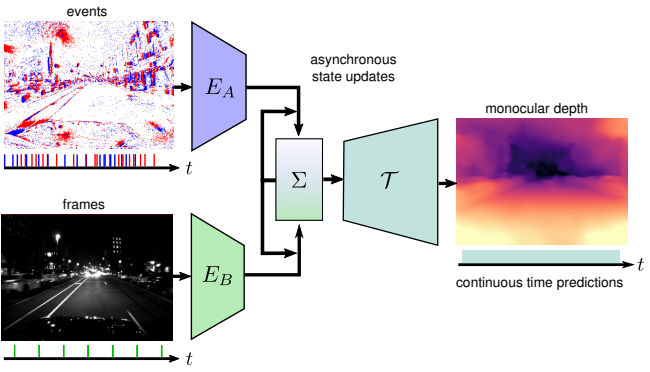
이벤트 카메라란 픽셀 당 밝기 변화(이벤트)를 촬영하는 새로운 비전 센서이다. 이 센서는 높은 시간적 정보와 동적 범위, 모션 블러가 없음 과 같은 장점을 제공한다. 하지만 이 센서는 시각적인 신호의 구성 요소만을 측정하므로 비전의 텍스트 정보를 담는데 문제가 있다. 반면에 기존 칼라 카메라의 경우 동일한 순간의 풍부한 시각 정보를 측정하는데 이점이 있다. 이 내용들을 요약하면 그림 1처럼 이벤트 카메라는 이벤트가 생성되는 순간을 담으니 촬영되는 순간이 일정하지 않고 또한 텍스트정보가 없다는 단점이 있지만 각 정보(이벤트)의 활용범위가 무궁무진하다는 장점이 있다. 그리고 기존 카메라는 일정하게 풍부한 텍스트 정보가 있어서 두 센서가 상호 보완관계에 놓여있다고 한다. 따라서 이 두카메라를 동시에 사용하는게 중요한 이슈로 남이있다.
하지만 이벤트카메라의 단점에서 말했다 싶히 이벤트카메라와 칼라 카메라는 동시에 촬영 되지 않아서 같이 사용하는데 문제가 있다고 한다. 동시에 촬영되지 않았기 때문에 기존의 RNN 베이스의 방법론을 적용해서 두개의 센서를 융합할 수 가 없다고 한다. 이러한 단점을 보완하기 위해서 이 논문에서는 RAM 이라는 Sync가 맞지 않은 두 데이터에 대해 융합하여 원하는 정보를 얻을 수 있는 방법론은 제시했다. RAM 은 RNN을 베이스로 하며 RNN의 hidden state가 asynchronously 한 상황을 학습하여 언제든지 Predict을 할 수 있도록 한다고 한다. 이 논문에서는 이 방법론을 Monodepth Estimation에 적용해서 두 센서의 융합이 얼마나 잘 됐는지를 평가하였다.
Method
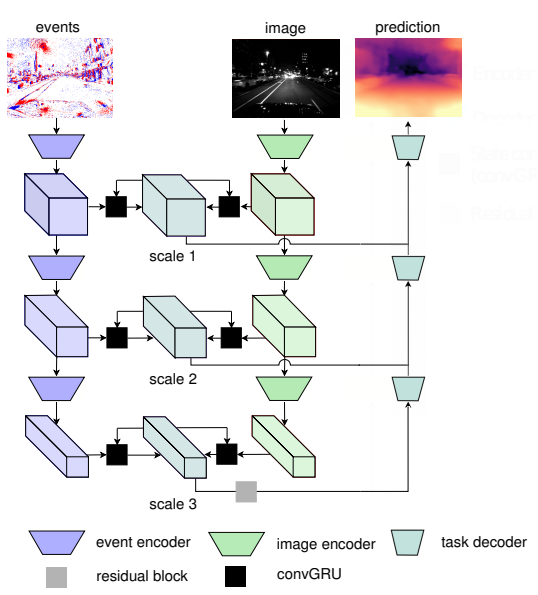
A . Recurrent Asynchronous Multimodal Networks
제안된 RAM은 그림 2와 같다. 그림과 같이 여러스케일 에서 중간 feature를 고려한다. 이때 입력으로 들어오는 데이터는 다음을 따른다. (1) 비동기 데이터를 가정하므로 두 데이터의 sync는 맞지 않을 수 있다. (2) 또한 각 센서가 들어오는 시간에 폭도 일정하지 않다. 이 두개를 지킴으로써 이 논문에서 원하는 이벤트카메라와 칼라카메라의 융합에 맞는 실험 설정이 되었다. Sync가 맞지 않는 두 데이터를 융합하기 위해서 이 논문에서는 GRU를 사용한다. 이 unit은 RNN 계열의 방법론으로 이전 데이터 정보를 활용해 예측을 할 수 있도록 도와준다.
B. training
학습을 하기 위한 Depth gt는 Lidar로 촬영한 sparse data 를 사용했다. sparse data와 생성된 영상을 비교하기 위한 Loss가 정의 되는데 요기서 이제 이해가 안가는 부분이 발생한다. 먼저 scale invariant loss인데 식은 다음과 같다.
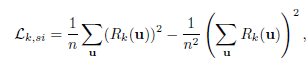
요기서 이 Rk가 무엇인지에 대한 설명이 없다. 따라서 이게 어떻게 scale invariant 하다는지 이해할 수 가 없다 다음 로스도 유사한 문제가 있는데 식은 다음과 같다 .
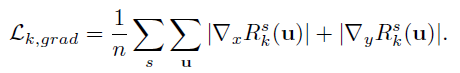
이 로스는 Depth가 불연속성을 띄는 것을 막으려고 한 것 같은데 Rk에 대한 설명이 없어서 정확히 무엇인지 알수 없다.
Result
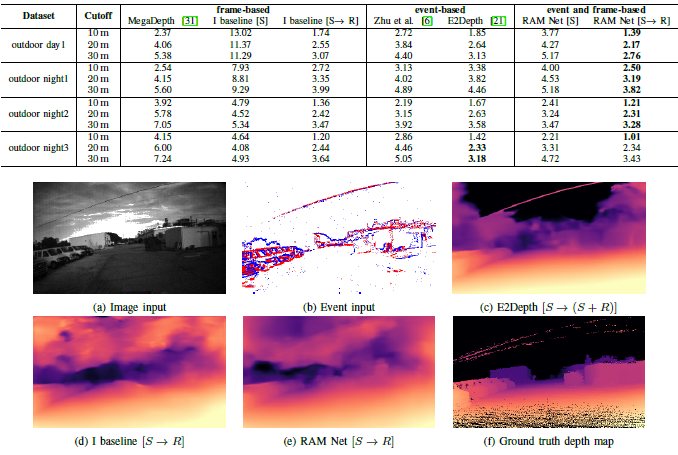
정량적 결과를 보면 이벤트와 frame을 전부 사용한 것이 가장 성능이 좋은 것을 확인 할 수 있다. 하지만 정성적 결과를 보면 딱히 이게 좋다고 말할수 있을까 싶은데 이것에 대한 고찰은 세미나을 통해 하도록 하겠다.