 방식과 비교하였을 때 보다 좋은 효과를 볼 수 있다고 합니다.
영상과 그들의 스타일 사이에 결정적인 대응관계를 유지하는 것은 generator가 이러한 연관성을 발견하도록 하는 작업을 수월하게 만들어줍니다. 그래서 저자는 stage 2단계(Generator 학습) 동안에 style encoder의 weight를 freeze 시킨 이유이기도 합니다.
Generator가 초기에 학습하는데 있어 style latent code z와 output style의 연관성을 배워야하는데 이때 style latent ode가 매번 달라지면 Generator의 학습에 어려움이 발생하기 때문이죠. Generator의 목적함수는 pix2pix와 유사하게 진행됩니다.
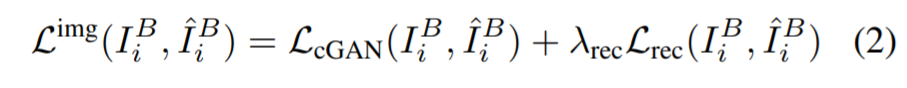
먼저 Least Square GAN(LSGAN) loss를 L_{cGAN}로 사용하였으며, reconstruction term L_{rec}으로는 VGG 기반의 perceptual loss를 사용하였습니다. 한번 generator가 input style embedding을 output style로 연관지어 학습한다면, stage 3에서는 G와 E 모두에 대해 다시 2번 목적 함수를 통하여 finetuning을 하게 됩니다.
Style Sampling
Inference를 할 때, 존재하는 영상을 가지고 style embedding z를 뽑아서 영상을 생성하시면 되겠지만, 주어진 영상 없이 sample style을 통해 곧바로 영상을 생성하고 싶을수도 있습니다. 이를 하기 위해서는 unit Gaussian을 latent distribution으로 맵핑하는 Network M을 학습시키는 방법이 존재합니다.
이는 style encoder가 학습 및 finetuning까지 다 진행이 된 후 수행하는 후처리 과정으로 보시면 되는데, 저자는 이러한 mapper network M를 학습하기 위해서 nearest-neighbor based Implicit Maximum Likelihood Estimation (IMLE)을 사용하는 방법을 제안합니다. 해당 방식의 목적함수는 다음과 같습니다.
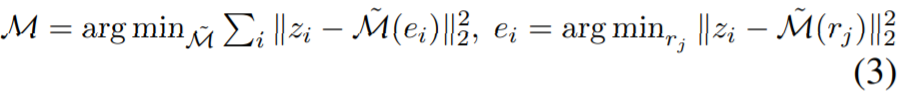
r_{j}는 unit Gaussian prior로부터 랜덤하게 샘플링된 집합을 의미하며, 각각의 latent code [latex] z_{i}에 대해 nearest neighbor M(e_{i})를 z_{i}로 생성하기 위한 e_{i} 고릅니다.
Experimental evaluation
Baseline : Baseline으로 사용된 방법들은 Supervised 기법인 BicycleGAN과 Unsupervised 기법인 MUNIT 입니다.
Image reconstruction
표1은 reconstruction 성능에 대해서 PSNR과 AlexNet 기반의 LPIPS를 나타낸 것입니다.
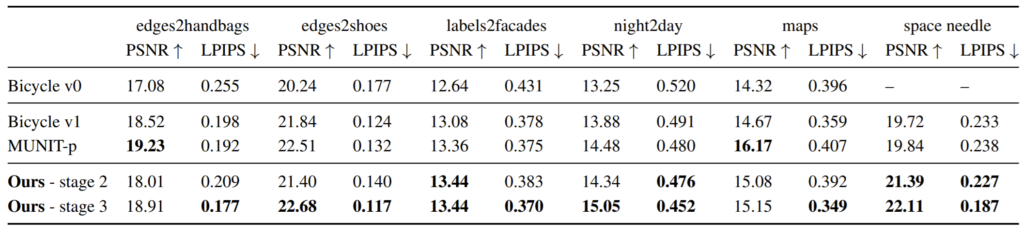
외곽선을 통해 핸드백, 신발 등을 생성하거나, 밤을 낮으로, 지도를 실제 위성 사진으로 바꾸는 등 다양한 reconstruction task를 진행하였으며 여기서 stage2는 위에서 설명드린 encoder와 generator를 finetune을 하지 않은 단계를 말합니다.
저자가 강조하는 부분은 바로 이 stage 2 부분이며, stage 2의 성능이 베이스라인보다 더 좋거나 거의 동등한 경우들이 많다며 이는 자신들의 style based encoder pre-training이 성공적으로 학습되어 출력 도메인의 서로 다른 모드들을 구분할 수 있다고 말합니다.

또한 그림2는 정성적 결과를 나타내는데, 제안하는 방법론을 보면 실제 GT와 색을 최대한 유사하게 따라하고 있으며, 특히 첫번째와 세번째 컬럼에서는 실제 GT의 텍스쳐를 잘 모방하는 것을 확인할 수 있습니다.
Style transfer and sampling

그림3은 style transfer에 대한 정량적 결과로 날씨 조건을 상당히 잘 묘사했다고 합니다. 막 하늘이 깨끗하게 잘 표현하거나 구름이 있을 경우에는 새로운 패턴의 구름도 잘 만들어 낸다 하네요.
그 외에도 다양한 결과에 대해 리포팅을 하는데, 사이트에 올릴 수 있는 용량이 초과해서 추후에 사진을 정리하여 내용을 추가해보도록 하겠습니다.
사전 학습하는데 쓰이는 데이터셋이 굉장히 중요해보여서 많은 테스크에는 적용 못할 것 같다 생각했는데, 날씨에서 일단 놀랐네여. 더욱 다양한 결과가 있다니.. 신기하네여
요새 댓글로 감상평을 자주 쓰시네요ㅋㅋ