본 리뷰는 해당 영상을 참고하였습니다.
1. 왜 Self-supervised learning을 연구해야 하는가
AI와 Machine Learning 에는 다음의 3가지 도전과제가 있다.
1. 적은 labeled samples 로 학습하기
2. 추론을 위한 학습하기 (이해가능한 학습)
3. 복잡한 액션 sequences를 학습하기
위의 도전과제에서 1번과 2번을 해결하기 위해 self-supervised learning방식이 연구되어야 한다. 추론을 위한 학습과 적은 labeled로 학습 가능한것은 모두 기계의 학습 과정보다 인간이 학습하는 과정과 유사하다. 즉 self-supervised learning은 인간이나 동물의 학습법과 유사하고, 이를 묘사하는 과정으로 AI와 Machine Learning이 발전해야 한다고 하는 것 같았다. 학습기반의 인공지능의 큰 약점 중 하나인 data-hungry문제를 해결하는 방법으로 가장 쉽게 떠올릴 수 있는 방법이라는 점에서 많은 사람이 동의할 것 같다.
위와 같은 시사점을 지닌 Self-supervised Learning의 영상에서 정의는 다음과 같다.

이러한 Self-Supervised Learning(SSL)은 위에 언급했던 AI와 ML의 2가지 문제점을 다음과 같이 해결할 수 있다
1. 적은 labeled samples 로 학습하기 -> SSL pre-training 과정을 supervised와 RL model학습 전에 사용하기
2. 추론을 위한 학습하기 -> hierarchical 접근이 아닌 세상을 모델링 하는 기법(forward models)에 적용하기 (policy learning, model-based RL)
이렇게 SSL을 통해 2 big challenges를 해결하기 위해서는 SSL이 uncertainty와 multimodality를 어떻게 구성하는지에 대해 잘 정의해야한다. 얀 르쿤 교수는 이를 위해 Energy-Based Models을 제안하였다. 즉 Energy-Based Models (EBM) 연구는 SSL에서 모델의 예측에 대한 uncertainty와 multi-modality를 잘 나타내어 SSL이 원활하게 학습되도록 하는 연구라고 볼 수 있다.
2. Energy-Based Models (EBM)
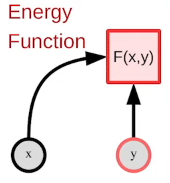
EBM은 위와 같이 모델링 될 수 있는데, x가 특징값, y가 예측해야할 변수 일 때, Energy Function, F()에는 두 데이터를 입력으로 하고, 두 데이터간의 조합을 에너지로 나타내는것이다. 예를들어 x와 y가 옳은 조합이라면 F(x,y) 는 안정된 에너지, 0에 가깝고, 그렇지 않으면 높은 값을 취한다. 이렇게 예측에 대한 uncertainty를 에너지로 나타내고 또한 X와 y가 관계를 통해 학습하니 multi-modality에도 대응 할 수 있을 것이다. 여기서 주의할 점은 정의한 energy란 inference를 위해 사용되는 것이지 learning의 대상이 아니라는 것인데, 만약 energy 가 learning의 대상이 된다면 결국 X,y조합에 대한 사례학습이 되기 때문이다.
Energy-Based Model을 학습하는 방법:
좋은 reference를 생성하기 위해 EBM을 학습해야한다. EBM을 학습하는 방법은 두가지가 있다고 한다. 첫째는 친숙한 Contrastive Methods 이며 둘째는 Regularized/Architectural Methods라고 한다.
첫째는 Contrastive learning이라고 SSL 방법론에서 종종 들어보았을 것이다. contrastive learning이란 유사도 기반 학습으로 유사 군집간의 feature 유사도를 높이는 방향으로 encoder 모델을 학습하는 방식이다. 이는 EBM를 이용하면 더 쉽게 설명이 가능한데, X와의 좋은 매칭 짝 y, 나쁜 매칭 짝 y’ 이 있을 때 F(X, y)는 push down 하는 방향으로 F(X, y’)는 push up 하는 방향으로 학습하는 것이다. 이때 push의 방향이 고차원 공간으로 갈수록 정의하기 어렵다는 점에서 비효율적인 부분이 존재한다. (Contrastive method 기반 학습법: 최대가능도, 메트릭 러닝, 샴 네트워크, GAN ..etc)
둘째로 Regularized/Architectural Methods 방법론이란 low energy의 공간에 제한을 두는것이 기본 방식이라고 한다. K-means가 그 예시라 할 수 있으며 k-means를 학습하는 것이 k-means의 에너지 표면을 묘사하는 것이라고 한다.
(Regularized/Architectural Methods 방법론에 해당하는 학습방식은 Sparse-coding, Sparse auto-encoder 등이 있다고 한다.) 사례를 대표하는 느낌