이번 리뷰 논문은 Meta-learning이 적용된 Visual odometry(VO) 입니다.
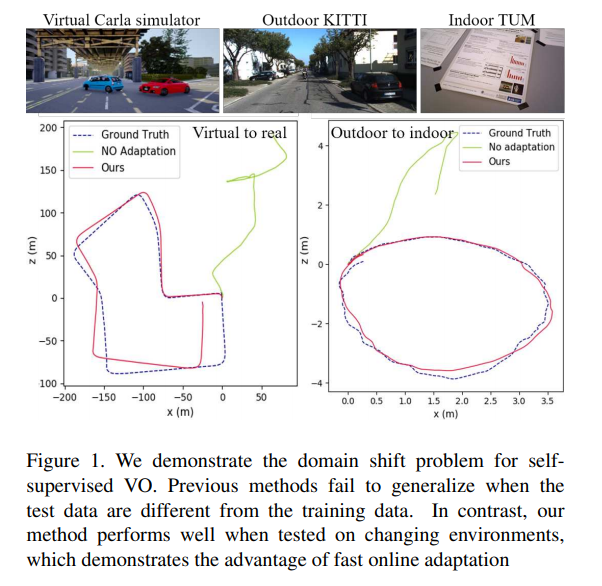
전통적인 기법의 VO는 상태 변화(조도, 가려짐, 움직이는 물체, testureless region)에서 성능이 저하되는 한계를 보였습니다. CNN의 발전으로 learning-based VO에서 상태 변화에서 강인성을 보였습니다. 하지만 fig 1과 같이 데이터 셋의 변화, 즉 어떤 dataset에 학습된 pre-train된 VO를 open world(실제 application)에 적용 시, 성능이 제대로 나오지 않는 문제가 있습니다. 이를 해결하기 위해서 새로운 환경에 지속적으로 적응되어야 합니다. 저자의 말을 인용하자면 “we learn as we perform”을 수행되어야만 합니다. 이를 수행하기 위해 나이브한 meta-learning 기법을 VO에 맞게 시간적 요소가 고려된 Online adaptation과 새로운 환경에서 추출된 feature에 대한 domain adaptation을 소개합니다.
(모르는 분들을 위해 추가적인 설명을 하자면 Meat-learning은 새로운 환경에 적응하기위해 test 도중 학습 파라미터를 최적화 시키는 기법입니다.)
Base-Method
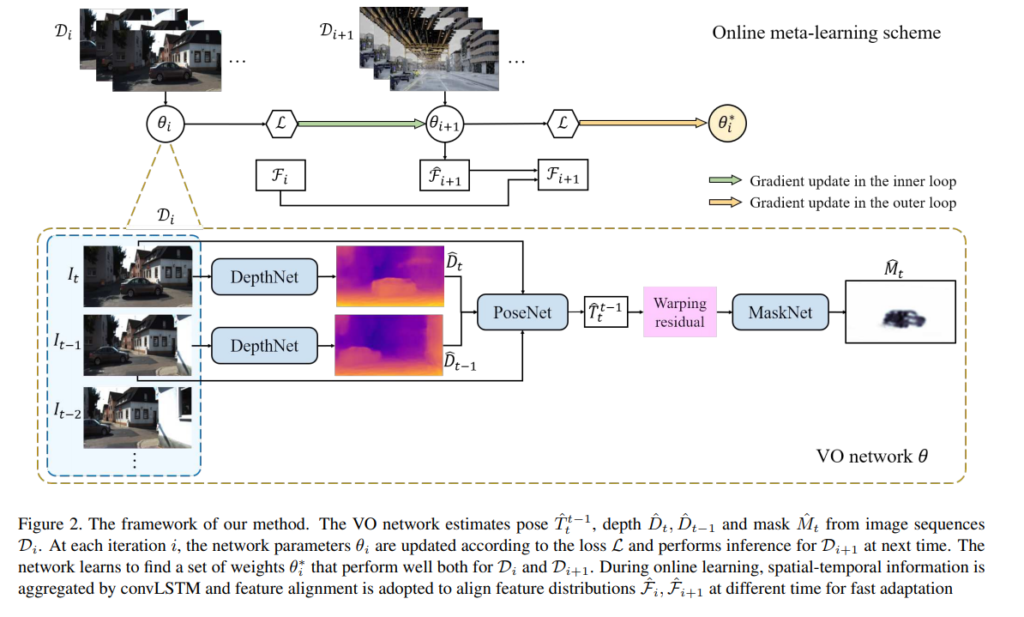
Self-supervised VO
해당 방법론은 SfM-Learner와 SAVO(Fig 2.)를 base model로 사용합니다.
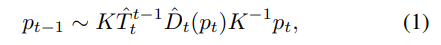
두 연속적인 영상 I_t, I_t-1을 DepthNet을 통해 깊이 지도 ^D_t, ^D_t-1을 추정합니다. 추정된 두 깊이 지도는 PoseNet을 통해 추정된 pose ^T_t^t-1을 추정합니다. 이 정보를 토대로 수식 1을 이용하여 I_t-1을 와핑하여 재구성된 ^I_t을 이용하여 최적화를 이루는 방법론입니다. p_t, p_t-1는 Homogeneous coordinates, K는 camera intrinsics에 해당합니다. 해당 방법론에서는 상태 변화에 강인성을 가지기 위해 추가로 MastNet을 이용하여 mask ^M_t를 추정하여 의미가 있는 픽셀만 보도록 처리를 합니다.
(해당 방법론에 대해서는 추후 x-review를 통해 자세히 설명하도록 하겠습니다. 논문에서는 2-column. 9줄로만 설명이 되어 있어 이해하기가 어렵네요.)
Online adaptation
위에서 설명한 내용대로 learning-based VO는 train set의 분포만 학습하기 때문에 새로운 환경이 반영된 test set에서는 성능이 저하됩니다. 이를 해결하기 위해 나이브한 Meat-learning 기법(수식 2)을 베이스로 사용합니다.
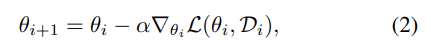
하지만 수식 2와 같이 나이브한 기법은 프레임과 프레임 사이의 정보를 이용하는, 즉 시간적 정보가 사용하는 기법에서는 적합하지 못합니다. 시간적 측면에서는 L(theta, D_i)는 현재의 입력 D_i만 고려되기 때문에 상관 관계가 1에 해당합니다. 이는 이전의 정보와 연관이 없다는 해석이 됩니다. 그러므로 수식 2는 공간적인 정보만 활용되어 최적화되기 때문에 수렴이 느리고, 오히려 나쁜 방향으로 학습될 가능성이 있습니다.
Method
바로 위 섹션에서 제시한 문제를 해결하기 위해, 저자는 수식 2에 시간적인 정보를 추가합니다. 즉 수식 3과 같이 D_i와 D_i+1을 활용하고자 합니다.
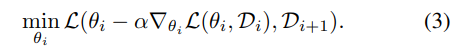
이는 train error를 test error를 통해 최적화 시키는 방법론 Model Agnostic Meta Learning(MAML)에서 제안한 방법에서 영감을 얻어 시간적 정보를 추가한 방법론에 해당합니다. (보다 자세한 내용이 궁금하신 분들은 MAML 논문을 보시기 바랍니다.)
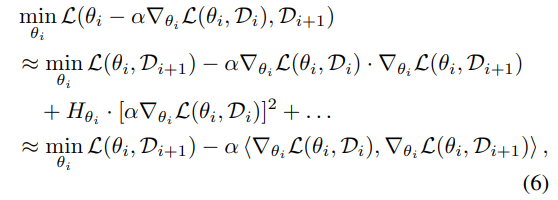
저자는 수식 3을 보다 간략하게 표현하기 위해 수식 6과 같이 테일러 급수를 해석합니다. 여기서 Hessian matrix H는 해당 모델이 ReLU를 이용합니다. 그렇기에 부분적인 부분은 선형성을 가지기 때문에 2차 도함수 부터는 0에 해당하기 때문에 2차식 부터는 0이기 때문에 수식 6의 세번째 수식으로 간단하게 표현이 가능하게 됩니다.
해당 수식의 첫번째 항은 서로 다른 분포를 가진 데이터(독립적인 시간, 장면)를 가지고 최소화를 이루기 때문에 해결하고자 하는 문제를 직접적으로 풀어갑니다. 하지만 이는 서로 다른 방향을 가지기 때문에 느린 수렴을 유발합니다. 이에 반해 두번째 항은 D_i와 D_i+1을 일관성을 가지도록 강제합니다. 이를 통해 gradient problem을 완화하는 역할을 하여 수식 2보다 덜 예민하고 시간적으로 적응적인 meta learning이 가능하도록 합니다.
Spatial-temporal aggregation
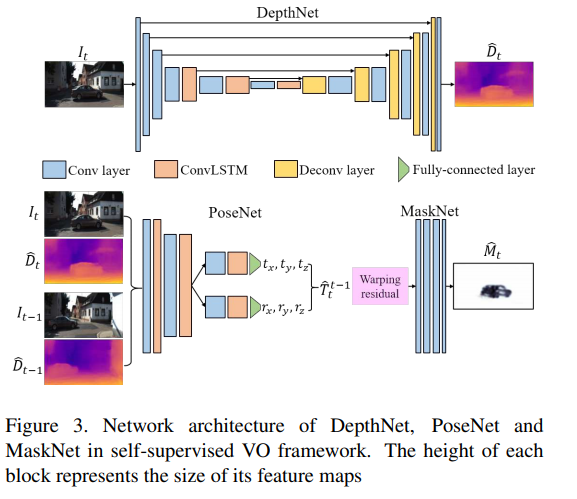
Meat learning은 느린 수렴을 가진다는 문제가 있습니다. 저자는 이를 해결하기 위해 추가적으로 시간적인 정보를 주기 위해 DepthNet과 PoseNet에 convLSTM을 추가합니다(Fig 3). 해당 방법은 서론 다른 시간대에 상관 관계를 부여하는 것 뿐만이 아니라 시가적으로 동적인 장면에서도 강인한을 가져옵니다.
Feature alignment
새로운 환경에서 추정된 feature는 학습에서 사용된 feature와 다른 분포를 가지는 문제를 해결하기 위해 이전 환경과 새로운 환경에서의 Domain adaptation 기법을 소개합니다. 해당 부분은 매우 간단합니다. Layer Normalization(LN, 수식 7)을 변형하여 사용합니다.
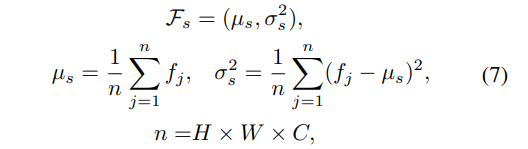
시간적 정보를 활용하기 위해 수식 8과 같이 i=0으로 초기화합니다

이전의 정보를 연속적으로 가져가기 위해 수식 9와 같이 이전의 정보를 보정합니다.
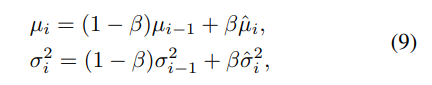
그 후 수식 10과 같이 값을 feature를 정규화 합니다.
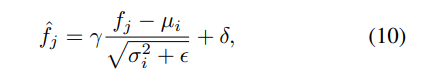
Loss functions
Appearance Loss(수식 11)는 수식 1을 최적화 하기 위한 SSIM Loss와 MaskNet을 최적화 하기 위한 수식 11의 첫번째 Loss와 regularization term이 적용됩니다.
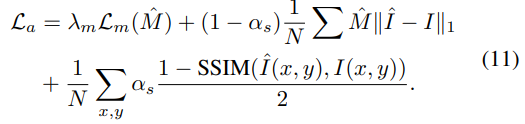
Depth regularization(수식 12)는 edge-aware loss와 local smoothness loss를 이용합니다.
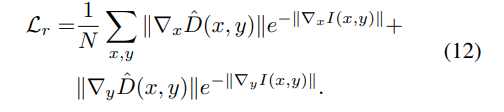
전체적인 Loss는 수식 13을 통해 계산되어집니다.
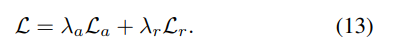
(Loss에 대한 설명은 base 논문을 참조했기에 추후 x-review를 통해 자세히 다루도록 하겠습니다.)
Experiments
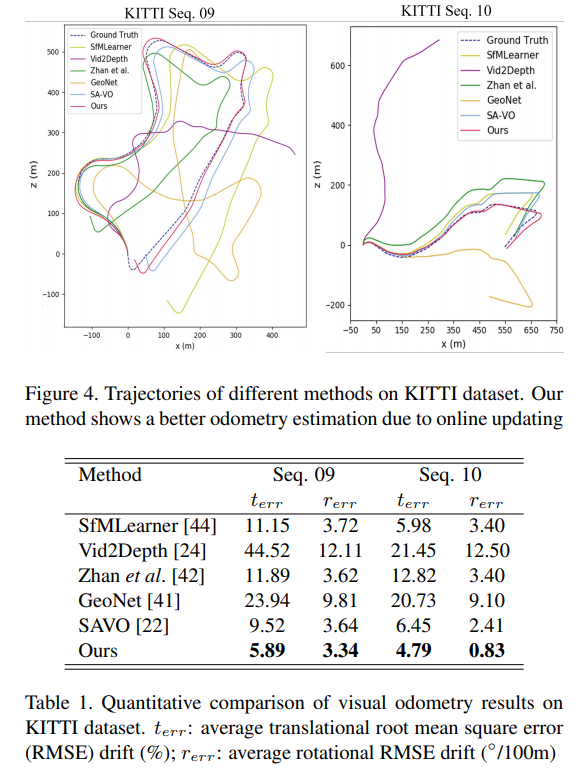
Fig 4와 Table 1는 Meta가 아닌 datasets(train과 test가 같은 데이터 셋)에서 평가한 정량적/정성적 결과 입니다. 해당 결과에서도 강인한 성능을 보여줍니다.
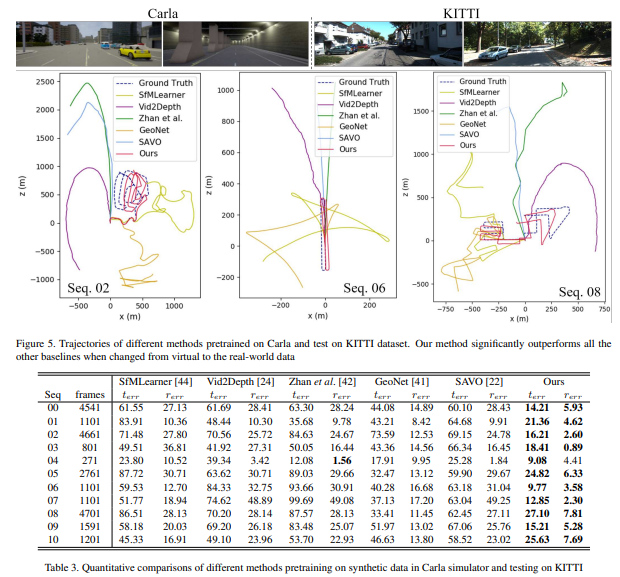
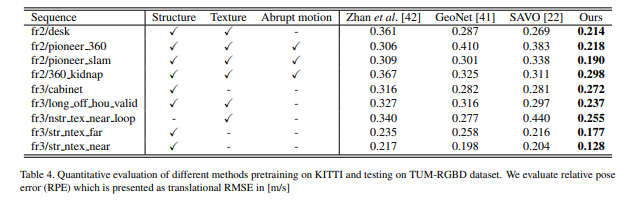
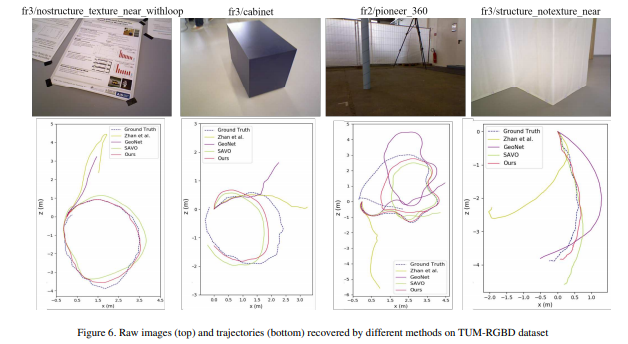
흥미로운 부분이 Fig 1, 5, 6과 Table 4에 해당합니다. fig 1, 5는 train:Carla, test:KITTI00-08에서 평가하였습니다. 다른 방법론들은 제대로된 성능을 보이지 못하는 모습을 보이는 반면에 제안한 방법론은 어느정도 성능을 가지는 것을 볼 수 있습니다. Fig 6과 Table 4(train:KITTI test:TUM-RGBD(indoor))에서의 정량/정성적 평가 결과입니다.
허허 글 잘 읽었습니다.
이번에 리뷰에서 다루시는 논문이 수식이 상당히 많고 복잡하기에 보다 친절하게 작성해주셨으면 더 좋았을 듯 합니다. Latex 기능을 활용하시면 보기 더 좋겠네요^^