
읽을 논문을 찾아보던 와중 독특한 이름의 논문이 눈에 들어와 읽고 리뷰하게 되었습니다. 이름은 “Are Convolutional Neural Networks or Transformers more like human vision?” 으로 현재 이슈가 되는 Transformer 구조와 주류이던 CNN 구조 중 어떤 것이 실제 인간의 시각과 더 유사한가에 대한 주제를 다룬 논문입니다. 사실 처음 읽을 때는 단순 호기심으로 쉽게 읽힐 것이라 생각하고 읽었지만 꽤나 난이도 있는 논문이라 이해하는데 꽤나 시간이 걸렸습니다. 혹시나 해당 리뷰를 읽고 이해가 되지 않으신 부분은 아마 제 설명이 부족한 이유일테니 논문을 참고해서 봐주시면 좋을 듯 합니다.
1. Convolution vs Attention
CNN과 Transformer, 둘 중 어떤 것이 인간의 시각과 유사한 지에 대해 논하기 이전에 각 구조의 특성에 대해 설명하지 않고 넘어갈 수는 없습니다. 간단히 설명을 하자면, CNN의 경우 이미지 내의 패치들을 같은 weight로 처리하는 Convolution 연산으로 구성되어 있습니다. 이러한 방식은 실제 뇌에서 시각정보를 처리하는 방식과 유사하며, 이러한 weight를 학습시켜 여러 class 이미지 별 표현력을 기릅니다. CNN에서와 같이 weight 만큼의 크기를 한번에 처리함으로써 특정 연산으로 제약을 두는 것을 inductive bias가 높다라고 표현하며 이는 이제까지 CNN이 Vision task에서 높은 성능을 보일 수 있는 원동력이었습니다. 그러나 이 방식은 한번에 지역적인 부분만을 확인하기 때문에 전역적인 문맥을 확인하기 어렵다는 단점이 있었고 실제로 한 논문에서는 이미지 분류 시 물체의 shape 보다는 texture에 중점을 둔다는 것을 밝히기도 하였습니다. 이러한 단점을 개선하기 위해 CNN 기반의 방법론들은 augment된 이미지로 학습을 하던가 top-down 방식의 spatial pyramid 구조를 설계하던가 하는 방법을 도입해 왔습니다.
그러던 와중 이러한 단점을 개선하기 위한 시도로 등장한 구조가 Transformer 구조 입니다. Transformer 구조는 이미지 내의 패치 연산을 사용한다는 점에서 CNN과 유사해 보이나 CNN과는 달리 연산하는데 있어 범위가 넓어 전역적인 문맥을 확인할 수 있다는 장점이 있습니다. 실제로 자연어처리 분야에서도 다양한 거리의 정보를 처리하기 용이한 Transformer 구조를 활용해 여러 좋은 성능을 보였으며 이러한 Inductive bias가 낮은 구조는 최근 Vision 분야에서도 높은 성능을 보이고 있습니다.
2. Measuring Error Consistency
AI나 뇌인지과학과 같은 분야에서는 AI 모델과 인간이 특정 문제를 풀 때 같은 전략을 사용하는지 분석하는 것이 주된 문제 입니다. 이러한 분석을 위해서는 주로 Accuracy를 사용하곤 합니다. 그러나 동일한 Accuracy라고해서 동일한 전략을 사용하고 있다는 것을 의미하지는 않습니다. 예를들어 전체 class에 대한 Accuracy는 동일해도 각 class 별 Accuracy는 다를 수 있으며, Accuracy를 측정하기 위해 옳다고 판단하는 기준은 하나지만 옳지 않은 경우의 수는 여러 종류가 존재할 수 있습니다. 축구하는 모습을 축구하는 모습이라 예측하면 옳다고 판단되어지나 야구하는 모습, 배구하는 모습, 농구하는 모습 모두 축구하는 모습을 예측해야하는 경우의 잘못 예측한 예시가 되는 것처럼 말입니다. 이러한 경우들에도 분석을 하고자 본 논문에서는 여러 평가 지표를 도입하였습니다.
- Error overlap
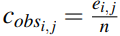
첫번째로 도입되는 평가 지표는 Error overlap이라는 지표입니다. 이는 두 시스템(ex: AI모델, 인간) 들이 서로 어떤 부분에서 틀리는 경향성을 보이는지 알게해주는 지표이며, 두 시스템 상에서 동일하게 맞다고 응답하거나 동일하게 틀리다고 응답한 것을 측정하여 얻게 됩니다. 이는 Observed error overlap으로도 부르며, 식 (1)과 같이 나타납니다. 식 (1)에서 e_{i,j}는 얼마나 두 시스템이 동일하게 응답했는지에 대한 값이며, n의 경우 논문에서 나와있지는 않았지만 총 응답할 수 있는 수로 추측 됩니다. 해당 지표는 두 시스템의 Accuracy가 높아지면 옳다고 결정하는 부분이 넓어져 같이 높아지는 상관관계에 놓여있습니다.
- Correcting for accuracy using Cohen’s κ
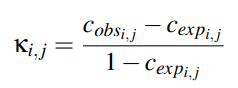
Cohen의 Kappa 상관계수로도 불리우는 해당 지표는 두 시스템의 신뢰도를 판별하기위한 지표로 이전에 인간과 neural network의 성능을 비교하기 위해 쓰였습니다. 식 (2)와 같이 나타낼 수 있으며 조금 복잡할 수 있으므로 해당 식의 요소에 대해서는 간단한 예제로 설명을 드리겠습니다.
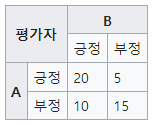
Fig 2와 같이 평가자 A와 B가 존재하고 각 평가자는 두 가지의 선택만을 할 수 있다고 가정해봅니다. 이때 식 (1)에서 분모의 첫 요소인 Observed error overlap 항은 두 평가자가 동일하게 응답한 비율을 의미하기 때문에 {(A와 B 모두 긍정일 때) + (A와 B 모두 부정일 때)} / (전체 값)으로 표현될 수 있으며 Fig 2의 경우 (20+15) / (20 + 5 + 10 + 15) = 0.7로 나타나게 됩니다.
두 번째로 C_{exp_{i,j}} 항은 Error overlap expected by chance 라고 불리우며, 우연히 두 평가자의 예측이 맞을 경우의 값을 의미합니다. 조금 난해한데 이를 구하는 수식을 통해 이해해보자면 우선 C_{exp_{i,j}}=C_{yes}+C_{no}로 구성되어 있으며 C_{yes}는 상대 평가자의 판단에 긍정할 확률값입니다. 이는 (A 평가자가 B의 판단을 긍정할 확률) X (B 평가자가 A의 판단을 긍정할 확률) 로 계산되며 Fig 2 기준으로는 {(20+5)/(20+5+10+15)} X {(20+10)/(20+5+10+15)} = 0.5 X 0.6 = 0.3이 C_{yes}가 됩니다. 반대로 C_{no} 는 상대 평가자의 판단에 부정할 확률 값으로 (A 평가자가 B의 판단을 부정할 확률) X (B 평가자가 A의 판단을 긍정할 확률)로 계산됩니다. Fig 2 기준으로는 {(10+15)/(20+5+10+15)} X {(5+15)/(20+5+10+15)} = 0.5 X 0.4 = 0.2 가 됩니다. 이를 기반으로 Fig 2의 경우 C_{exp_{i,j}} 는 0.5가 되고 Cohen의 Kappa 계수는 0.4가 나오게 됩니다.
해당 평가지표는 두 시스템의 신뢰도를 평가할 수는 있으나 이는 단지 두 시스템이 잘 맞추고 있는지 아닌지 여부에 관한 것일뿐 시스템이 언제 에러를 발생시키는지는 고려하지 않는 단점이 있습니다.
난이도가 높아 1편 2편 나눠서 작성하겠습니다…
해당 논문을 읽어볼까 했던 적이 있어서 다음 내용도 잊지 말고 작성해주시면 좋겠습니다ㅎㅎ.