
i2i(image to image translation)을 이용해 Thermal를 RGB로 변환하는 연구를 하고 있는 요즘 Thermal의 고유한 특성 때문에 연구에 문제가 생겼다. 그 Thermal의 고유한 특성은 바로 시간 대에 따라 달라지는 씬의 온도변화로 인해서 시간대마다 전체 min과 max그리고 histogram의 양상이 달라지는 문게가 발생하는 것이다. 이러한 문제를 해결하기 위해서 다른 연구에서는 CycleGAN을 이용해 각 시간대를 하나의 시간대로 변환하거나, 교수님의 논문 중 MTN에서는 gamma collection( 각 시간대의 gamma 값을 미리 구해 각 시간대 영상을 원하는 시간대로 변경) 방법론을 이용해서 문제를 해결하고자 했다. 하지만, CycleGAN은 모든 시간대를 다루는데 너무 번거롭다는 단점이 있고 gamma collection 같은 경우는 아직 구현을 제가 못..( 쿨럭) 암튼 여러 문제가 있어서 i2i를 이용해 이러한 문제를 해결하고 싶어서 논문을 서칭하고 있던 중에 이번 CVPR에서 원하는 방식으로 문제를 해결한 것이 있어서 가져와 봤다.
이 논문은 위 첫번째 그림 과같이 영상과 linear한 값을 이용해 원하는 시간대로 영상을 변경하는 방법론이다. 즉 continuous한 상황을 unsupervised GAN방식을 이용해 생성해 내는 방법론이다. 그럼 이 논문에 대해서 좀 더 자세히 설명해보도록 하겠다.
- Contribution
먼저 이 논문에서 제시하는 contribution을 간단히 소개하고 방법론에 대해 자세히 다뤄 보도록 하겠다. 이 논문에서 제시하는 벙법론은 크게 보면 다음과 같다.
- continuous i2i를 위한 novel model-guided system을 제시
- FIN( Functional Instance Normalization)을 제시
- CoMoGAN 모델을 제시
- 다양한 테스크에서 다양한 방법론들과 비교실험 진행
2. Method
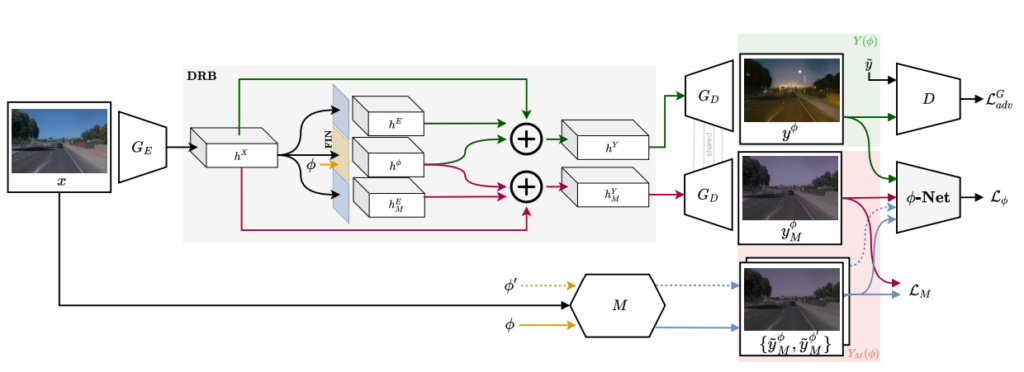
CoMoGAN은 입력 영상과 φ을 이용해서 원하는 시간대로 영상을 생성한다. 그림 2 에서와 같은 모델 구조를 띄고 잇으며 하나하나 살펴보도록 하겠다.
2.1 Functional Instance Normalization (FIN)
이 논문의 contributio 중 하나인 Functional Instance Normalization 이다. 기존 i2i 방법론들은 최근 Instance Normalization (아래식) 을 이용해서 정규화 또한 학습을 통해서 진행해왔고 좋은 성능을 보여주었다.
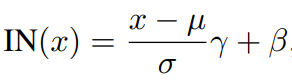
이런 IN에 φ를 접목시켜서 φ에 따른 정규화를 시키는 것이 FIN의 주요 방식이다. 식은 아래와 같다.
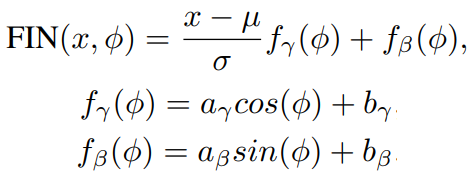
기존 IN에서 r과 B부분을 φ에 관한 식으로 봐꾼 것이 FIN이다. 이를 통해서 φ를 IN 에 Encoding 하여 모델에 영향을 줄 수 있게 되었다.
2.2 Disentanglement Residual Block (DRB)
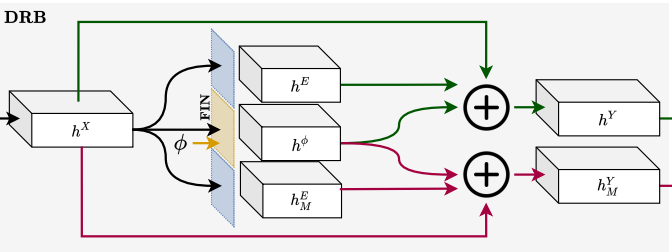
Encoder를 통과 시켜서 나완 feature를 두가지로 분류하는 부분이다. 두가지로 분류하는 이유는 M모델을 이용해서 전체적인 guide를 해주기 위한인데 여기서 이 M 모델은 단순한 식을 이용해 영상을 변환 시켜 Pseudo Label을 만드는 것이라고 생각하면 된다. Gamma collection을 이용해서 시간대에 맞는 영상을 생생해내서 Pseudo label로 사용한다고 생각하면 된다. 이렇게 둘로 나누게 되면 hY는 Un-Supervised로 hYM 은 Pseudo-label과 비교를 통해 학습을 하게 되고. 모델은 실제 데이터와 M을 통해 생성된 데이터의 특성을 모두 배우게 된다.
2.3 Pairwise regression network (φ-Net)
DRB를 이용해서 hφ와 hE의 역할을 Style과 Struct의 느낌으로 나눴지만 모델을 나눈 것 외에도 추가적으로 hφ가 Style의 역할을 할 수 있는 추가적인 방법이 있어야했다. 따라서 이 논문에서는 모델이 hφ를 담고있는 영상을 생성할 수 있는 방법론을 제시했다. 그건 CNN(φ-Net)을 이용하는 방식이다. φ-Net은 두 영상을 입력으로하고 각 영상의 φ를 예측한 차를 계산한다. 식은 다음과 같다.
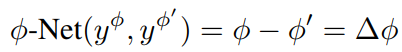
이것을 이용하면 다른 φ가 들어왔을 때와의 차이를 확연히 보여줄 수 있다. 즉 triplet loss와 같은 방식으로 φ의 영향을 가중시키는 것인데 식은 다음과 같다.
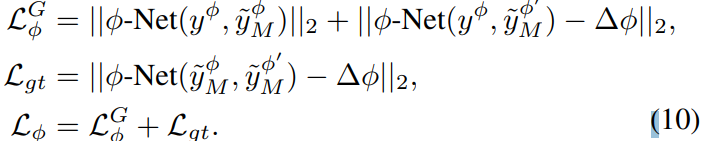
2.4 Training strategy
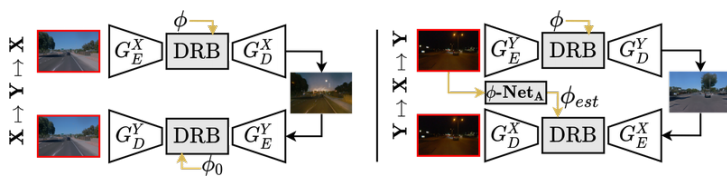
이 논문 또한 Unsupervised 방식을 학습에 적용하였고 그 때 φ를 recontruction하는데 도움을 주기위해 추가적인 φ-Net을 설계했습니다. 이 네트워크로 싸이클릭한 영상에서 생성된 φ가 입력된 φ과 동일하도록합니다.