Before Review
이번 Review는 GAN으로 준비했습니다. GAN에 대해서는 이미 한번 2014년도에 나온 Ian Good fellow 가 제안한 원조 GAN을 Review를 진행한바 있습니다. 오늘은 그 연장선상에 있는 DCGAN이라 불리우는 Network에 대해 준비했습니다. GAN에 대해 기억이 잘 나지 않으신다면 [NIPS 2014] Generative Adversarial Network 을 읽어보시면 될 것 같습니다.
참고로 Ian Good fellow가 이런말을 했다고 합니다.
“Most GANs today are at least loosely based on the DCGAN architecture.” – NIPS 2016 Tutorial by Ian Goodfellow
그만큼 DCGAN의 출현이 GAN의 많은 후속 연구에 영향을 끼쳤나 봅니다. 아무튼 Review 시작하겠습니다.
Introduction
저번 Review에서도 끝부분에 GAN은 사실 학습이 어려운 단점이 존재한다 정도로만 서술하고 마무리를 했던 것 같은데 그런 학습의 불안전성을 잡아주는 것이 GAN의 최대 관심사 였다고 합니다. 이론적으로는 14년도에 발표된 GAN 논문에서 “global optima로 수렴할 수 있다” 이렇게 서술하고 있지만 실제 학습시에는 이러한 가정이 잘 맞지 않는 형태를 보여주면서 GAN은 학습시키기 어렵다는 문제점이 대두되고 있었습니다. 당연히 이제 후속 연구들은 GAN의 안전성을 강화시켜주기 위해 많은 시도들을 해왔고 지금 Review할 DCGAN이 바로 GAN의 안정성을 꽤 잡아주는 모델로써 이후 에 나오는 GAN model들은 대부분 DCGAN을 기반으로 설계 됐다고 합니다.
본 논문에서 저자가 밝히는 Contribution은 다음과 같습니다.
- 대부분의 상황에서 안정적으로 학습이 되는 Convolutional Neural Net기반의 GAN 구조(DCGAN)를 제안했습니다.
- DCGAN이 학습한 filter들을 시각화하여 보여주고 특정 filter들이 이미지의 특정 물체를 학습했다는 것을 시각화 해주고 있습니다.
- DCGAN으로 학습된 Generator가 벡터 산술 연산이 가능한 성질을 갖고 이것으로 semantic 수준에서의 sample generation을 해볼 수 있습니다.
이러한 Contribution들이 뭘 말하는 건지는 차근차근 알아보도록 하겠습니다.
Approach and model architecture
우선 , 기존에도 CNN을 이용해서 GAN model을 안정화 시키려는 시도가 있었고 , 본 논문의 저자들도 한참 어려움을 겪었다고 합니다. 본 Paper에 뭐라 적혀있냐면 “after extensive model exploration we identified a family of architectures that resulted in stable training across a range of datasets and allowed for training higher resolution and deeper generative models” 무수히 많은 실험 끝에 더 높은 해상도와 깊은 model을 쌓을 수 있는 architecture를 찾았다고 합니다. 실험적으로 이런 architecture를 찾았기 때문에 본 논문에서도 구조를 왜 이렇게 만들었다에 대한 설명은 자세히 나와있진 않는 것 같습니다.
사실 그래서 구조적인 측면으로 왜 이렇게 설계했는가에 대한 물음은 DCGAN이후로 또 많은 후속 연구가 진행되었기 때문에 다음 Review에서 다루기로 하고 오늘 Review에서는 architecture가 이렇게 생겼는데 이로 인해서 나타나는 결과들의 의미를 깊게 뜯어봄으로써 DCGAN의 특징을 중점적으로 살펴보도록 하겠습니다.
우선 , Architecture guideline 부터 살펴보겠습니다.

첫번째로는 pooling layer를 모두 없애고 이를 Convolution 연산으로 대체 했다고 합니다. Generator 부분에서 fractional-strided convolutions 라고 나와 있는 데 이는 조금 뒤에서 다시 설명하도록 하겠습니다.
그 다음으로는 믿고 쓰는 BatchNorm을 적용해주었고 좀 더 detail 하게는 Generator 구조에선 output layer에서는 빼주고 , Discriminator 부분에서는 input layer에서는 적용해주지 않는 다고 합니다.
마지막으론 Fully Connected layer를 없애주고 activation 함수들을 어떻게 setting 했는 지 알려주고 있습니다.
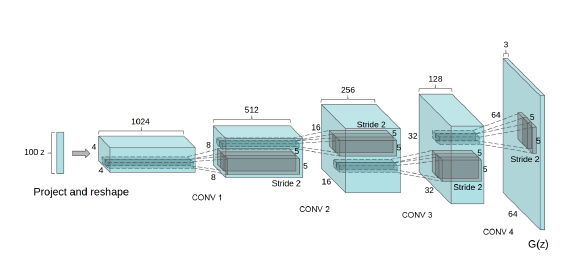
본 paper에서는 Generator의 구조만 그림으로 보여주는 데 Generator는 알다시피 noise vector를 받아서 이를 진짜와 비슷한 이미지를 만드는 것이 목표인 Network 였습니다. 그림에서 보면 차원수가 100인 noise vector z 가 Generator의 input으로 들어가서 무언가 upsampling의 과정을 거치고 있습니다. 최종적으로 나오는 output을 보면 3 x 64 x 64의 RGB이미지가 생성이 됩니다.
그렇다면 noise vector가 어떻게 이미지로 바뀌는 것일까요? 아까 앞에서 얘기했던 fractional strided convolution이 이를 담당해주는 데요 , Transposed Convolutions 이라고도 불립니다.
기존의 Convolution은 예를 들어 4 by 4의 Feature map을 이용해서 2 by 2 Feature map을 만드는 것이었다면 , Transposed Convolution은 2 by 2 Feature map을 가지고 4 by 4 Feature map을 만드는 일종의 Upsampling 과정입니다. Generator 가 학습되는 과정이 바로 이 Transposed convolution filter들의 weight를 학습하여서 낮은 해상도에서 높은 해상도로 이미지를 잘 만들 수 있게 조절이 되게 됩니다.
DCGAN 같은 경우는 Tutorial Code 가 잘 공개되어 있어서 참고를 좀 하자면 (https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html)
- Generator

Generator는 noise vector를 input으로 받아서 이를 4 by 4 … 8 by 8 … 64 by 64의 matrix로 upsampling 해주는 nn.ConvTranspose2d layer들로 구성이 되어 있고 , 사이사이 BatchNorm과 ReLU가 setting 되어 있습니다.
- Discriminator

반대로 Discriminator는 3 x 64 x 64 의 RGB 이미지의 Tensor 형태를 입력으로 받아서 , 흔히 image classification 하는 것처럼 진행이 됩니다. 마지막으로는 Sigmoid를 태워주워서 output을 0~1사이의 값으로 mapping 시키고 0.5보다 크면 1 , 작으면 0 이런식으로 진행이 됩니다.
모델 구조에 대해서는 사실 어렵지 않은 구조라 이 정도로 정리해두고 , 이제는 DCGAN을 이용해서 학습을 진행했을 때 관찰할 수 있는 의미있는 결과에 대해 알아보도록 하겠습니다.
Adversarial Training
DCGAN 논문이 좋다고 생각되는 점은 학습이 잘 이뤄졌는지 확인하기 위한 여러 가지 검증 방법을 설명하고 있다는 점입니다. 뒤의 단락에서도 계속 얘기하겠지만 DCGAN이 잘 학습이 되었다는 점을 저자는 계속 정성적 결과들을 보여주면서 나름 합리적인 이유로 설명하고 있습니다. 우선 먼저 LSUN 데이터 셋을 이용해서 GAN 만들어낸 생성 이미지를 빠르게 확인 해보겠습니다.
- Only one epoch training

위의 사진은 DCGAN이 epoch 한번만 돌렸을 때 만들어낸 생성 사진들 입니다. 보고 어떤 느낌을 받으셨나요? 꽤나 그럴듯하게 만들어 낸것을 확인할 수 있는데 , 이게 epoch 한번 돌렸을 때의 결과물입니다.
epoch를 한번만 돌렸는데 저렇게 이미지를 만들어 낸다는 것을 무엇을 의미하는 것일까요? 우선 , epoch는 한번만 돌렸기 때문에 overfitting 됐다라고 얘기할 수는 없습니다. 즉 , Network는 이미지를 암기(overfitting , memorization)해서 만든 것이 아니라 이미지의 분포를 잘 학습해서 만들어 냈다 이렇게 해석할 수 있습니다.
- Five epoch training

다섯번 정도 epoch을 돌려보니 나름 정교한 이미지들이 생성되고 있습니다.
Investigating and visualizing the internals of the networks
DCGAN이 논문에 기재한 분석에는 조금 흥미롭고 대단한 점이 많습니다. 사실 저는 이부분이 이 Paper의 핵심이라고 느껴지는데 GAN 같은 경우는 이 Network가 잘 작동하고 있는지 , 안정적인 지에 대한 분석을 내놓기가 쉽지 않은 부분이 있습니다. 하지만 DCGAN Paper에서는 나름 인상깊은분석들이 많이 나와있습니다. 하나씩 살펴보도록 하겠습니다.
Walking In the Latent Space
Walking in the latent space 표현이 참 처음 봤을 때는 애매모호한데 , 풀어서 얘기하면 Generator로 들어가는 input vector들을 조금씩 바꿔가면서(Walking in the Latent Space) input으로 넣었을 때 이미지에 어떤 양상으로 변화가 일어나는 지를 분석하는 부분입니다.
자 , noise vector들을 조금씩만 바꿔서 넣어준다는 것은 어떤 목적으로 하는 것일까요? 우리는 Network가 단순히 Overfitting 되어서 noise vector 하나당 image 하나씩을 mapping 시켜버리는 , 이미지를 그냥 외워버리는 현상을 원하지 않습니다. DCGAN은 우리의 architecture가 image를 외워서 만들어내는 것이 아니라 이미지의 특성 , 분포를 잘 학습해서 만들어 내는 것이다라고 주장하기 위해 이런 주장을 펼칩니다.
” noise vector들을 조금씩 바꿔가면서 이미지를 Generate 할 때 , 갑작스러운 변화가 생긴다면 이는 Network가 image를 memorization 했다고 볼 수 있지만 , 부드러운 변화가 생긴다면 , 이는 Network가 image를 외워서 생성하는 것이 아니라 이미지의 distribution을 잘 학습한 것이다. “

input noise vector들을 조금씩 변화시켜 주었을 때(어떤식으로 변화를 준다는 얘기는 나와있지 않아서 추측하건데 아마 vector 성분들을 조금씩 바꾸는 것 아닐까요..?) 이미지들이 조금씩 변화하는 양상을 보여주고 있습니다.
이러한 양상은 DCGAN이 image distribution을 잘 학습 했구나를 간접적으로 알 수 있습니다.
Visualizing the Discriminator Features

또한 filter들을 어떤 object에 집중하는 지를 어떻게 잘 시각화해서(이 부분은 구체적으로 어떻게 진행했는 지 잘 이해가 가질 않았습니다) 보여주고 있는데 네트워크 내부의 각 필터는 이미지를 이해할 수 없는 형식이 아닌 특정 object나 특징을 추출하였음을 확인할 수 있습니다.
Forgetting to draw cetrain objects
또한 신기했던 건 각 특징을 맡고 있는 filter를 dropout 시켜서 이미지를 생성하면 실제로 이미지에서 해당 특징이 사라지는 즉, “학습”뿐만 아니라 “잊어버리는” 것이 가능하다는 것을 보여줌으로서 뭔가 좀 유동적인 모습을 보여주고 있습니다. 뭔가 특징별로 학습이 잘 딱딱 되어 있기 때문에 특정한 filter를 제거해도 별 문제가 생기지 않는 다는 점을 보았을 때 DCGAN은 학습이 꽤나 잘된 Network라는 것을 짐작할 수 있습니다.

위 그림은 창문을 담당하는 filter를 제거했을 때 나타나는 사진입니다.
Vector arithmetic on face samples
저는 이 부분도 굉장히 신기했습니다. 우선 그림부터 먼저 보도록 하겠습니다.

자 , 무언가 뺄셈 덧셈을 하고 있습니다. 조금 충격적이지만 쉽게 정리하면
안경 쓴 남자 – 안경 쓰지 않은 남자 + 안경을 쓰지 않은 여자 = 안경을 쓴 여자
좀 더 설명하자면 noise vector들을 저렇게 산술 연산을 해주고 Generator에 넣어주면 다음의 결과가 나온다고 합니다.
이러한 결과가 얘기해주는 것은 무엇일까요?
Network가 image의 의미를 이해했다 , 단순히 특정한 남자를 생성하는 one to one mapping이 아니라 , 이미지 자체의 특성을 이해 했기 때문에 위와 같은 신기한 결과가 나왔다고 생각이 듭니다.
이러한 분석을 통해 나름 간접적으로 DCGAN이 학습이 잘 되었다는 것을 확인할 수 있엇는데 , 개인적으로 아쉬운 점은 다른 GAN 모델들 까지 저러한 실험을 통해서 무언가 비교분석을 진행했다면 더욱 DCGAN의 위력이 쉽게 전달됐을 것 같은데 이 부분이 빠져있어 조금 아쉬웠습니다.
Conclusion and Future works
DCGAN의 architecture 부분은 CNN 구조를 사용한 것 말고는 딱히 특이한 점은 없습니다. 물론 이런 안정적인 architecture을 어떻게 찾은건지는 신기하지만 덕분에 DCGAN은 GAN의 불안정한 모습을 크게 잡아주었습니다. 하지만 아직 해소해야 하는 부분들이 남아있다고 합니다.
가끔가다 학습시간이 길어지면 mode collapsing 이나 oscillating mode 등의 안정적이지 못한 모습을 보여주곤 합니다.
또한 DCGAN 같은 경우는 CNN을 사용하다 보니 image에서는 비교적 잘 작동하지만 , audio 나 video 같은 경우에는 조금 고민이 필요하다고 합니다.
DCGAN 이후로도 많은 GAN 시리즈가 DCGAN 기반으로 나와 있다고 하니 , 종종 Review 하도록 하겠습니다. Review 읽어주셔서 감사합니다.
[김형준] 아이디 로그인이 안되어서 조원 연구원 아이디로 댓글 남깁니다. 상세하고 이해하기 쉽게 리뷰 작성해주셔서 감사합니다. 음.. DCGAN에 대해서 잘 모르고있어서 작성해주신 리뷰를 보고 기존 GAN보다 학습안정성을 높였다가 DCGAN의 핵심으로 이해를 하였습니다. 그리고 그를 정성적으로 증명한 내용들을 보았습니다. 마찬가지로 비교실험이 없는게 아쉽다고 생각을 합니다. 1 Epoch만 돌려도 정성적으로 잘 나왔고, image distribution을 잘 학습했고, 이미지 특성을 이해하는 방향으로 학습이 되었다는 내용은 이해를 하였습니다. 그렇다면 DCGAN에서 주장하는 “학습안정성”이 더 좋다 라는건 위 실험들과 어떠한 관계가 있는건가요?
제가 생각할 때는 1 epoch만으로도 정성적으로 좋은 결과가 나온 것을 통해 학습안정성을 보이고자 한 듯 싶습니다. 실제로 gan기반 방법론들을 가지고 학습시킬 때 1 에포크만 학습 시킨 경우 좋은 결과를 보이기는 어렵거든요.(물론 데이터셋이 얼마나 어려운지에 따라 다르겠지만…)
Forgetting to draw cetrain objects 실험 부분에 discriminative feature learning을 진행한 결과물이 아닐까 하는데 혹시 이러한 과정을 위해 따로 학습에 사용한 기법이 있나요? 예를 들어 어떠한 feature vector 의 요소를 조절하였을 때 특정 특징값 (ex 창문)이 다른 이미지를 생성하도록 학습하여 feature의 각 요소가 설명가능하게 학습하는 기법입니다. 아니면 학습 해 보니 이러한 discriminative한 특징을 갖게 되었다는 뜻일까요?
리뷰 잘 읽었습니다.
한가지 궁금한 점이 있는데 안경 착용 여부와 성별등을 나타내는 벡터들에 산술연산을 해주면 사용자가 원하는 스타일의 새로운 얼굴을 생성할 수 있다고 나와있네요.
근데 여기서 입력이 노이즈 벡터라고 하셨는데 어떻게하면 사용자가, 어떤 벡터가 안경을 착용한 사람이고 성별이 여자인지 남자인지를 알 수 있나요?