저번 주에 리뷰한 논문에서 언급된 mulit-scale segmentation에 관한 논문을 읽어보고 정리해보았습니다.
Abstract
기존의 SOTA방식은 convolution network를 이용하는 방식으로 이미지 분류를 위해 디자인 된 모델이다. 하지만 semantic segmentation과 이미지 분류는 구조적으로 다르다. dilated convolution은 receptive field가 resolution이나 적용범위 손실 없이 커질 수 있도록 지원한다. 이 논문에서는 이러한 multi-scale의 맥락 정보를 resolution 손실 없이 모을 수 있는 dilated convolution을 이용한 모듈을 제안한다.
Instroduction
이미지 분류는 successive pooling과 subsampling layer로 global prediction을 얻을 때 까지 resolution을 감소시키며 다양한 크기의 맥락 정보를 결합한다. Dense prediction은 multi-scale의 맥락적 추론과 full-resolution output을 결합하여 결과를 얻는다. 이때 mulit-scale의 결과와 full-resolution output의 결과가 상충될 경우에 대해 당시에는 다음 두가지 방법에 대한 연구가 이뤄지고 있었다. 1) downsampled 레이어로부터 global perspective을 수행하며 up-convolution을 반복하여 resolution을 회복하거나 2) input 이미지를 다양한 크기로 변형하여 네트워크에 넣어 예측 결과들을 결합한다. 이러한 방식들은 중간에 downsampling을 할 필요가 있는지, rescaled input을 분리하여 판단할 필요가 있는지 그 필요성이 확실하지 않다.
제안하는 모듈은 pooling과 subsampling이 없는 직사각형 프리즘으로 resolution 손실과 rescaled image 평가가 없는 dense prediction을 위해 고안된 구조로, 어떤 resolution에도 모듈을 사용할 수 있다.
또한 이미지 분류 네트워크의 semantic segmentation으로의 용도 변경을 재검토해본다. 제한된 설정에서의 deep 이미지 분류의 적용을 검토해보고 dense prediction을 방해하는 잔재 요소를 제거해 보았고 그 결과 이전의 적용 모델보다 더 단순하고 정확한 초기의 모듈을 얻었다.(초기의 모델을 이용하는 것이 성능이 좋다)
Dilated Convolutions
F : Z2→ R 가 discrete함수라 하고, Ωr = [−r, r]2∩ Z2, k : Ωr → R는크기가 (2r+1)2인 discrete 필터라 하자.
discrete convolution 연산자 ⁕는 다음과 같이 정의된다.
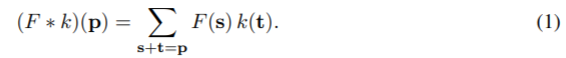
l을 dilation factor라 하고, ⁕l은 다음으로 정의할 수 있다.
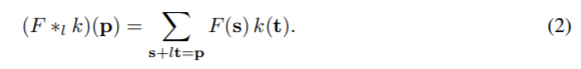
⁕l는 dilated convolution이나 l-dilated convolution이라 하겠다.
* 이전의 dilated convolution은 convolution with a dilated filter로, atrous알고리즘에 사용되었으나 dilated filter를 이용하지 않으므로 dilated convolution이라는 용어를 사용한다.
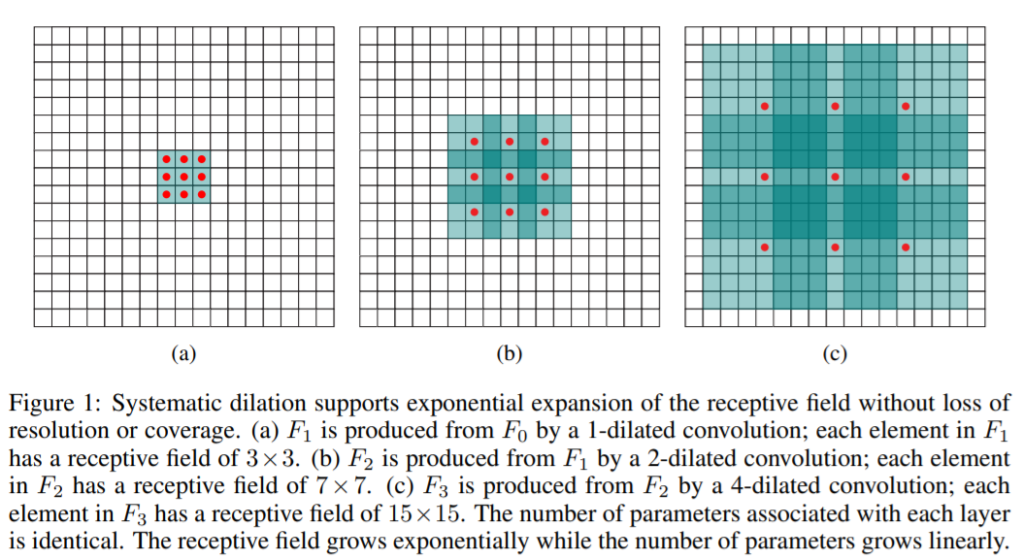
Fi+1= Fi ⁕2i ki (이때, i = 0,1,…,n-2 ) ,k는 3×3 필터로 Fi+1의 receptive field p는 (2i+2-1)2의 크기를 가지고 있다.
Multi-Scale Context Aggregation
context module은 dense prediction architecture의 성능 향상을 위해 디자인 된 것으로 C feature map을 입력으로 가지고 C feature map 출력을 만든다. 입력과 출력이 동일한 형태이므로 어느 dense prediction 구조에도 붙일 수 있다.
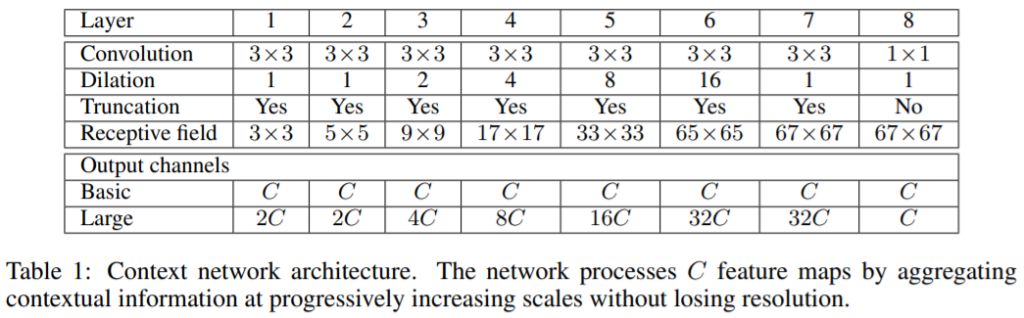
Basic은 모든 레이어의 체널이 C로 동일하고 context network는 1, 1, 2, 4, 8, 16, 1의 dilation(간격)을 가지는 3×3 convolution을 적용하는 7개의 레이어를 가지고 있다. 최종 레이어는 1x1xC convolution을 수행한다. 이때 64×64 크기의 feature map을 context network의 입력으로 사용하므로 6레이어 이후에는 receptive field 크기가 지수적으로 증가하지 않는다.
context module을 초기화하기 위해 random distributions를 이용한 samples를 이용하는 일반적인 방식을 이용해보았고 실험적으로 이러한 방식의 초기화 체계는 context module에 효과적이지 않다는 것을 발견했고 더 효과적인 방식을 발견했다.

a는 input feature map의 인덱스, b는 output feature map의 인덱스이고 identitiy initialization으로 <A Simple Way to Initialize Recurrent Networks of Rectified Linear Units>논문에 나오는 초기화를 이용했다. 이 방식은 각 층이 입력을 직접 다음 층으로 전달하도록 모든 필터를 설정한다. 이 방식은 backpropagation이 잘 되지 않을 수 있다는 우려가 있지만 실험 결과 그렇지 않았다.
Large는 깊어질 수록 feature map의 수가 더 많아지는 형태로 위의 표에 요약되어있다. ci와 ci+1가 연속된 두 feature의 수라고 하고 C는 ci+1와 ci+1를 나눈다고 가정한다. 이 경우 초기화는
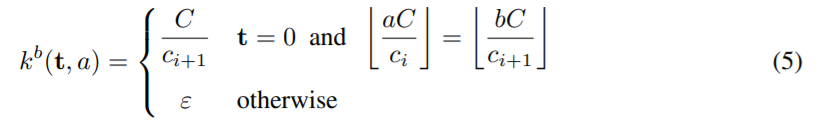
여기서 ε∼N(0,σ2) 이고 σ«C/ci+1다.
Front End
컬러 이미지를 입력으로 하고 C = 21인 feature map을 출력으로 하는 front-end prediction 모듈을 구현하고 학습했다. FCN과 DeepLab의 작업을 따르지만 별개로 구현되었다. VGG-16을 dense prediction에 적용했고 마지막 두개의 pooling과 striding레이어를 제거하고 다음의 모든 레이어는 2 factor만큼 dilated 되었다. 따라서 마지막 레이어는 convolutions고 4 factor만큼 dilated 된다. padding 된 이미지를 입력으로 하고 64×64 feature map을 생성한다.
단순화 된 예측 모듈은 Pascal VOC 2012 학습set으로 학습되었고 VOC-2012 validation set은 사용하지 않았다. 학습은 SGD를 이용하고 mini-batch size는 14, learning-rate은 10-3이고 momentum은 0.9로 60K iteration 학습되었다.
FCN-8s와 DeepLab 과 비교하면 다음과 같다.

front-end모듈은 간단하고 더 정확하다.
Experiments
Caffe library를 이용하고 다른 방법들과 공정한 비교를 하기 위해 구조는 동일하지만 이미지를 조금 더 이용하여 학습시켰다. Micfosoft COCO를 이용하여 VOC-2012에 없는 분류는 background로 간주하였다. 두 모듈은 2 stage로 학습된다. 먼저 VOC-2012이미지와 Micfosoft COCO를 이용하고, SGD, mini-batch size 14, momentum 0.9, 100K iterations의 경우 10-3learning rate로 /40K iterations의 경우 10-4로 학습한다. 두번째 stage는 PASCAL VOC-2012의 이미지만 이용해서 fine-tuning을 하고 SGD, momentum 0.9, 50K iteration, 10-5learning rate으로 학습했다. PASCAL VOC-2012 validation set은 학습에 사용하지 않았고 학습한 모델을 validation set으로 69.8%의 mIoU를, test set으로 71.3% mIoU를 얻었다.( front-end 모듈만 이용한 결과!)

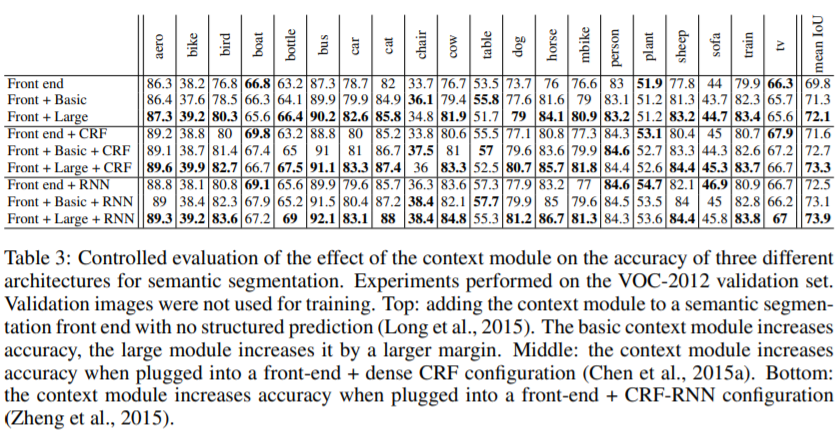
- context module을 이용한 결과
- Front end, Front end + CRF, Front end + RNN은 각각 FCN, DeepLab V1, CRF-RNN에 front-end module을 적용한 네트워크들을 의미
- context module을 이용하면 성능 향상됨. (basic보다 large의 성능이 조금 더 좋음)
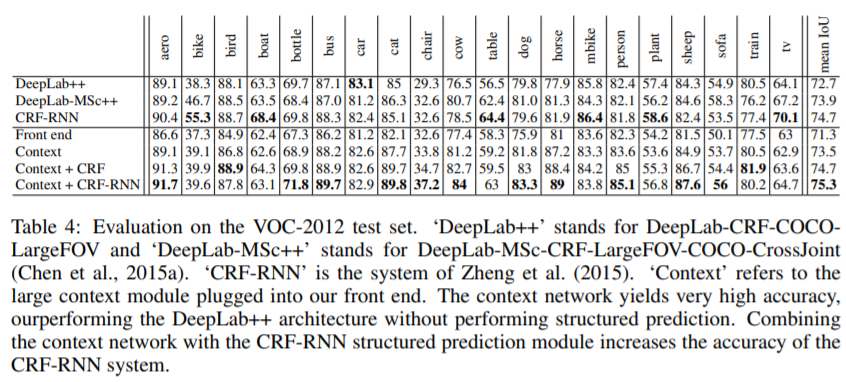
- front-end에 large context module을 추가한 것이 DeepLab-CRF-COCO-LargeFOV 보다 성능이 좋음
- Context에 CRF-RNN을 추가한 네트워크에서 성능이 가장 좋았음

Conclusion
resolution 손실 없이 receptive field를 확장할 수 있으므로 dilated convolution이 dense predition에 적절하다. context module을 기존의 semantic segmentation 시스템에 이용해 정확도를 높일 수 있고 연구의 일환으로 기존의 convolutional network들이 이미지 분류를 위해 발전된 요소를 제거했을 때 성능이 더 올라감을 보였다. (단순화된 모델 front-end가 FCN, DeepLab보다 성능이 더 좋았음.)
그리고 FCN, DeepLab등의 방법론을 언급할 때 간단한 설명과 단어로 하지 않고, 하이퍼링크를 연결하는 방식으로 쓰여있는데 논문 전체의 내용을 의미하고 싶어 이렇게 표현했는지는 몰라도 계속 반복되니 가독성이 떨어지는 것 같다. 차라리 related work로 정리하고 사용했으면 좋았을 것 같다.
흠…
몇 가지 질문 드리겠습니다.
1. Dilated Convolution에서 직접 작성하신 수식의 notation이 뭔지 궁금합니다.
2. Context Module에서 Multi-scale이 어떻게 적용된 건지 이해가 안됩니다.
3. “연구의 일환으로 기존의 CNN들이 이미지 분류를 위해 발전된 요소를 제거 했을 때 성능이 더 올라감을 보였다.” 이 부분에서 발전된 요소가 의미한 바가 뭔가요??
++
리뷰를 보니 근간이 되는 논문 위주로 리뷰를 하시는 것 같아요.
유튜브에 있는 PR-12에도 기초가 되는 논문이 많으니깐 참고해서 리뷰 작성해보면 큰 도움 될 겁니다.