이번 리뷰는 역시나 Image translation 논문을 가져와봤습니다. 아마 당분간은 CVPR2021에 나온 Image Translation 기반 논문들을 쭉 읽으면서 리뷰할 것 같습니다.
Introduction
일단 Image to Image Translation을 줄여서 I2IT라고 부르겠습니다. 해당 논문에서는 I2IT 방법론들 중 보다 Photo-realistic하고 high resolution으로 생성이 가능하며, 속도도 빠르게 동작하는 방법론을 제안하고자 합니다.
기존의 I2IT 방법론들(Conditional GAN, CycleGAN 등)은 입력 영상을 encoder에 태워서 저차원의 latent space로 투영시킨 후, decoder를 통해 해당 latent code를 새로운 영상으로 reconstruction 합니다.
하지만 저자는 이러한 방식들이 영상을 전체적으로 조작 및 수정하며, high resolution image를 생성하고자 할 때는 수 많은 커널과 feature map들에 대하여 컨볼루션 연산을 하다보니 연산량이 많아지게 된다고 합니다.
즉 low-resolution 영상밖에 못만들거나, high resolution으로 만든다고 하더라도 너무 오랜 시간이 걸리게 되어 실용적이지 못하다는 뜻이죠?
보다 사실적이게 영상을 생성하고자, 최근에 연구들은 컨텐츠와 양쪽 도메인의 속성을 disentangle 시키는 방향으로 집중하고 있습니다.
하지만 이 방식도 결국 down-up sampling 연산을 지속적으로 진행하기 때문에, 모델 추론에 있어 시간이 오래 걸린다는 단점은 계속해서 존재합니다.
대략적으로 기존의 문제점을 정리해보자면, 첫번째는 영상 전체에 대해서 무작정 모델을 태워 새로운 도메인의 영상을 만들고자 하니 low-resolution 영상은 꽤나 생성되었을지 모르지만, high resolution 영상을 생성할수록 영상의 퀄리티가 좋지 못하다는 점이 있었습니다. 둘 쨰는 영상을 down sampling하고 up sampling하는 과정에서 영상이 high resolution이면 컨볼루션 연산이 방대해지다보니 속도적인 측면에서 많은 단점이 존재하구요.
그래서 해당 논문에서는 영상을 frequency 관점으로 접근하여 I2IT를 하는 방법론을 제안합니다. 저자는 특정 도메인의 특유한 속성들(조도, 색채 등)은 영상의 low-frequency 영역에 속하며 반대로 영상 속 컨텐츠의 디테일한 정보들은 high-frequency 영역에 존재한다고 합니다.
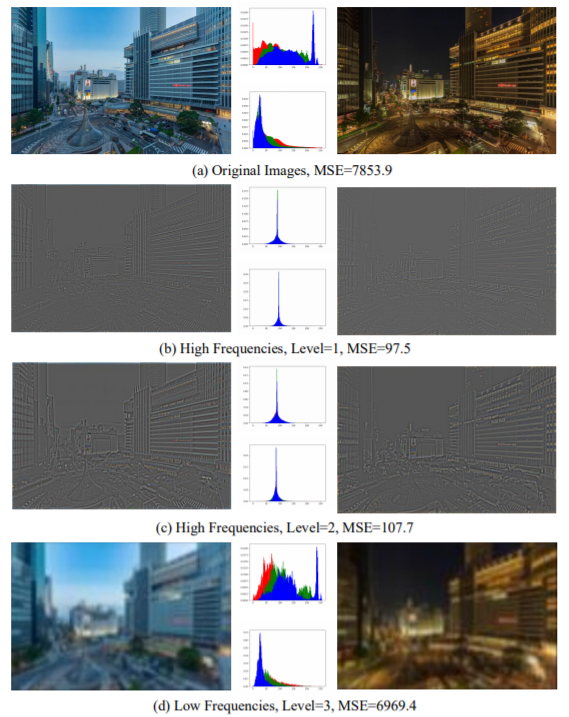
그림1을 보시면 저자가 하고자 하는 말을 정확하게 이해하실 수 있습니다. I2IT 방법론들이 하고자 하는게 결국 입력 영상의 컨텐츠는 살리고, 새로운 도메인의 스타일을 입히자는거죠? 위에 그림1이 I2IT의 목적에 매우 부합하는 예시라고 보시면 될 것 같습니다.
먼저 해당 영상은 동일한 장면에 대해서 서로 다른 시간대인 낮과 밤에 촬영한 영상들인데, 동일한 장면은 두 영상이 동일한 컨텐츠를 가지고 있다고 보시면 될 것 같으며, 서로 다른 시간대는 서로 다른 두 도메인을 가지고 있다고 보시면 됩니다.
자 그러면 이제 저자가 말한대로 영상의 frequency 관점에서 접근해봅시다. 첫번째 행은 두 원본 영상에 대해서 MSE, 히스토그램 분포, 그리고 정성적인 결과등을 확인할 수 있습니다. 어떠한 지표를 보더라도 서로 매우 다르다는 것을 한눈에 확인할 수 있죠?
그런데 2,3번째 행을 보시면 아까의 경향과는 많이 다른 것을 확인하실 수 있습니다. 영상의 고주파 성분으로 비교하였을 때 MSE 값도 원본 대비 1/71, 1/65배로 줄어든 것을 볼 수 있으며, 히스토그램 분포도 매우 유사합니다. 그리고 정성적으로만 봐도 어디가 낮에 촬영된 장면이고, 밤에 촬영된 장면인지 구분하기가 어렵습니다.
영상을 저주파 성분으로 비교하였을 때는 원본 영상에서 비교했던 것처럼, MSE 값도 크게 나오고 히스토그램 분포도 서로 많이 다르며, 정성적으로 보았을 때도 두 영상의 시간대가 다른 것을 한눈에 확인할 수 있네요.
즉 요약하자면 영상의 domain-specific한 속성들은 저주파 성분에 존재하며, 고주파 성분은 영상의 컨텐츠를 잘 표현하고 있다는 볼 수 있으며 이에 대한 증명이 그림1에 잘 나와있습니다.
저자는 이러한 발견을 통해 영상의 고-저주파 성분을 활용한 새로운 Laplacian Pyramid Translation Network를 제안합니다. 매우 가벼운 네트워크를 만들어 저주파 요소들을 translate하여 domain-specific 속성들을 새롭게 가져오도록 하였으며, 영상을 고해상도로 생성하기 위하여 고주파 성분들을 adaptive하게 적용합니다.
Method
Framework Overview
논문에서 제안하는 Laplacian Pyramid Translation Network(LPTN)은 end-to-end 방식으로 동작하며, 연산량의 부담을 줄이면서 동시에 photo-realistic한 I2IT를 진행할 수 있다고 합니다.
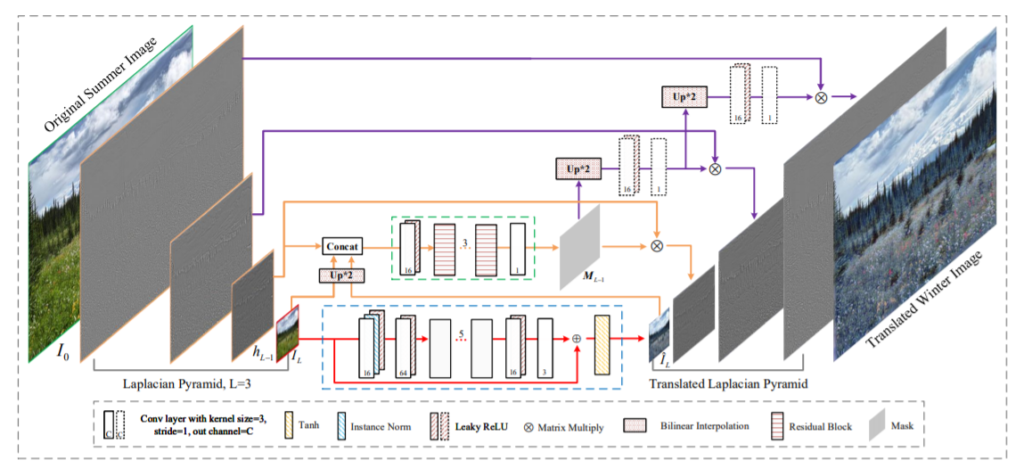
.그림2를 살펴보면, 먼저 입력 영상I_{0}을 분해하여 Laplacian pyramid를 만들게 됩니다. Laplacian Pyramid와 이를 구성하는 각 층들은 H = [h_{0}, h_{1}, ...,h_{L-1}]로 표현하였으며, 저주파 성분만이 남은 영상을 I_{L}로 표현합니다.
각 층별로 영상의 해상도가 \frac{h}{2^{L-1}}, \frac{w}{2^{L-1}}로 줄어들게 되며, 저주파 성분이 남은 영상 I_{L}의 경우 \frac{h,w}{2^{L}}를 가지게 됩니다.
고주파 영상은 영상 속 디테일한 텍스쳐를 표현하는 픽셀을 제외하고는 대부분 0에 가까운 값들을 가지고 있으며, 저주파 영상은 주변 이웃 픽셀들의 평균값으로 계산되어 블러된 영상으로 보입니다. 그리하여 저주파 영상 I_{L}은 영상의 컨텐츠(고주파)와는 독립된 영상의 글로벌한 속성만을 반영하게 되는 것이죠.
저자는 이러한 특성들을 고려하여 low resolution을 가지는 저주파 영상 I_{L}을 \hat(I_{L}로 변환시키는 작업을 하고, 변환된 영상을 단계별로 up-sampling한 다음 고주파 성분과 잘 융합할수 있도록 학습 가능한 마스크를 곱해준다고 합니다. 아래에서 자세하게 살펴보시죠.
Translation on Low-Frequency Component
위에서도 설명드렸다시피, 영상의 저주파 성분들이 domain-specific한 속성들을 가지고 있다고 얘기했었죠? 저자는 속도의 효율성을 위해 low resolution의 저주파 영상을 가지고 image translation을 먼저 진행하게 됩니다. 영상의 해상도가 작으므로 계산 복잡도가 크게 줄어들게 되겠죠.
그림2에서 살펴보시면 I_{L}는 먼저 feature map의 채널을 확장시키기 위하여 1 × 1 컨볼루션 연산을 수행합니다. 그러고 나서, 5개의 residual block이 스택된 구조를 통과하게 됩니다. 각 블럭은 3 × 3 크기의 커널 연산을 수행하는 2개의 컨볼루션 레이어가 존재하며 사이사이에 leaky ReLU가 존재합니다.
아무튼 해당 블럭들을 다 통과하게 되면 최종적으로 출력 영상에 맞게끔 채널 수를 조정하게 되며 마지막으로 해당 feature와 원래의 input I_{L}를 더한 후 Tanh layer를 통과하게 됩니다.
저자는 자신들의 네트워크가 크게 시간적, 공간적 효율성과 disentanglement& reconstruction 효율성에서 이점을 챙길 수 있다고 합니다. 먼저 Laplacian Pyramid를 통해 고주파와 저주파 성분을 분해하는 과정은 고정된 kernel을 사용하는 것이므로 학습할 파라미터가 줄어들게 되어 효율적이게 됩니다. 이는 기존의 방법론들이 저차원의 latent code를 만들기 위해 auto-encoder를 학습시키면서 발생하는 문제점들을 해결할 수 있게 되죠.
또한 그림1에서 볼 수 있듯이, 고주파 저주파 성분만으로 충분히 효율적으로 영상의 스타일을 disentangling 할 수 있었다고 합니다. 하지만 기존의 방법론들은 모델의 크기와 disentanglement/reconstruction 효율성 사이에 trade-off를 해결하는데 있어 큰 문제를 직면한다고 하네요
Refinement of High-Frequency Components
Domain-specific한 속성들을 조합할 때 보다 정교하게 영상을 재생성하기 위해서는 당연히 고주파 성분들도 고려해주어야 합니다. 위에 Framework overview에 대하여 설명할 때 h_{L-1}, I_{L}, \hat(I_{L})의 정의에 대해서 설명드렸죠.
영상을 reconstruction 하기 위해서 먼저 I_{L}과 \hat(I_{L})에 대해 bi-linear upsampling을 진행함으로써 h_{L-1}의 해상도와 크기를 맞춥니다. 그 다음으로 upsampling 된 I_{L}, \hat(I_{L})와 h_{L-1}를 concatenate를 한 다음에 그림2에서 볼 수 있는 작은 네트워크(latex]M_{L-1}[/latex])에 태웁니다.
M_{L-1}의 출력은 h_{L-1}의 픽셀 마스크로 볼 수 있으며 마스크이므로 채널 사이즈가 1입니다. 그림1에서 보시다시피, 두 도메인에 대한 영상에서 고주파 성분은 오직 전체 밝기 값이 미세하게 다르다는 차이만 존재하게 됩니다.
그러므로 해당 마스크는 영상의 전체적인 조정을 수행하는데 있어 상대적으로 주파수 성분들이 섞인 영상에 비해 최적화가 더 쉬워지게 됩니다. 그리고 이렇게 새로 조정된 영상을 다음과 같이 정의합니다.
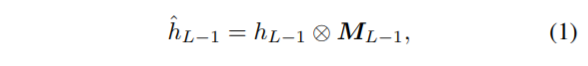
저 수식의 연산은 pixel-wise multiplication을 의미합니다.
아무튼 그러고나서, 이러한 per-pixel mask M_{L-1}는 점진적으로 up-sampling 되어 최종적인 출력 해상도 h × w가 되게 됩니다. 즉 매 층마다 2배씩 bi-linear interpolation을 수행한 후 가벼운 컨볼루션 블럭을 통과하여 fine-tuning을 하게 되죠.
그렇게 커지게 된 mask들은 수식1과 같이 고주파 성분과 pixel-wise multiplication을 수행하게 됩니다.
Qualitative Result
그럼 먼저 정성적인 결과부터 살펴봅시다. 해당 논문에서는 photo-realistic I2IT task로 day-night, summer-winter, photo retouching을 진행하였습니다.

비교 실험으로 사용된 방법론들은 CycleGAN, UNIT, MUNIT을 사용했다고 합니다. 저자는 자신들의 방법론이 기존의 I2IT 방법론들처럼 잘 동작하면서 동시에 자신들만이 4K 영상을 생성할 수 있다고 강조합니다.
보다 자세하게 살펴보면, 그림4.a에서 LPTN의 결과는 보다 적은 텍스쳐 왜곡을 보이는데 노란색과 붉은색 박스로 줌인 된 영역을 살펴보시면 입력 영상과 결과 영상의 텍스쳐 정보가 큰 차이가 없음을 확인할 수 있습니다. 특히 구름이 잘 살아있네요.
CycleGAN의 경우 비교 방법론들 중 LPTN 다음으로 좋은 성능을 보이고는 있으나 구름에 심한 왜곡이 존재하며 또한 노란색 박스 영역을 잘 살펴보시면 빌딩 위에 붉은색 효과들도 존재하는 모습입니다. 그 외에 다른 방법론들도 하늘이 다소 과하게 검은 모습 등을 보이는 등 만족스러운 결과를 보여주지 못하고 있습니다.
저자는 이러한 원인이 고해상도 영상을 생성하는데 있어 디코더 능력의 한계가 존재하기 때문이라고 합니다. 허나 LPTN의 경우 영상을 여러 주파수 단위로 구분하여 reconstruction 하므로 디코더의 한계를 극복할 수 있었다고 이야기 합니다.
또한 3번째 행에 photo retouching의 경우 더 큰 결과 차이를 확인하실 수 있습니다. Photo retouching에 대해서 먼저 설명드리자면 입력 영상과 목표 영상 사이에 global tone( color or illuminations)의 차이를 줄이는 것 입니다.
기존의 I2IT 방법론들은 그림4.c을 보시면 아시다시피 좋지 못한 결과 또는 완전히 불안정한 결과들을 보여줍니다. 특히 UNIT의 경우 하늘과 구름이 어두워지며 마치 먹구름을연상 시키네요. MUNIT의 경우 얼핏보면 좋아보이지만 영상의 테두리 부분에 검정색 줄들이 그여있는 모습을 확인하실 수 있습니다. 하지만 LPTN의 경우 실제 GT 영상과 거의 유사한 것을 확인할 수 있습니다.
Quantitative Result
다음은 정량적 결과입니다.
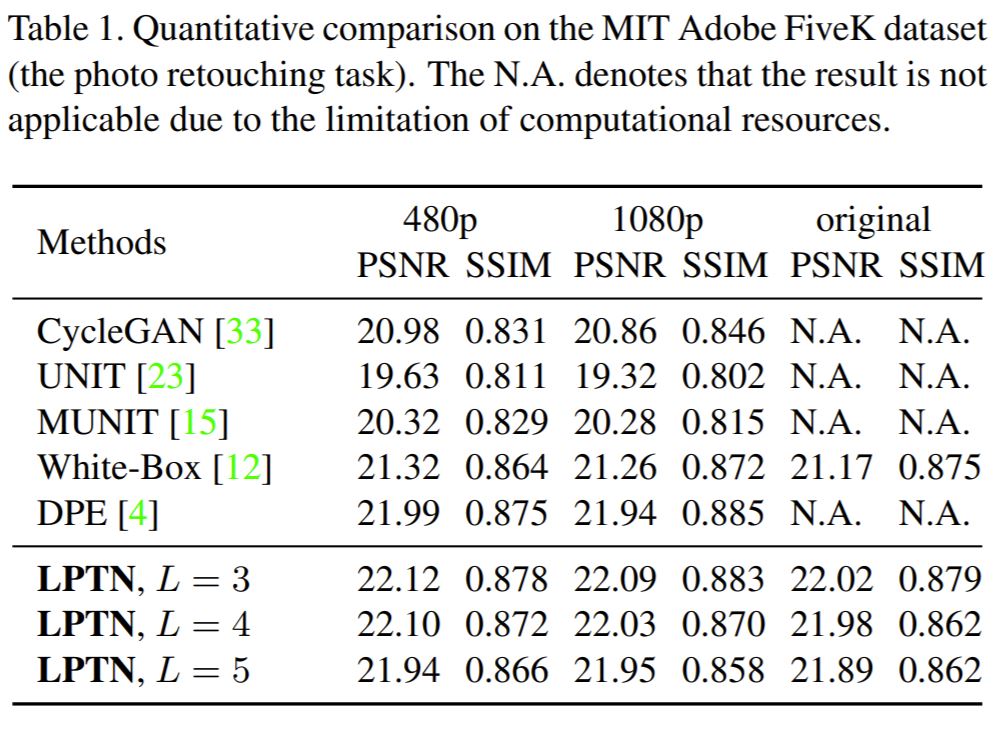
표1은 Adobe FiveK 데이터셋에 대하여 photo retouching 결과를 정량적으로 나타낸 것입니다. 총 3가지의 해상도(480, 1080, 3000 x 2000 ~ 6000 x 4000)에 대하여 정량적 결과를 보였는데 모든 해상도 대역과 평가메트릭에서 가장 좋은 성능을 보였습니다.
정성적 결과(그림4.c)에서도 확인하셨다시피 기존의 I2IT 방법론들의 photo retouchin 결과가 좋지 못한데, 이는 Adobe FiveK 데이터셋이 상대적으로 크기는 작은 반면에 테스트 셋의 장면이 매우 다양하여 디코더가 충분히 학습되기 어렵다고 합니다.
그러나 LPTN의 경우에는 고주파 성분을 adaptive하게 조정함으로써 reconstruction 능력을 잘 보존하였기에 해당 데이터셋으로도 충분히 좋은 모습을 보였다고 하네요.
Running Time
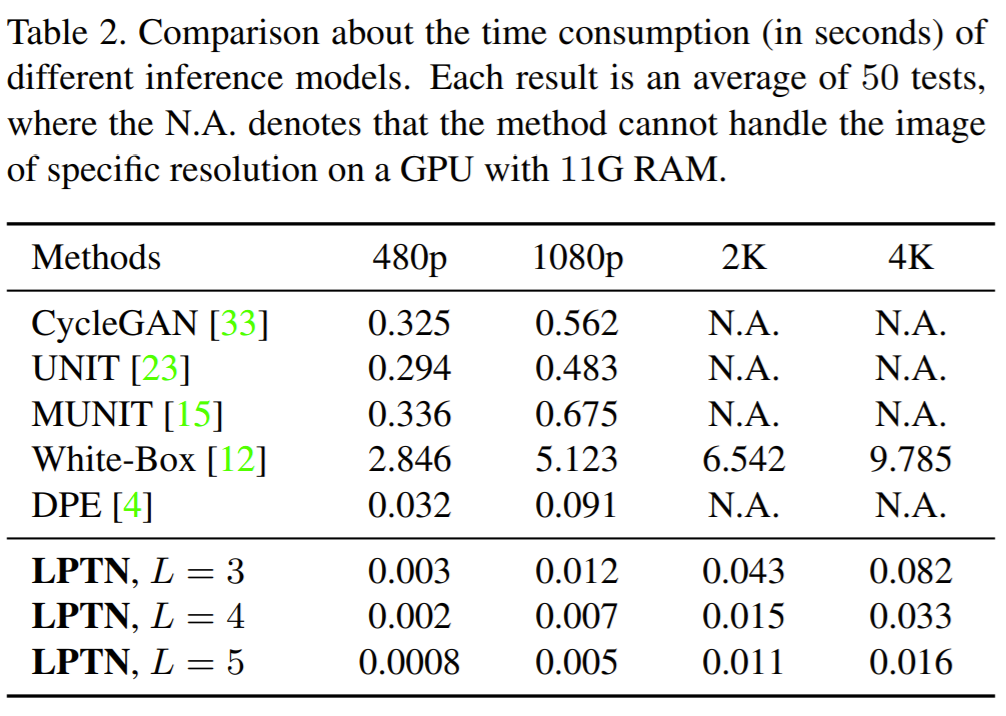
다음은 논문에서 입이 닳도록 자랑하던 inference speed에 대해 확인해봅시다. 테이블2는 50장의 test 영상을 각 해상도별로 inference할 때 평균 속도를 측정한 결과입니다. 보시면 LPTN의 속도가 모든 해상도에서 뛰어난 모습을 보이고 있으며 2K, 4K 영상도 만들 수 있습니다. 허나 White-Box라는 방법론을 제외하고 다른 방법론들은 2K이상의 영상을 만들지는 못하고 있네요.
결론
확실히 CVPR2021 논문답게 여러 측면에서 상당히 좋은 모습을 보여주는 방법론이었습니다. Image to Image Translation 방법론들의 가장 큰 단점이었던 고해상도 영상 생성 및 inference 속도를 완벽하게 해결하였으며, 성능 역시도 다 방법론들 대비 꿀리지 않는 모습을 보였기 때문이죠.
한가지 아쉬운 점이 존재한다면 photo retouching 뿐만 아니라 실제 Image Generation(day to night, summer to winter 등)에서도 정량적 결과를 보였으면 좋았을텐데 이를 보이지 않았다는게 많은 아쉬움이 남아있습니다.
고주파와 … 컨텐츠…굉장히.. 아쉬운 저희의 목표중 하나였네요…
그래도 저희가 했던 실험중에 저런 목표가 있었다는게 가능성이 있지 않나 싶네요