안녕하세요. 이번 리뷰는 2021 CVPR 논문으로 6 DoF pose estimation에 대한 내용입니다. 개인적으로 최근에 읽은 논문중에 가장 잘 쓰여진 논문이라고 생각이 들 정도로 굉장히 짜임새있고 contribution또한 확실하며 실험또한 광범위합니다. 내용이 상당히 많고 수식적인 내용이 많이 나와서 이해하기 쉽지않는 부분도 꽤나 많았는데 그래도 굉장히 자세하게 쓰여진 논문 덕분에 어느정도 따라갈 수 있었습니다.
우선 해당 연구는 시드니에 있는 University of Technology Sydney 대학의 한 박사과정 학생의 한 연구 입니다. 논문 퀄리티로 보면 아마 지도교수님이 많이 도와주지 않았을까 싶긴합니다. 어찌됐든 세계에는 인재가 참 많다는 것을 느꼈습니다.
해당 논문에선 Abstract, Introduction, Related work 에서 그림을 아예 배치하지 않고 글로만 설명을 한 후 Proposed method 섹션에서야 비로소 그림이 나오는데요. 이와 같은 구조가 조금 특이했습니다. 아무래도 글이 많다보니 읽는덴 힘들지만, 자세하게 설명되어 있어서 해당 논문말고 백그라운드 까지 이해하는데 도움이 많이 되는거 같습니다. 그림은 직관적이지만 글은 자세하기 때문에 나쁘지 않은 전략인거 같습니다.
우선, 해당 work의 모티브가 무엇인지 부터 알아봅시다. 일반적인 2D annotation과는 다르게 3D annotation은 상당히 힘든 작업입니다. 이는 현존하는 3D task들의 bottleneck으로 작용하고 있습니다. 따라서, 해당 논문에서는 3D annotation없이 6DoF pose를 구해보자라는 아이디어에서 시작합니다. 현재 논문에 서술된 말을 이용하자면, train하고 test모두에서 RGB이미지와 2D bbox정보만을 사용하여 6DoF pose estimation을 한 것은 최초라고 주장합니다. 또한 성능도 매우 괜찮게 나왔습니다. 어느정도 수준이냐면, end-to-end임에도 불구하고 기존 two or more stages 기반의 방법론들 혹은 depth정보까지 쓰는 방법론들 과도 비슷한 수준의 성능을 보였습니다. 물론 Real pose label을 사용하는 방법론들에는 아직 못 미치는 수준이지만 그래도 꽤나 괜찮은 성과라고 보여졌습니다.
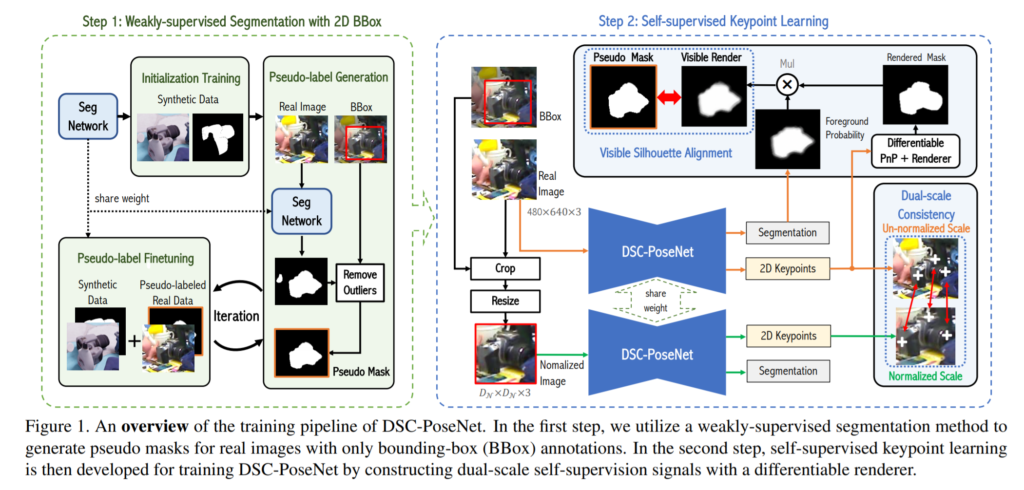
위의 아키텍쳐 그림이 논문에서 처음으로 나오는 그림입니다. 조금 복잡해 보이는데 하나하나씩 살펴보겠습니다. 일단 내용이 많으므로 하나씩 떼어서 설명 해보겠습니다.
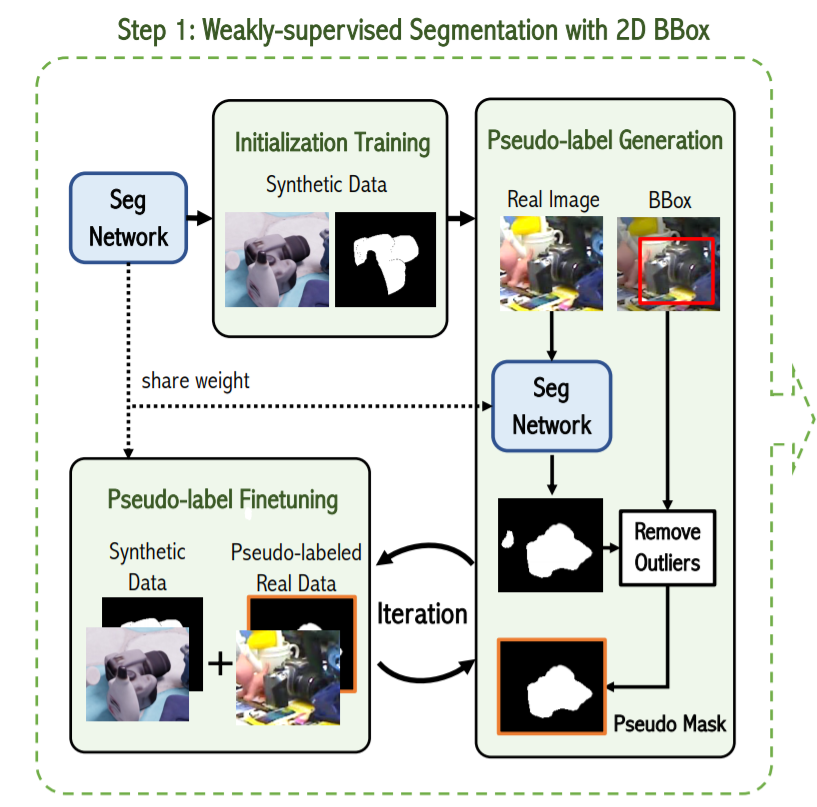
위의 그림은 설명을 쉽게 하기위해 Figure 1의 일부분을 떼어온 그림입니다. Weakly-supervised Segmentation with 2D bbox 라는 제목이 붙어있는데 이름과 같이 Real image에서의 2D bounding box정보와 synthetic data에서의 annotation 정보만을 이용하여 real image의 pseudo mask를 구합니다.
좀 더 자세히 말하자면, 먼저 segmentation network를 synthetic data에서 initialize를 한 후, real image를 weight를 share한 동일한 네트워크에 태웁니다. 그렇다면 real image에서의 mask정보가 나올텐데 이중에는 노이즈에의해 background에 속하지만 foreground로 분류된 pixel들도 존재하게 됩니다. 따라서 해당 부분을 outlier라 간주하고, 2D bbox정보를 기준으로 제거합니다. 즉, 2D bbox의 바깥영역에 있는 pseudo mask를 제거하여 좀 더 정확한 mask를 얻습니다.
또한, 이와 별개로 low confidence를 가지는 uncertain pixel을 정의하고 학습할 때 배제하는데 그에 대한 정의는 아래와 같습니다.

노테이션에 대한 설명을 대체하고자 원문을 끌고왔습니다. 수식의 의미는 uncertain pixel이 가지는 confidence의 범위입니다. 위의 정의대로라면 시그마를 0.7로 설정하였기 때문에 0.3~0.7이 됩니다.

위에서 말씀 드렸던 것 처럼 위에수식이 가지는 의미는 loss항을 정의할 때 m이 uncertain pixel 집합의 원소가 아닌경우에만 계산에 포함시킵니다. 그 이유는 low-confidence를 가지는 pixel들이 error를 유발하여 결과가 부정확해지기 쉽기 때문이라고 합니다.
그리고 이러한 pseudo label generation과 fine-tuning을 반복적으로 수행함으로써 pseudo-label 을 최종적으로 얻게됩니다.
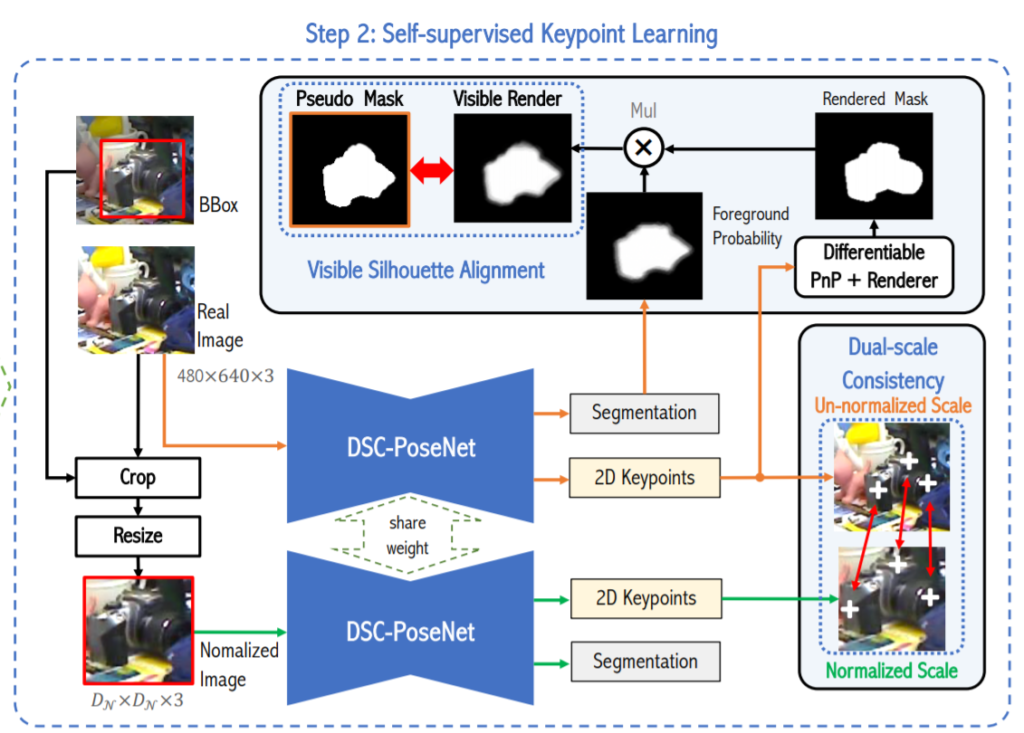
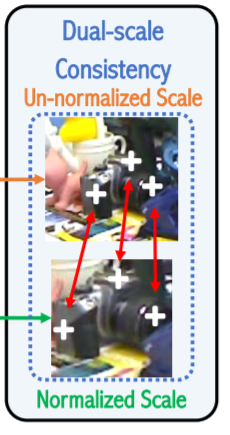
다음으로는 Figure 1의 오른쪽 파트에 대해서 이야기 해보겠습니다. 우선 제목을 보면 self-supervised keypoint learning이라고 되어있는데 이를 위해 총 2가지의 constraints를 사용하는데 그게 바로 dual-scale consistency와 visible silhouette alignment입니다.
좀 더 자세히 설명하자면, 그림에서 보이는거처럼 480*640의 해상도를 가지는 RGB이미지와 그에 상응하는 2d bbox가 인풋으로 사용됩니다. 그리고 해당 이미지는 bbox정보를 이용하여 그림에서 보시는 것과 같이 instance만을 crop과 resize 후 normalize합니다.
위에서 pre-processing한 이미지와 real image 원본은 모두 weight를 share한 DSC-Posenet에 들어가게되며 이 후 아웃풋들은 dual-scale consistency와 visible silhouette alignment을 위해 사용됩니다.
먼저 Dual-scale consistency에 대해서 살펴보겠습니다. 각각의 normalized, crop, resize된 이미지와 real image에서 2D keypoint를 추출하고 이를 비교함으로 써 학습을 합니다. 즉, 별도의 추가적인 label없이 두개의 서로 다른 종류의 이미지로부터 얻은 2D keypoint가 같을 것이다라는 constrain를 이용하여 학습을 진행합니다. 이와 같은 과정을 거치면 scale 변화와, 이미지 픽셀 전체적인 밝기변화 에 대해 강인해지게 됩니다. 얼핏 보면 SIFT descriptor의 원리와 비슷한거 같습니다. 해당 논문에서는 이를 keypoint의 consistency를 위해 이렇게 설계하였다고 합니다. 즉, 이미지가 조금 변화가 있어도 keypoint는 동일한 지점으로 찾아야 한다는 소리 입니다.
다음으로 Visible silhouette alignment에 대해서 이야기 해보겠습니다. 저한테는 다소 생소한 개념이었는데 해당 논문에서는 실루엣을 비교하는 constraint를 설정하여 학습을 합니다. 위의 그림을 보시면 직관적으로 이해가 가능한데 그래도 설명을 덧붙혀 보겠습니다. 먼저 그림에서 특이한점이라면 end-to-end를 위한 미분가능한 PnP를 사용하였단 점 입니다. 아까 구한 pseudo label+pnp+renderer를 통해 rendering한 mask와 segmentation을 통해 나온 foreground probability을 곱하여 나온 최종적인 실루엣을 pseudo label의 실루엣과 비교합니다. (위의 그림 참고하시면 이해가 쉽습니다.) 개인적으로 많이 생소한 방법인거 같은데 밑에서 좀 더 자세히 다루겠습니다.
우선 논문의 핵심적인 컨셉에 대한 설명이 끝났습니다. 내용이 상당히 많았는데 제 글을 여러번 읽어보시거나/ 한번읽어보시고 논문을 가볍게 읽어보시면 이해하는데 어려움이 없으리라 생각합니다. 어찌됐든 컨셉은 그러한데, 이제 디테일한 부분에 대해서도 다루어 보겠습니다.
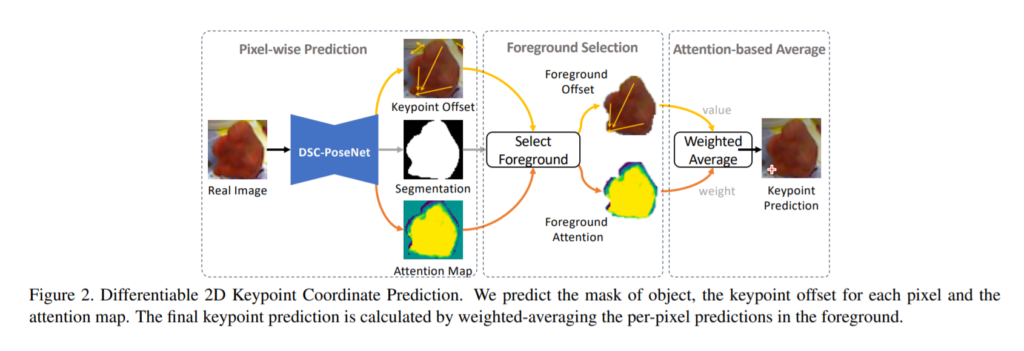
먼저 아까위에서 2D keypoint 를 어떤식으로 활용했는지에 대해서만 설명을 했는데 2D keypoint를 과연 어떻게 추출하였는지에 대한 설명부터 시작하겠습니다.
먼저 기존 방법론들을 예로들자면, DSNT는 spatial heatmap의 weight를 이용하여 좌표의 평균을 취했고, 이는 미분가능하나 occlusion이 발생하면 성능감소가 심하였습니다. PVNet은 vector장을 만들고 occlusion과 truncation에 강인하게 모델을 설계하는데 성공하였지만, voting방식은 미분불가능하므로 end-to-end가 아닌 단점이 있었습니다.
이러한 배경에서 해당 논문에서는 위의 그림과 같이 keypoint offset, segmentation, attention map을 구한 후 이 정보들을 이용하여 foreground offset과 foreground attention map을 구합니다. 그리고 최종적으로 weighted average를 취하여 keypoint를 prediction합니다. 이를 수식으로 나타내면 아래와 같습니다.

마찬가지로 notation을 참고하시라고 원문을 끌어왔습니다. 수식이 의미하는바는 keypoint predcition값(k_nm틸다)이 어떠한 픽셀좌표값과 keypoint offset의 합으로 나타낼 수 있고, 그리고 그를 weighted averaged한 값이 최종 keypoint값 이라는 소리입니다.
좀 더 간단하게 말하자면, 오른쪽 수식은 keypoint prediction = pixel좌표 + keypoint offset 이 되고
왼쪽은 foreground 집합인 O의 원소인 좌표들에 대해서 오른쪽 연산을 통해 구한 각각 keypoint prediction들의 weighted average입니다.
이런식으로 처리를 하게되면, 마치 voting과도 비슷한 효과가 나와서 직접적으로 vector field를 만들어서 voting을 하는 PVNet 처럼 occlusion이 발생해도 keypoint를 예측할 수 있게됩니다. 그리고 직접적인 voting방식을 사용하지 않음으로써 end-to-end 로 설계하여 기존에 존재하던 bottleneck을 제거할 수 있게됩니다.

다음으로 소개할 내용은 어떻게 학습을 했느냐 하는 부분입니다. 일단 loss는 smooth l1 loss를 사용하였고 이는 익숙학 개념일거라 생각하기 때문에 자세한 설명은 넘어가겠습니다.
synthetic data를 사용하면 GT pose에 대한 정보가 manual한 annotation없이도 사용가능하기 때문에 synthetic dataset에서 학습을 하였으며, 좀 특이한 점으로는 시그마하고 S를 사용합니다. 이 때, 시그마는 scale factor이고, S는 바운딩박스에서 width 와 height중 더 큰 길이를 의미합니다. 특히나 이 S로 normalize하는 것은 scale에 따라 variance가 달라지는 것을 최소화시켜 loss가 수렴하는데 많은 도움을 주었다고 합니다.
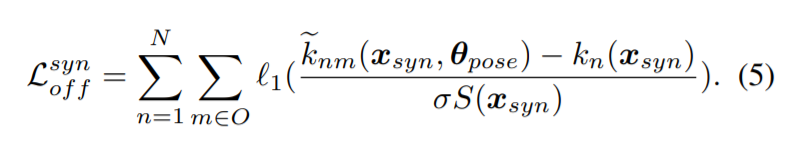
offset에 대한 loss 는 위에서 설명한 것과 매우 흡사하기 때문에 설명은 생략하겠습니다. 위의 수식만 참고해주세요.
그렇다면 이제 위에서 소개했던 dual-scale-consistency에 대해서 설명 하겠습니다. 이에대한 전체적인 컨셉은 위에서 자세히 설명하였으므로 기억이 안나시면 다시 읽고오시길 추천드립니다. 해당 부분에서는 전체적인 개념보단 수식적인 부분위주로 다루겠습니다.


6번과 7번 수식을 해석하면 augmentation과 normalize에 관계없이 keypoint는 consistent하게 추출되어야 한다는 의미를 가지고 있습니다. 예를들어 이미지가 있을때, normalize한다음 keypoint를 구하고 de-normalize하면 해당 값은 결국엔 그냥 이미지를 통해 구한 keypoint 와 같은것이다 라는 논리입니다.
비슷하게, augmentation 여부에 관계없이 keypoint는 consistent하게 추출된다 라는 내용이 eq. (7) 입니다. 사실 그리 어려운 내용은 없고 수식적으로 나타내면서 notation이 많이 추가되어서 복잡하게 생겼을 뿐입니다.


또한, 위와 같이 eq 8 , 9 , 10, 11이 정의되는데 해당 수식을 하나씩 뜯어봅시다. 우선 notation을 일일히 설명하기 힘들어서 원문을 끌어왔습니다.
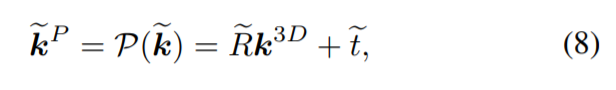
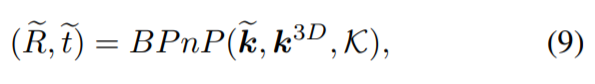
먼저 수식 8번과 9번 입니다. 수식을 이해해보자면, 먼저 우리는 2D keypoints를 알고 있습니다. 이와 더불어 intrinsic parameter와 해당 CAD 모델의 3D keypoint의 상대적인 위치도 알고 있습니다. 이와 BPnP를 이용하여 물체의 pose를 얻을 수 있습니다. 이 과정에대한 수식이 바로 (9) 입니다.
그리고 해당 pose(R, t) 와 3D keypoints를 이용하여 다시 2D상으로 투영하면 2D keypoint를 다시 얻을 수 있습니다.
이제 이렇게 6, 7, 8 번 수식을 합치면 loss 항을 얻을 수 있는데 그는 아래와 같이 정의됩니다.

좀 많이 복잡해보이긴 한데 하나하나 차근차근 풀어가면 이해할 수 있습니다. 먼저, 시그마와 S에 대해서는 위에서 한 설명을 참고하시고 여기서는 해당 설명은 생략하겠습니다. k_n에 위에작대기 표시를 먼저 살펴보면, 해당 수식이 의미하는바는 결국엔 keypoint입니다.
아래와 같은 2가지 keypoint를 더한 후 2로 나누어준 값입니다.
1. real image로 부터 얻은 keypoint
2. real 이미지를 normalize하고 keypoint를 얻은 후 다시 de-normalize한 값
이는 해당 1번과 2번의 2D keypoint는 consistent해야한다는 constraint를 만족시키기 위해 추가한 항입니다.
계속 수식을 살펴보면, 결국엔 비슷한 원리로 normalize하고 augmentation의 여부에 따라도 keypoint는 항상 consistent하다는 constraint를 주기위한 loss입니다. 결국엔 L1 loss인데 다양한 constraint를 고려하고 수식으로 표현하니 좀 복잡하게 보이는 것일 뿐입니다.
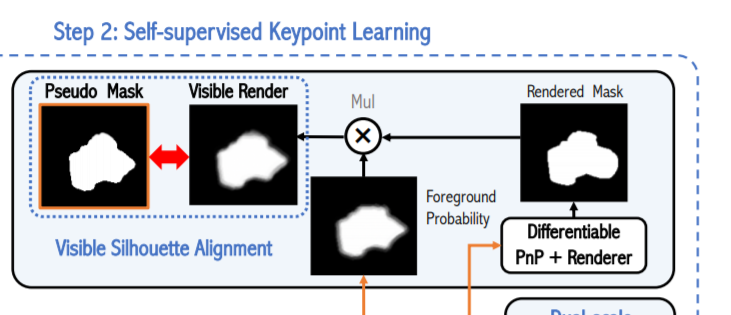
이번에는 실루엣 alignment에 대해서 이야기 해보겠습니다. 마찬가지로 전체적인 컨셉은 위에서 다루었고 여기서는 디테일한 부분에 대해서 다루겠습니다.
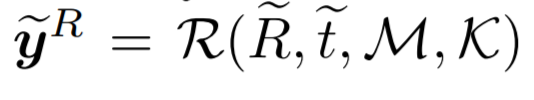
Pytorch3D 에서 위와 같은 정보들을 이용하여 rendered masks를 생성합니다. 각각 notation이 의미하는바는 위에서 계속 사용해온 것과 같습니다.
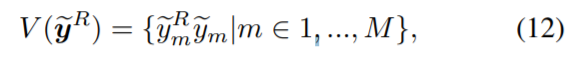
그럼 visible mask는 위와같이 단순한 matmul을 이용하여 정의할 수 있습니다. 무슨소리냐면, 일반적으로 segmentation을 하면 occlusion이 있는 부분에선 결과가 좋지 못합니다. 그래서 해당 논문에서 사용하는 방법은 DSC-Posenet 으로부터 segmentation branch를 따와서 사용합니다.
위에서 한번 설명드렸듯이 DSC-Posenet에서는 voting방식대신 attention방법을 이용하여 비슷한 효과를 내었고 이러한 방법론으로 occlusion에도 강인함을 보였습니다. 즉, DSC-Posenet 으로부터 segmentation branch를 따와서 사용함으로써 자연스럽게 occlusion에 강인하게 foreground probability map을 생성할 수 있습니다.
그리고 그렇게 나온 foreground probability map과 rendered mask를 단순 matmul연산을 이용하여 곱해준게 바로 수식 12번 입니다. 그리고 이렇게 나온 결과를 visible mask라고 칭하는데 이는 occlusion이 있어도 어느정도 visible해지고 이는 occlusion에 대한 강인성을 부여하는데 도움을 줍니다.

그렇게해서 나온 visible rendered mask와 pseudo segmentation mask를 비교하며 alignment하는 과정을 진행하는데 그게 바로 위의 수식입니다. 해당과정에서는 Dice loss를 사용합니다.

음… 레퍼런스 논문을 타고 들어가보니 또다른 레퍼런스 논문이 있네요? 그래서 그 논문도 타고들어가보니 dice coefficient부터 시작해서 논문 전체를 읽어야 할거같아서 일단 이번 리뷰에서는 dice loss는 segmentation task에서 GT값이 있을 때 사용한다 정도로 이해하고 넘어가겠습니다.
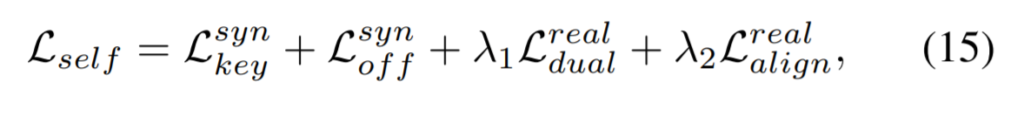
그렇게 해서 구한 loss항들이 전부다 더해져서 최종 loss항이 만들어집니다. 앞에서 weakly-supervised segmentation 블록에서도 사용한 loss텀을 고려하면 loss 텀만 총 5개나 사용하였네요.
평가
해당 논문에서는 학습 및 평가용으로 데이터셋을 LINEMOD, OCCLUDED LINEMOD, HomebrewedDB로 3가지를 사용합니다. YCB video dataset에 대한 평가가 없는게 아쉽지만 그래도 꽤나 다양하고 다 공신력있는 데이터셋들만 사용하였으니 일단 결과에 대해서는 의심의 여지는 없습니다.
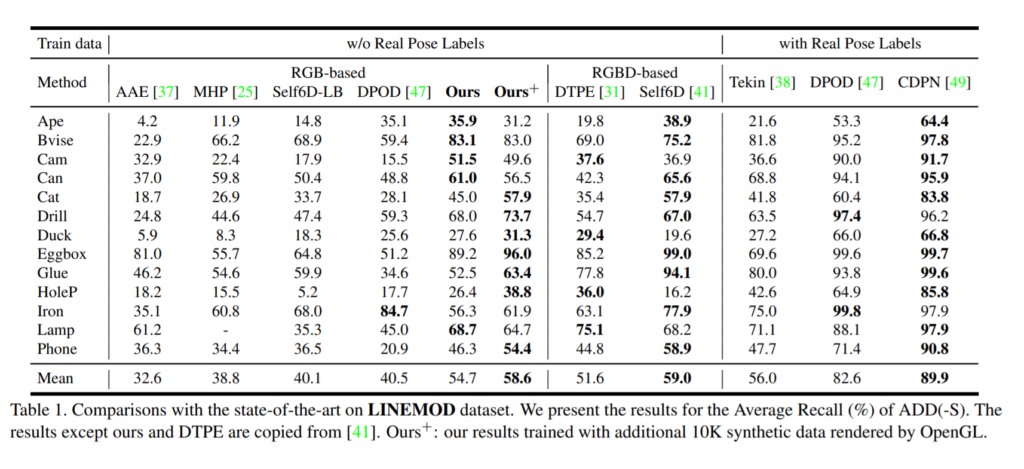
그렇게 나온 결과중에 가장 많이 사용하는 LINEMOD 데이터셋에서의 결과는 위와 같습니다. 기존 RGB기반 방법론들을 훨씬 웃도는 결과를 보이네요. 심지어는 RGBD기반 방법론인 DTPE를 이겼고, synthetic dataset에서의 추가학습 이후에는 self6D와도 견줄만한 결과가 나왔습니다. 아직 Real Pose Label을 기반으로 한 방법론들에는 못 미치지만 그래도 꽤나 좋은 성능을 보여줬다고 생각합니다.
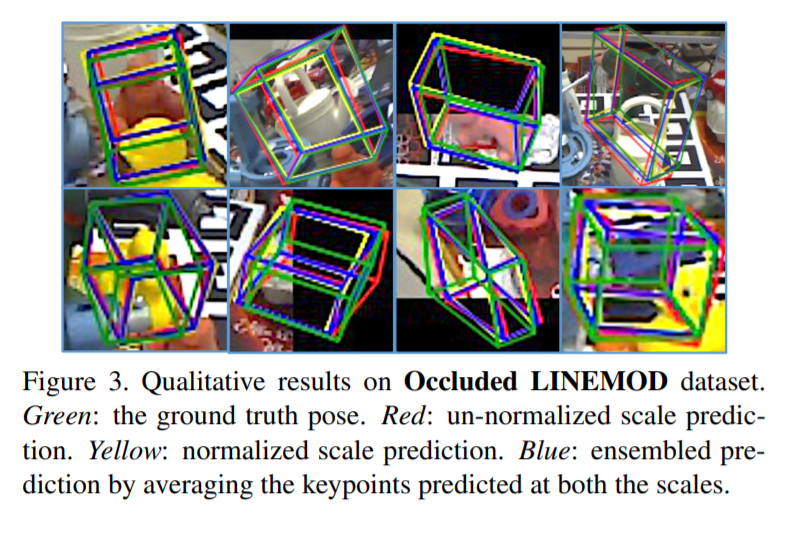
정성적 결과이구요.
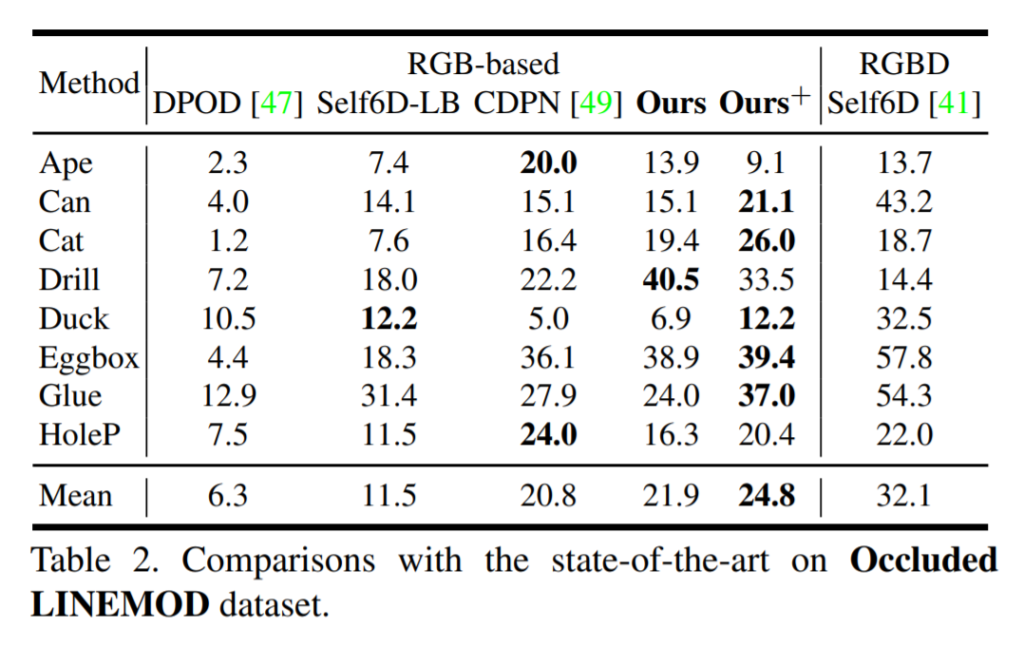
Occluded LINEMOD에서의 결과입니다. 역시나 RGB-D 방법론을 제외하곤 가장 좋은 성능을 보이네요.
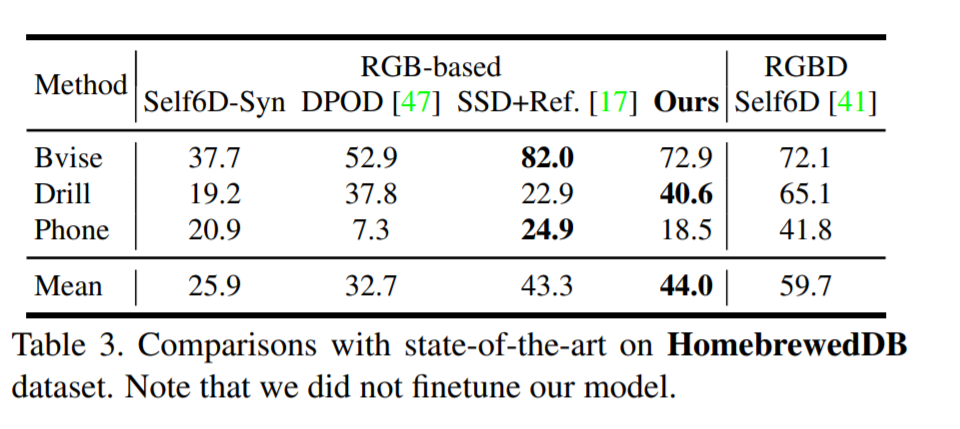
HomebrewedDB 에서도 좋은 성능을 보입니다. LINEMOD에 비해서는 약간 margin이 더 작긴 하네요.
전체적으로 모든 모델에 대한 비교라고 보기는 힘든거 같긴하지만, 그래도 성능이 꽤나 잘나온거 같다고 느껴지는 실험이네요.
리뷰를 마치기전에… 사실 제가 지금 쓴 리뷰에 모든 내용을 다 담을 순 없다고 생각합니다. 평소같으면 그냥 리뷰로 마치겠지만, 이번 논문에 소개드리는 논문은 퀄리티가 꽤나 좋으니 직접 읽으시는것도 추천드립니다.
1. Weakly-supervised Segmentation with 2D bbox에서 결국 synthetic data만을 이용해 real 데이터의 mask를 얻겠다고 하는데, real data와 synthetic 데이터의 gap은 존재하지 않나요?
2. pseudo -labeled real data는 segmentation mask를 의미하는건가요??? 해당 라벨에 pseudo labeled 가 붙는이유와 앞서 설명해주신 3D 라벨을 얻기 힘들다의 연관성을 모르겠습니다. (segmentation은 2D annotation에 속하지 않나요?)
2. “Pytorch3D 에서 위와 같은 정보들을 이용하여 rendered masks를 생성한다”라고 이야기하셨는데 정확히 rendered masks는 무엇이며, pytorch 3D를 이용해 어떻게 생성하는지 설명해주실 수 있나요?
P.S
“좀 더 자세히 말하자면, 먼저 segmentation network를 synthetic data에서 initialize를 한 후, real image를 weight를 share한 동일한 네트워크에 태웁니다. 면 real image에서의 mask정보가 나올텐데 이중에는 노이즈에의해 background에 속하지만 foreground로 분류된 pixel들도 존재하게 됩니다.” 에서 오타가있습니다.
1. gap차이가 분명 존재합니다. 그래서 iteration을 돌면서 pseudo mask (segmentation mask)를 구하고 real 2D bbox정보를 이용하여 outlier를 제거한 후, synthetic data에서의 segmentation mask 정보를 이용하여 fine tuning합니다.
2. 먼저 pseudo labeled real data는 2D segmentation 정보를 의미하는게 맞습니다. 해당 라벨에 pseudo가 붙는 이유는 실제로 real 데이터에서는 2D bbox정보만을 사용하고, synthetic data에서 segmentation mask 정보를 사용하여 해당 pseudo mask를 구하기 때문입니다. 3D 라벨을 얻기 힘들다는 이유는 GT Pose를 일일이 anotation하기 힘든데 해당 work에서는 2D bounding 정보와 synthetic 데이터에서의 정보만을 사용했기 때문입니다. synthetic 데이터에서는 semgentation mask정보와 pose 정보를 자유롭게 획득할 수 있습니다.
3. 해당 부분은 논문에서도 그렇게 짧게 명시만 하고있고, 코드가 공개된게 아니라 답변이 힘들거 같습니다. 다만 참고하실만한 링크 첨부합니다. https://pytorch3d.org/docs/assets/transforms_overview.jpg
오타는 수정했습니다.