이번에 리뷰할 논문은, 저해상도 이미지를 고해상도로 복원시키는 Super-Resolution (SR) 문제를 다룬 논문입니다. 본 논문에서는 기존 방법들과 다르게 SR에 처음으로 CNN을 적용하여 single image super-resolution을 해결하도록 SRCNN(Super-Resolution Convolutional Neural Network) 을 제안합니다. 특히, 본 논문 이후로 SR 문제에 등장하는 방법론들은 대부분 딥러닝이 적용된다는 것을 통해 본 논문의 의의를 확인할 수 있을 것 같습니다.
Introduction
Single image Super-Resolution (SR)은 저해상도 이미지에 대해 SR 결과로 mapping 될 수 있는 고해상도 이미지가 다양하기 때문에, 여러 solution이 존재하는 ill-posed problem 이라고 한다.
따라서 기존에는 external example-based method 와 sparse-coding based method 를 통해 SR 문제를 해결하였다.
- External Example-Based Method: 동일 이미지의 내부 유사성을 이용하거나, external low-high image 간 pair를 mapping하는 함수를 학습하는 방식
- Sparse-Coding Based Method: External Example-Based Method의 일종으로 가장 자주 쓰이는 방식이다. 저해상도 이미지에 대해 overlapping된 patch들은 crop 후 pre-processing(ex. normalization)을 거치고 나서, 각 patch는 저해상도 dictionary를 통해 encoded 된다. 그리고 다시 고해상도 patch로 복원하기 위해, sparse coefficient를 고해상도 dictionary에 통과시키고 이를 종합함으로써 최종 결과를 얻는 방식
그러나 기존 방법들은 사전학습 혹은 mapping dictionary 구축 등에 초점을 맞추어 최적화를 진행할 뿐, Unified Optimization Framework를 고려하지 않는다.
본 논문에서는 SRCNN(Super-Resolution Convolutional Neural Network)이라는 Low-resolution images로부터 High-resolution images로 직접 end-to-end mapping하는 방법을 학습하는 convolutional neural network를 제안한다.
기존 방법들과 다르게, SRCNN은 patch space modeling을 위한 manifold를 비롯하여 dictionary 학습을 explicitly 진행하지 않고, hidden layer를 통해 implicitly 동작한다. 또한 patch 추출과 통합이 convolution layer에 의해 계산되므로 최적화가 자연히 진행된다.
SRCNN의 Contribution 은 다음과 같다.
- SR을 위한 fully convolutional neural network을 제시한다.
- 딥러닝 기반 SR 방법과 기존의 희소 코딩 기반 SR 방법 사이의 관계를 설정했다.
- 딥러닝은 SR 문제에 유용하며, 좋은 품질과 속도를 달성할 수 있음을 보였다.
Convolutional Neural Networks For Super-Resolution
Formulation (내용 보충하기)
먼저, Low resolution input image에 대해 bicubic interpolation을 적용하여 input image Y를 만든다. 그리고 Y에 대하여 GT인 high-resolution image X와 유사한 F(Y)를 찾아야 한다. (이 때, X와 Y의 크기가 같더라도, 용이한 표현을 위해 Y를 low-resolution이라고 하자) 여기서 low-resolution Y에 대한 mapping인 F를 찾는 방법은 3단계로 구성된다.
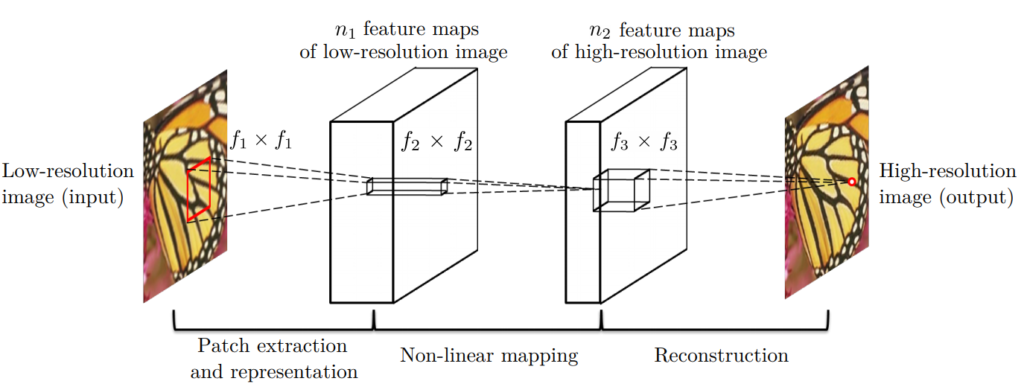
- Patch extraction and representation: 각 patch에 대한 n1 차원 feature map을 추출
이미지 복원에서 흔히 사용되는 방법은 patch를 조밀하게 추출한 후, PCA, DCT, Haar 등과 같은 사전 훈련된 based 세트로 표현하는 것이다. 즉, low-resolution image Y로부터 patch를 추출하고, 각 patch 에 대해서 CNN을 통과 시켜 feature map을 생성한다. 이후, n1 차원의 feature map에 ReLU 함수를 적용한다.
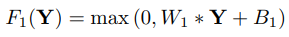
- Non-linear mapping: 다차원 low-resolution patch vector를 다른 high-resolution patch vector로 mapping
첫 번째 계층은 각 패치에 대해 n1 차원 특징을 추출합니다.high-dimensional vector끼리 nonlinearly mapping 시킨다. 이 때, 1 X 1 convolutional layer를 사용하고, 각각의 mapped vector는 high resolution patch를 표현한다. 이번 단계에서도 마찬가지로 activation function으로 ReLu를 사용하는데, 이 때, nonlinearity를 증가시키고 싶다면 conv layer 수를 증가시키면 된다.
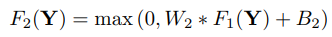
- Reconstruction: 다차원 patch들로부터 final high resolution image로 복원시킨다.
high resolution patches로부터 최종적으로 high resolution image를 만들어낸다.
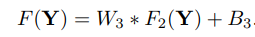
정리하면, 아래 그림과 같이 각각의 단계는 Convolution Layer로 구성된다. 첫 번째 layer에서는 저해상도 이미지로부터 feature를 추출하고, 두 번째 layer에서는 고차원의 vector들을 feature mapping을 하며, 마지막 layer에서 feature로부터 나온 결과를 image로 복원한다.

Training
Mean Squared Error (MSE)를 loss function으로 사용한다.
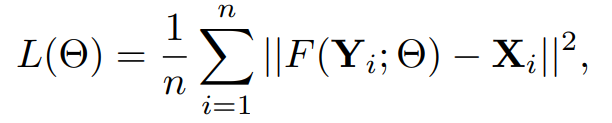
그리고 evaluation metric으로 는PSNR을 사용한다. MSE가 작아질 수록 PSNR은 커진다.
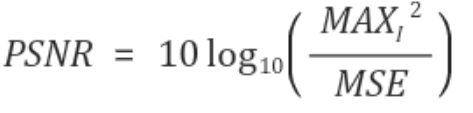
Experiments
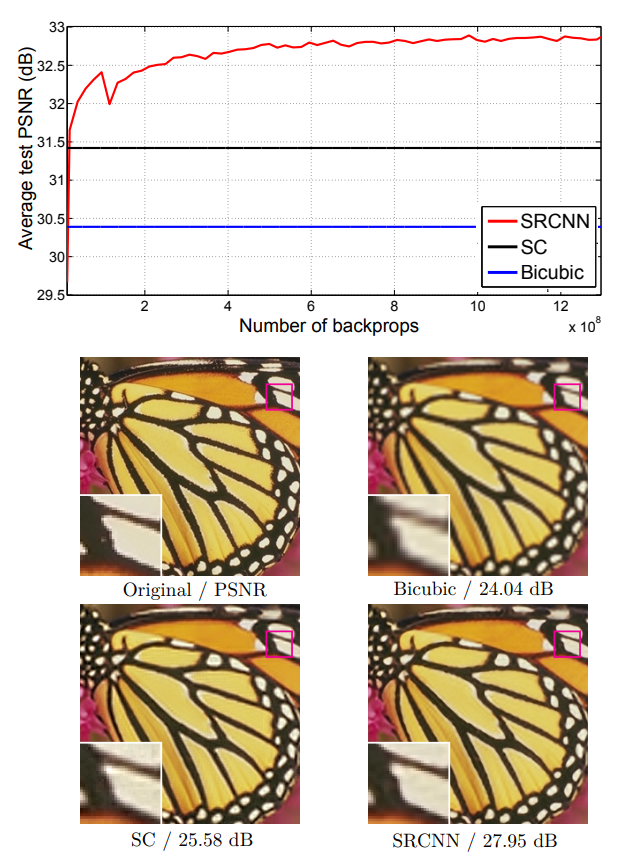
위 그래프는 Original, Bicubic, Sparse-coding-based method(SC), SRCNN에 대한 PSNR을 나타낸 그래프이다. 그래프에서 확인할 수 있듯, SRCNN의 PSNR이 가장 높다.
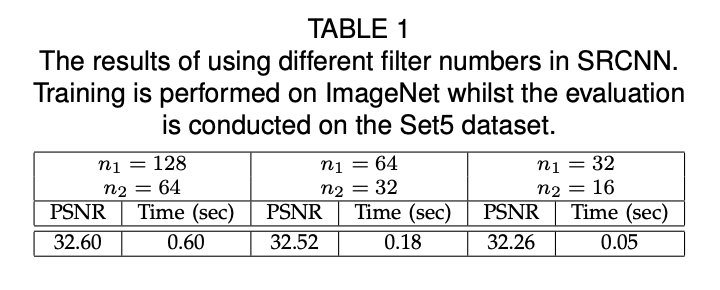
TABLE1은 fiter 수에 따른 결과로 filter의 수가 증가하면, PSNR이 증가하여 화질 개선은 더 잘 이루어지지만, 학습 시간이 증가한다.
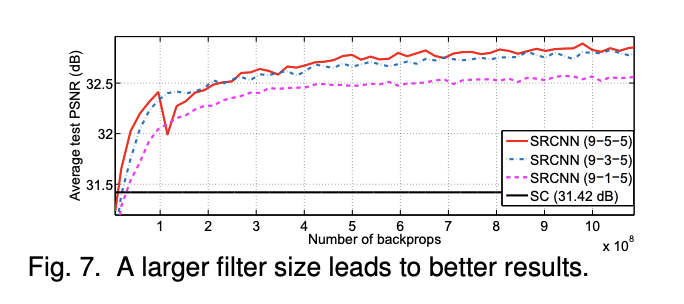
Figure 7은 filter size에 따른 결과로, filter의 크기가 커지는 것과 비례하여 PSNR의 평균이 높아지므로 화질이 향상됨을 확인할 수 있다.