이번 CVPR2021에 재미있는 논문이 나와서 리뷰를 진행하겠습니다.
페이퍼 : https://arxiv.org/pdf/2103.15297.pdf
코드 : https://github.com/tusimple/LiDAR_RCNN
Introduction
” We propose an R-CNN style second-stage detector for 3D object detection based on PointNet. Our method is plug-and-play to any existing 3D detector, and needs no re-training to the base detectors. “
본 논문에서 핵심적으로 제안하는 Key Contribution 입니다. 해당 방법은 기존에 존재하는 방법에도 ‘plug-and-play’ 할 수 있는 proposals 3D bbox을 refine하는 방법에 대해서 이야기하고 있습니다.
Methods
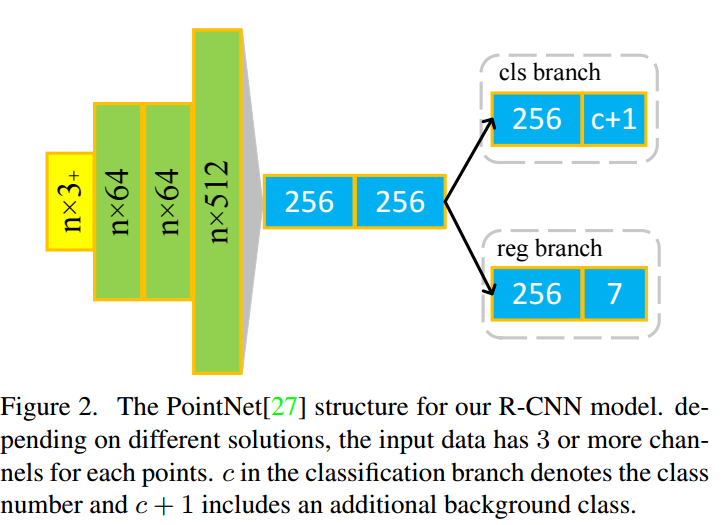
본 논문에서 나타낸 아키텍처(?) 입니다. 사실 심플합니다. 본 논문에서는 새로운 아키텍처를 이야기하는게 아닌, 기존 3D Object Detection 모델들이 가지고 있던 Size Ambiguity problem을 해결하는것이 핵심이기 때문입니다. 해당 네트워크는 가장 나이브하고 속도가 빠른 Point net기반으로 존재하는 3D Object detection에서 추출한 proposal을 가지고 위의 네트워크를 통해 refine 하게 됩니다. (해당 방법은 기존 3D Object detection에 추가적으로 붙는 모듈정도로 생각하시면 되고, 그렇기 때문에 R-CNN에서 RPN을 통해서 ROI가 나오면 이후에 CLS, REG를 수행하는 것과 동일하게 생각하시면 됩니다.) 해당 방법에서 이야기하는 CLS는 말 그대로 Classification을 이야기하며, Regression은 refine box parameters를 의미하며, 총 7개(x,y,z,w,l,h,theta)가 됩니다. 추가적으로 해당 모델의 입력은 proposal bbox인데, generalization을 향상시키기 위해서 모든 proposal bbox는 normalize를 수행했다고 합니다. 이때 origin point는 proposal bbox의 center point입니다.
Size Ambiguity Problem
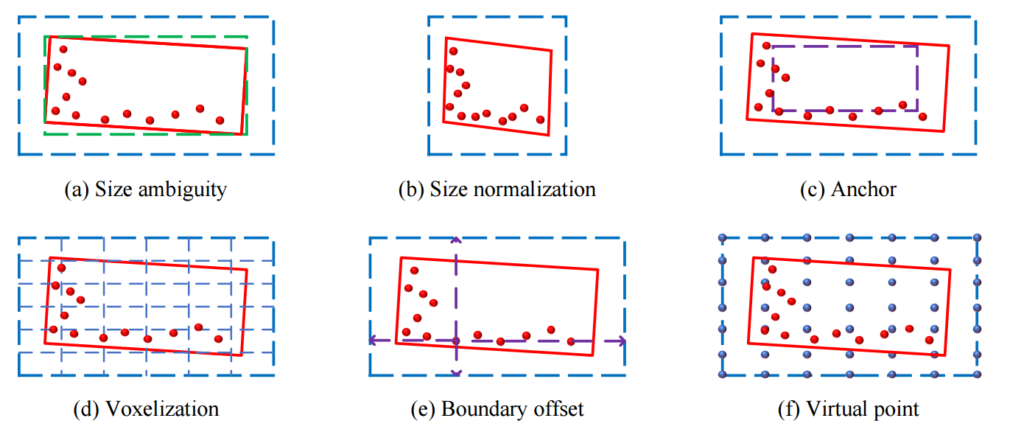
사실 이 논문 이야기하는 기존 3D Object detection 방법들이 가지고 있던 Size Ambiguity 문제는 위에 그림을 통해서 확인할 수 있습니다.
(a) – 실제 동일한 raw point를 포함하는 두 가지 proposal bbox(초록, 파랑)가 있다고 생각합시다. 그리고 실제 GT는 빨간색 bbox입니다. 만약 해당 문제가 2D Object detection 이라면, 여백도 픽셀값이 있고, 그러므로 여백이 많고 적음에 따라서 두 proposal 박스중에서 초록색 proposal bbox의 confidence가 더 높게 나오고, regression도 더 잘 됐을 것 입니다. 하지만 기존 3D object detection 에서는 여백(빈공간)에 대해서 고려하지 않고, 오직 real point에서만 고려하기 때문에(Point net의 원리를 생각하시면 됩니다. 잘 모르시면 리뷰 참고) 저 두 proposal은 동일한 feature를 나타내게 되며, 이는 굉장히 모델이 refine하는데 있어서 방해가되는 즉, 혼란이 되는 요소입니다. 따라서 본 논문에서는 이러한 문제를 해결하기 위한 방법에 대해서 이야기합니다.
(b) – (a)에서 나타난 문제를 해결하기위해서 size를 normalization 할 수 있다고 합니다. 하지만 이러한 방법은 object shape를 파괴하고, multiple categories 문제를 해결해야 한다면, 각 클래스마다의 scale은 무시됩니다. 따라서 다른 클래스들을 구별하기 힘들게 합니다. (즉, 적합하지 않습니다)
(c) – 해당 방법은 몇몇 논문에서도 제안된 방법입니다. 처음부터 default bbox의 개념처럼 anchor를 만들고 해당 anchor 기반으로 변화량을 regression 하는 방법입니다. 이렇게되면 앞서 설명한 ambiguity of the size를 해결할 수 있습니다. 하지만 본 논문에서 anchor 없이도 IOU가 높아지도록 proposal bbox를 refine 하는 방법에 대해서 이야기하고 있습니다. 또 이러한 anchor 기반은 멀티 클래스를 수행할때 다양한 클래스마다 서로다른 anchor를 설정해야한다는 단점도 존재합니다.
(d) – 기존에 존재하는 2 stage 방식에서 voxelization을 통해서 수행하는 방법도 있지만, 이또한 저자는 위에서 소개한 anchor 방식과 유사한 ‘sub-anchor’ 라고 설명합니다. voxel로 나눠서 위에서 설명한 빈공간에 대한 이슈는 해결할 수 있지만 결국 이방법도 voxel 레벨에서의 접근일뿐, point 레벨에서 온전히 접근할 수 없다고 합니다.
따라서 이러한 기존의 문제들을 해결할 수 있는 두가지 방법을 논문에서는 제안하고 있으며, 각각을 Boundary offset(e), Virtual point(f)라고 합니다.
(e) Boundary offset – 이 방법은 각 라이다 포인트와 proposal bbox의 offset을 계산하여서 boundary information를 만들고, 이러한 boundary가 작아지도록 proposal bbox를 refine 하는 방법입니다. 이러한 방법으로 앞서 설명한 ambbiguity problem 을 해결할 수 있다고 합니다.
(f) Virtual point – 이 방법은 존재 여부를 알아챌 수 있는 virtual point를 만드는 방법입니다. proposal bbox에 virtual point를 만드는 방법인데 (좀더 설명하면 그냥 실제 back ground point를 만드는것 입니다.) 이때, real point와는 구별되게 해주는 방법입니다.
본 논문에서는 (e), (f) 처럼 기존에 3D Object Detection에서는 다루지 못한(?) proposal 박스를 좀 더 정확하게 classification하고 regression 할 수 있는 가장 단순한 방법을 추가적으로 제안하였습니다. 그리고 실험파트에서는 이러한 방법들을 통해서 실제 성능 향상이 나타남을 증명합니다.
Experiments
실험에는 Waymo Open Dataset(WOD)와 KITTI Dataset을 사용하여 진행하였습니다.
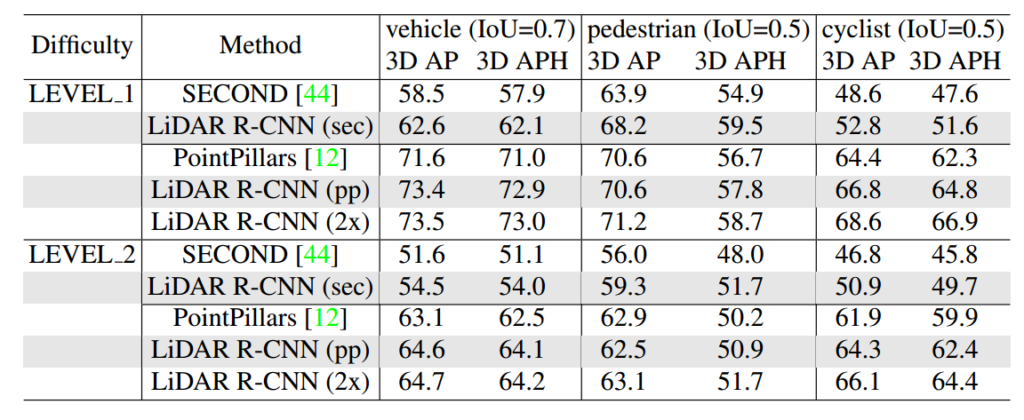
위의 테이블은 Multi-class 3D detection을 다루고 있는 Waymo Open dataset에서의 결과입니다. SECOND, PointPillars는 기존에 3D Object Detection 방법론이고, 밑에 LiDAR R-CNN은 해당 방법론이 만든 Proposal에 논문에서 제안하는 방법을 추가적으로 사용했을때 결과입니다. 이를 통해서 실제 성능향상이 나타남을 보이고 있습니다. 여기서 2x는 기존 네트워크(위에서 단순한 그림)에서 채널 수를 두배로 키운 결과라고 합니다.
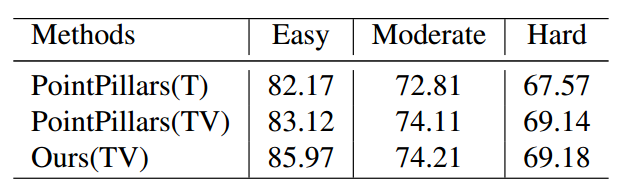
해당 테이블은 KITTI에서 나타낸 결과이며, KITTI에서도 성능 향상을 가져왔습니다. 여기서 TV는 Training set + validation set이라고 합니다.
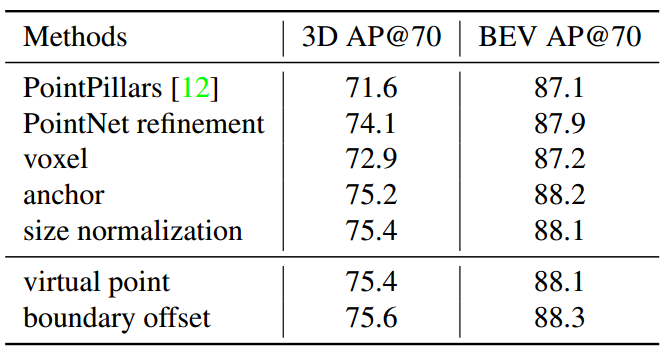
앞서 설명했던 (a)~(f)에 따른 성능차이도 ablation study로 진행하여 위의 테이블처럼 나타내고 있습니다. 데이터셋은 waymo dataset을 사용했다고 합니다.
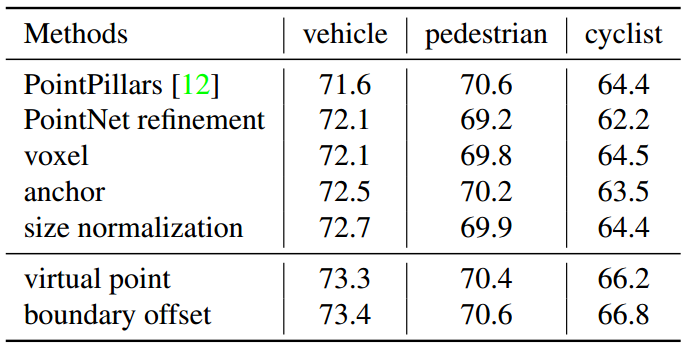
또한 위의 결과도 동일한 waymo dataset에서 3개의 클래스를 학습한 결과입니다.
이후에도 다양한 실험들이 있는데, 실험결과 및 성능이 좋아짐에 따른 결과들은 직접 논문을 참고하셔도 될 것 같습니다.
리뷰 잘 읽었습니다. 결국엔 요약하자면 3D detection은 크게 voxel화 하는 방법과 point기반의 방법론들이 있는데, real-time으로 working하게 하기위해서 point기반의 방법론을 골랐으며, point기반 문제들에서 발생하는 size ambiguity로 인해 생기는 빈공간에 대한 문제를 해결했다. 그리고 그 방법에는 크게 2가지 Boundary offset, Virtual point가 있으며 boundary에 대한 offset의 정보를 이용하거나 background point를 추가하여 사용하였다. 라고 이해하면 되나요?
기존 3D object detection에서 예측한 proposal bounding box를 refine하는데 있어서 기존 방법론에서 발생하는 size, classification ambiguity에 대해서 처음으로 이야기하고 이 문제를 해결하기 위한 refine단계에서 사용될 수 있는 boundary offset과 virtual point를 제안한 논문입니다. 설명을 다시드린 이유는 해당 방법은 voxel기반의 디텍션 모델에서 추출된 proposal에 대해서도 refine단계에서는 사용될 수 있기 때문에 point기반의 방법에만 한정시킨것으로 설명하고 계셔서 다시 설명드립니다.