
이번에 리뷰로 작성할 논문은 generator와 discriminator를 모두 transformer 구조로 만들어 영상을 생성하는 GAN 방법론입니다.
Introduction
일단 Generative adversarial networks(GANs)은 매우 많은 발전을 이루어왔습니다. 말을 얼룩말로 바꾼다던지, 두 사람의 얼굴 특성을 적절히 섞어서 새로운 인물의 얼굴도 만드는 Image Translation과 풍경 사진 속 산을 지워버리고 도로를 만드는 image editing 분야 등 정말 다양하게 사용됩니다.
하지만 이러한 GANs은 학습하는 과정이 불안정하다는 단점이 존재하여, 안정한 학습을 진행하기 위해 regularization term을 둔다던지, loss 함수를 새로 설계하기도 합니다. 또는 다른 비전 분야들처럼 GANs 역시 backbone을 더 좋게 설계하면 더 좋은 결과를 생성해낼 수 있습니다.
그러나 이러한 backbone은 항상 CNN을 기반으로 설계되는 것이 당연한 상식이 되버렸으며 2014년 처음 나온 original GAN이 fc network를 사용한 것 이후로는 CNN이 아닌 다른 방식으로의 backbone을 가진 방법론이 존재하지 않았습니다.
비록 CNN 기반 방법론들이 vision domain에서는 좋은 성능을 보이는 것은 맞지만, 저자는 convolution을 전혀 사용하지 않으면서 매우 강인하게 작동하는 GAN을 만들수는 없을까? 라는 의문을 가집니다.
왜냐하면 CNN이 좋은 성능을 보이는 것은 맞지만, 단점도 명확하게 존재하기 때문이죠. 사실 Transformer를 vision 분야에 접목하는 모든 논문들이 말하는 공통적인 단점이기도 한데, 바로 CNN은 지역적인 receptive filed를 가지고 있기 때문에, 충분한 깊이의 layer를 태우지 않는 이상은 넓은 범위에서의 연관성을 처리하기 힘들다고 합니다.
그럼 충분한 깊이의 layer를 태우면 되겠네? 라고 생각하실 수 있으시겠지만, 레이어가 깊어질수록 feature map의 해상도는 점점 작아지며, 그로 인해 fine detail들을 잃어버리게 됩니다.
즉 일반적인 CNN 기반의 모델들은 그러므로 입력 영상의 글로벌한 통계치들을 포착하는데는 적합하지 못하며, 이를 해결하기 위해 self-attention과 non-local operation을 하는 방법론들이 제안되기도 했었습니다.
그래서 해당 논문에서는 요새 아주 핫한 Transformer architecture이 CNN을 대체할 수 있지 않을까 라는 생각을 하게 됩니다. Transformer 구조의 장점은 크게 두가지입니다.
하나는 매우 강력한 표현 능력을 지니고 있으며, 사람이 정의한 귀납적 편향치(inductive bias)에서 자유롭다는 점입니다. 사실 귀납적 편향치라는 것이 무엇인지는 잘 모르겠지만, 논문에서 나타는 설명을 덧붙이자면 CNN은 feature map의 모든 위치에서 필터 가중치를 공유하기 때문에 지역 불변적이며 feature locality를 향해 강하게 편향되어 있다고 합니다.
둘째로는 transformer 구조가 매우 일반적이며, 컨셉적으로 간단하고 다양한 도메인과 테스크에서 강인하게 작동하는 잠재력을 가지고 있습니다.
그래서 해당 논문에서는 CNN을 전혀 사용하지 않은 체, 순수하게 Transformer만을 사용하여 영상을 생성하려고 합니다. 사실 해당 논문 이전에도 GAN에 transformer architecture를 적용한 방법론들이 이미 존재하지만, 해당 방법론들은 오직 transformer encoder block을 CNN-based generative model에 접목하여 사용하는 등 완전히 CNN에서 벗어나지 못하였다고 합니다.
사실 Transformer를 적용하기에는 많은 어려움이 존재합니다. 먼저 지금까지 컴퓨티비전 분야에서 CNN을 사용하지 않고 순수하게 Transformer를 사용한 방법론들은 모두 분류나 검출과 같이 무언가를 구분하는 분야들이었습니다.
이러한 분야들은 영상의 패치들을 일렬로 나열하여 모델의 입력으로 사용하였지만, 이 논문의 목표인 이미지 생성 분야에서는 구조, 색, 질감 등 spatial coherency가 매우 높게 요구 되므로 앞서 제안된 분류나 검출 방법론을 그대로 사용한다고 해서 좋은 성능을 보인다는 확신이 없습니다.
또한 기존의 잘 설계된 CNN 기반 GANS도 학습 과정이 불안정하였기에 transformer에서도 불안정할 가능성이 높으며, visual transformer는 학습 과정에서 매우 많은 데이터가 필요하다는 점을 미루어보아, 학습 과정이 만만치 않다고 볼 수 있습니다.
contribution
위에서 말한 어려운 점들을 최대한 해결함으로써, 해당 논문에서는 세가지 contribution을 말합니다.
- Model Architecture : 처음으로 CNN을 사용하지 않은 pure transformer 구조의 GAN을 제안함. pixel level의 입력을 계속해서 transformer encoder에 넣게 되면, 메모리가 과도하게 소모되는 현상이 발생하는데 이를 획기적으로 처리하는 방법론을 제안함.
- Training Technique : 많은 양의 학습 데이터가 필요한 transformer를 위해 data augmentation, multi-task co-training, localized initialization 등 다양한 학습 테크닉을 적용함.
- 이를 통해 CNN 기반의 방법론들과 비교하였을 때 더 성능이 좋거나, 경쟁할만한 수준의 성능을 보임.
Vanilla Architecture Design for TransGAN
자 그러면 본격적으로 모델의 구조에 대해서 알아봅시다. 일단 GAN은 크게 Generator(G)와 Discriminator(D)로 나누어져 있습니다. 일단 NLP에서 제일 처음 사용된 original transformer encoder를 G와 D의 basic block으로 가져왔으며 약간의 수정을 거쳐 사용했다고 합니다.
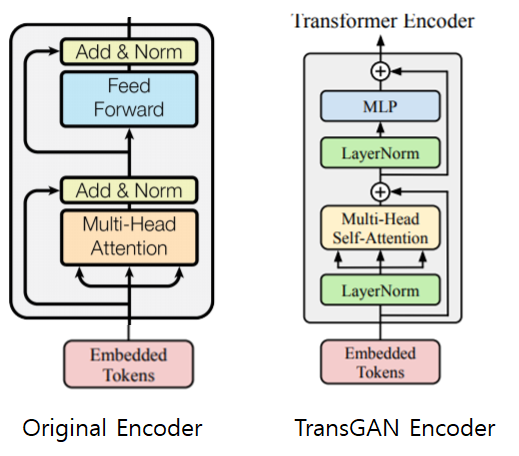
그림 1의 왼쪽이 original transformer encoder이며, 우측이 TransGAN에서 사용한 transformer encoder block의 구조입니다. residual 기법, multi-head attention, feed forward layer를 모두 사용하며 다른 차이점은 그저 normalization을 attention layer와 feed forward layer 전에 하느냐, 후에 하느냐 차이입니다.
Memory-Friendly Generator
NLP에서 사용된 transformer는 encoder block을 6개의 stack으로 쌓아서 각각의 단어 임베딩 토큰을 모델의 입력으로 사용하였습니다. 하지만 해당 논문의 목표인 image generation 분야에서는 영상의 pixel by pixel 특성으로 transformer의 입력을 사용해야 합니다.
그렇다면 stack transformer encoder에 저해상도 영상(e.g. 32\times32)을 flatten 하여 1024 크기의 1D 벡터를 입력으로 사용할 수 있겠지만, 생성하고자 하는 영상의 크기가 늘어나면 늘어날수록 입력 sequence의 길이가 4배씩 늘어나게 됩니다.(e.g. 64/times64 = 4096)
즉 생성하고자 하는 영상의 해상도가 커질수록 매우 크게 늘어나는 연산량을 줄이고자, multiple stages을 통과하면서 점진적으로 해상도를 늘려나가는 기법을 사용했다고 합니다.
조금 더 자세히 말하면, transformer encoder block을 통과할 때마다 생성되는 영상의 해상도가 두배씩 커지는 것(2×H, 2×W)이며, 이때 임베딩 차원은 4배로 줄임으로써(C/4) 처음과 최종 feature의 전체 크기를 같게끔 하는 것입니다.
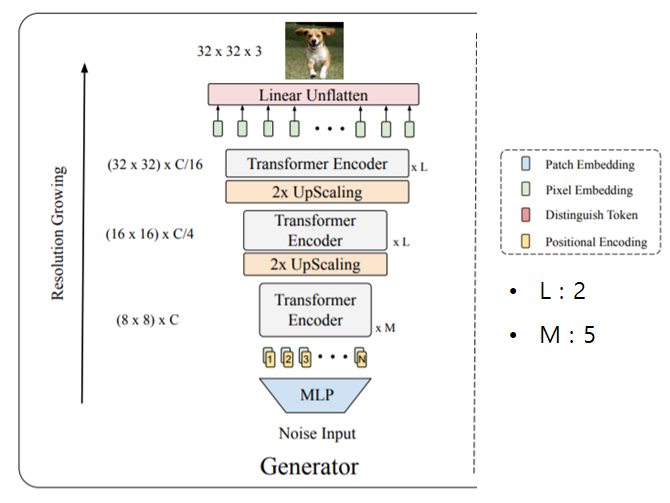
Here H = W = 8 and H_{T} = W_{T} = 32
그림2가 바로 generator의 구조입니다. 가장 먼저 noise input을 MLP에 태워서 H×W×C 길이의 1D 벡터를 생성합니다. 그 벡터는 H×W 해상도의 feature map(default H=W=8)으로 reshape이 되며 C차원으로 임베딩 됩니다. (shape이 (H,W,C)인 Tensor)
그 후 H×W 길이의 토큰들로 변환하여 (H×W)×C의 행렬로 만든 후 학습가능한 positional encoding을 결합하여 첫번째 Transformer Encoder bundle에 입력으로 사용합니다. 첫번째 bundle은 총 5개의 transformer encoder block으로 구성되어있습니다.(M=5)
그 후 두번째 Transformer Encoder bundle(encoder block이 2개)의 입력으로 들어가기 전에 up-sampling module을 통과합니다. 그 up-sampling module은 1D sequence token을 다시 2D feature map으로 reshape 해준 다음에 pixelshuffle module을 적용함으로써 해당 feature map의 resolution은 2배로 키우며 임베딩 차원은 4배로 down sample 합니다.
즉 feature map의 H와 W가 2배로 늘어나며 대신 C는 4배 줄어들어 결국 tensor의 총 크기는 up-sampling 이전과 동일하게 해지는 것이죠.(2H×2W×C/4 = H×W×C) 그 후에 feature map을 1D sequence인 임베딩 토큰으로 만들어준 다음 두번째 transformer bundle의 입력으로 들어가게 합니다.
이러한 trade-off up-sampling 기법은 과도한 메모리 및 연산 과정을 완화시켜줍니다. 결론적으로, 최종 출력의 resolution이 지정해준 Target resolution(H_{T}, W_{T})에 도달할 때까지 반복해서 처리됩니다.
Target resolution에 도달하였다면, 그 다음엔 임베딩 차원을 3으로 투영하여 RGB 영상을 취득합니다.
Tokenized-Input for Discriminator
픽셀 레벨에서의 추론을 해야하는 Generator와 달리, Discriminator는 그저 영상이 진짜인지 가짜인지 판단하는 분류문제를 풀어나갑니다. 즉 영상의 coarser patch level을 의미있는 토큰으로 볼 수 있으며 그러므로 영상을 patch 단위로 쪼개어 D의 입력으로 사용할 수 있다는 것이죠.
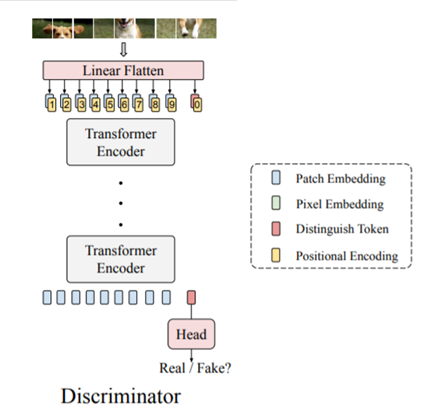
그림 3은 CNN을 사용하지 않고 순수히 transformer만으로 구성된 Discriminator의 구조를 나타냅니다.
먼저 입력 영상을 8×8 패치 단위로 쪼개며, linear flatten layer를 통과함으로써 쪼개진 각 패치들을 1D sequence인 토큰 임베딩으로 변환시킵니다. 여기서 토큰의 길이 N = 8×8 = 64 이며 차원은 C입니다.
그 후에 학습 가능한 positional encoding을 추가하고, 1D sequence의 맨 앞에 {cls} token을 추가합니다. 해당 {cls} 토큰은 transformer encoder들을 통과한 후에 최종적으로 영상이 real인지 fake인지를 구분하기 위한 출력으로 사용되게 됩니다.
Evaluation of Transformer-based GAN
지금까지 TransGAN의 구조에 대해서 알아보았습니다. 이제는 transformer로 구성된 GAN과 CNN 기반의 GAN의 성능 차이를 확인해봐야겠죠?
일단 GAN은 G와 D로 구성되어 있으므로, 해당 논문에서는 다음과 같이 G or D만 Transformer이거나 G and D 모두 Transformer일 때의 성능 차이가 얼마나 나는지를 먼저 실험합니다.
- AutoGAN G + AutoGAN D (i.e. original AutoGAN)
- Transformer G + AutoGAN D
- AutoGAN G + Transformer D
- Transformer G + Transformer D (i.e. vanilla TransGAN)
해당 실험에서 사용된 데이터 셋은 CIFAR-10이며, 평가 지표로는 Inception Score(IS)와 FID 입니다.
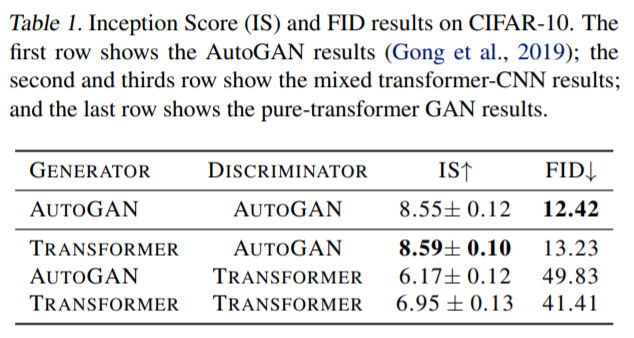
결과는 표1에서 확인가능한데, 해당 결과에 대한 설명은 크게 2가지로 나타납니다.
- Transformer based Generator는 CNN based Generator와 충분히 경쟁력 있는 성능을 보여줌.
- 반면, Transformer based Discriminator는 CNN based Discriminator와 비교하였을 때 매우 형편없는 성능을 보임. Generator를 CNN에서 transformer로 바꾸면 성능이 조금 향상하기는 하지만 해당 성능도 역시 기존 CNN based GAN에 비하면 크게 떨어짐.
비록 G를 Transformer, D를 CNN으로 사용하는 경우는 저자가 원하는 CNN을 전혀 사용하지 않는 pure transformer GAN은 아니지만, 실제 inference에서는 Discriminator를 사용하지 않으므로 어찌보면 pure transformer GAN으로 볼 수도 있습니다.
하지만 논문에서는 D마저 transformer를 사용하는 완전한 pure transformer GAN을 설계하고자 새로운 실험을 진행합니다.
Data Augmentation is Crucial for TransGAN
일단 Discriminator를 transformer로 사용하게 될 경우 성능이 드랍되는 현상에 대해서 저자는 transformer based classifier의 data hungry 특성을 문제점으로 지적합니다. 앞에 introduction에서도 설명드렸지만, transformer 기반의 분류기들은 매우 방대한 양의 데이터로 사전학습되어야만 CNN을 능가하는 성능을 보이게 됩니다.
하지만 방대한 양의 데이터가 없다 하더라도, data augmentation을 이용하면 data hungry 문제를 어느정도 해결할 수는 있습니다. 하지만 일반적으로 기존 CNN based GAN의 경우에는 이러한 data augmentation을 추가하게 될 경우 오히려 모델이 학습하는데 어려움을 겪었습니다.
그래서 저자는 과연 data augmentation이 CNN-based GAN과 Transformer based GAN에 어떠한 영향을 미치는지 파악하기 위하여 각 시대별로 SOTA에 해당되었던 CNN-based GANs과 TransGAN에 Data augmentation을 적용하여 생성 성능을 비교하였습니다.
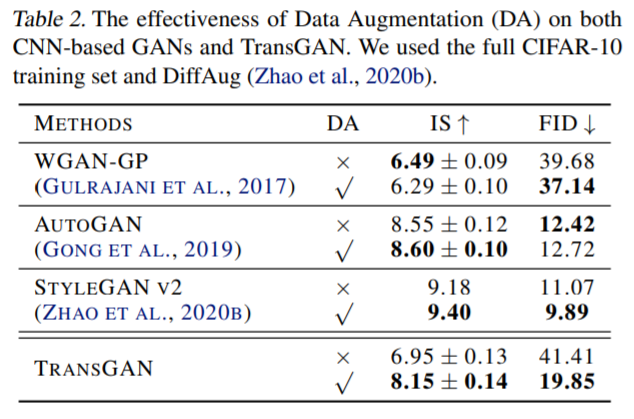
표2는 data augmentation(DA)를 적용여부에 따른 각 방법론들의 성능을 나타낸 것입니다. 보시면 StyleGAN v2의 경우에만 data augmentation을 하였을 때 IS와 FID 모두 성능이 향상된 것을 확인할 수 있으며, 그 외에 AutoGAN과 WGAN은 metric에 따라 성능이 증가하거나 감소하는 현상을 보입니다.
하지만 TransGAN의 경우 DA를 적용하면 성능이 IS와 FID 모두 매우 크게 향상되는 것을 확인할 수 있습니다. 이르 ㄹ통해 transformer-based architectures는 CNN보다 더 많은 데이터가 필요한 이른바 data-hungry가 심하다는 것을 다시 한번 확인할 수 있었습니다.
Co-Training with Self-Supervised Auxiliary Task
이번에는 추가적인 self-supervised task를 진행함으로써 TransGAN의 성능이 향상되는지를 실험으로 보입니다. 사실 이전에 CNN based GAN 역시도 추가적인 self-supervised task(e.g. rotation prediction)을 통해 GAN의 학습 과정을 안정화시키는 방법론이 있었습니다.
아무튼 해당 논문에서는 보조 task로 super resolution을 수행했다고 합니다.
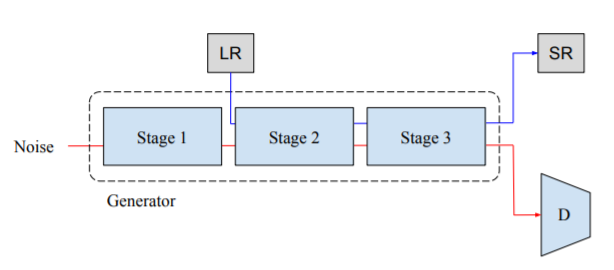
그림 4를 살펴보시면, Generator를 학습시킬 때 2번째 transformer encoder bundle의 입력으로 low resolution image를 넣습니다. 그 후, generator의 최종 출력 영상이 Discriminator의 입력으로 사용될 뿐만 아니라, 동시에 실제 real image인 high resolution과 비교하여 auxiliary loss를 계산하게 됩니다. 해당 loss는 MSE loss를 사용합니다.
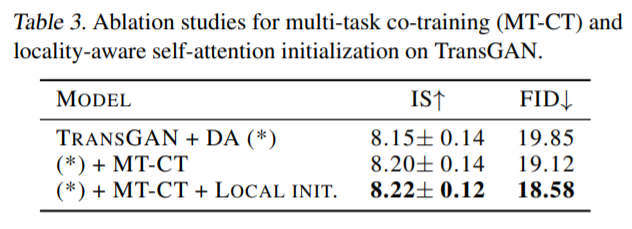
Co-Training을 진행하였을 경우( (*) + MT-CT) 성능이 기존대비 조금 더 향상되는 것을 표 3에서 확인 가능합니다.
Locality-Aware initialization for Self-Attention
마지막으로 해당 논문에서는 locality aware initialization for self-attention 기법을 제안합니다. 해당 학습 전략은 그림 5를 통해 확인 가능합니다.
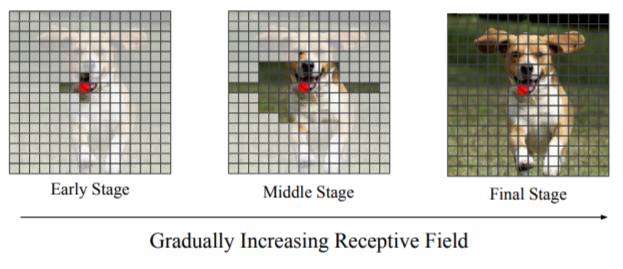
그림 5를 살펴보시면, 영상에 투명한 블럭(실제 영상)과 회색 블럭이 존재하는 것을 보실 수 있습니다. 붉은 점은 query의 위치를 의미하며, 해당 query는 회색블럭이 아닌 투명 블럭끼리만 상호작용할 수 있습니다. 즉 회색 블럭은 일종의 mask 처리를 통해 self attention시 적용이 안되는 부분을 의미하며, Stage가 점차 진행될수록 더 넓은 영역들이 query와 self attention 연산을 수행할 수 있습니다.
이러한 방식을 통해 마치 CNN처럼 low level에서 지역적으로 볼 수 있게 만들며, high level로 갈수록 기존 transformer의 장점인 flexibility를 가져올 수 있다고 합니다. 논문에서는 이러한 방식을 적용하면 앞단에서는 모델이 이웃지역(necessary details)들을 우선시하게 되며 final stage로 갈수록 점차 광범위한 영역을 보면서 file detail을 보게 된다고 합니다.
아무튼 이러한 locality-aware initalization을 적용하였을 때 정량적 결과는 표 3에 마지막 행에서 확인가능합니다.
Scaling up to Large Models
마지막으로, 모델의 크기에 따른 성능 향상을 평가하기 위해 실험을 또 진행합니다. 모델의 크기를 늘리는 관점은 크게 두가지 입니다.
- Transformer-based Generator의 embedded dimension의 크기를 늘리는 것.
- transformer encoder block의 개수를 늘리는 것.
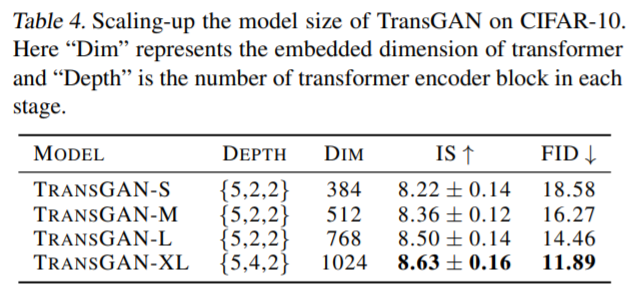
일단 embedded dimension은 쉽게 말해 Generator의 처음 시작이 random noise를 MLP에 태우는 것으로 시작하는데, 이때 MLP를 타고 나온 1D 벡터의 차원 C의 크기를 말하는 것입니다. 실험으로 사용한 차원은 총 384, 512, 768이며 각각의 차원의 크기에 맞추어 TransGAN-S, M, L로 표현하였습니다.
해당 차원을 늘렸던 결과, 당연하게도 성능이 IS와 FID 모두 향상되는 것을 표4를 통해 확인할 수 있습니다.
또한 TransGAN-L에다가 위에서 말한 depth(transformer encoder block의 개수를 늘리기)를 키웠을 경우를 TransGAN-XL로 명시하였으며, 이 결과 제일 좋은 성능을 나타낸 것을 표3에서 확인할 수 있습니다.
Comparison with State-of-the-art GANs
이제 마지막으로, 위에서 설명한 각종 성능 향상 기법들(DA, Co-Training, Local init, scaling-up the model size)을 모두 적용한 후에 CNN 기반 방법론들과 성능 비교를 진행하였습니다.
평가에 사용된 데이터 셋은, CIFAR-10과 STL-10, CelebA dataset이며, 차례대로 32×32, 48×48, 64×64 해상도를 가지는 출력 영상을 생성했다고 합니다.
Results on CIFAR-10
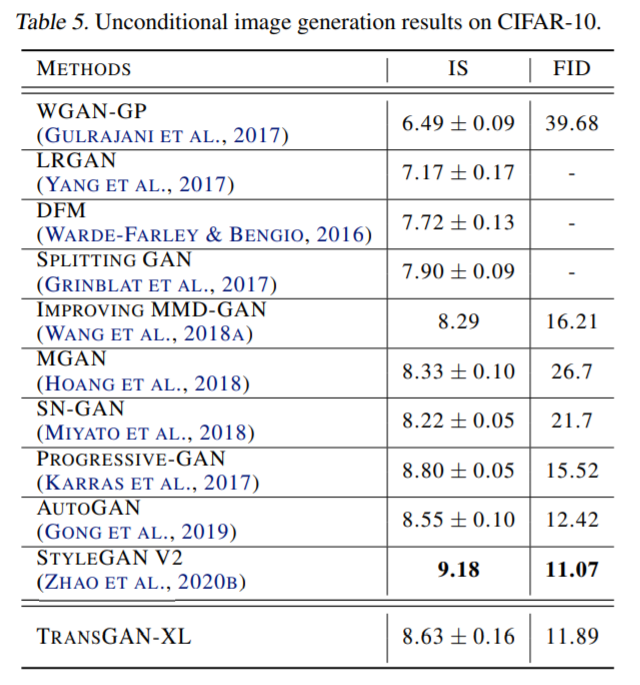
일단 결과를 보면 StyleGAN v2가 제일 좋은 성능을 보이긴 하였지만, TransGAN 역시 다른 CNN based GANs과 비교하면 견줄만한 성능을 보였습니다. 특히 저자는 FID 결과에서 Progressive-GAN을 앞질렀으며, StyleGAN v2와 견줄만하다고 강조하네요.
Results on STL-10
그 다음으로는 STL-10 데이터 셋의 대한 결과입니다.
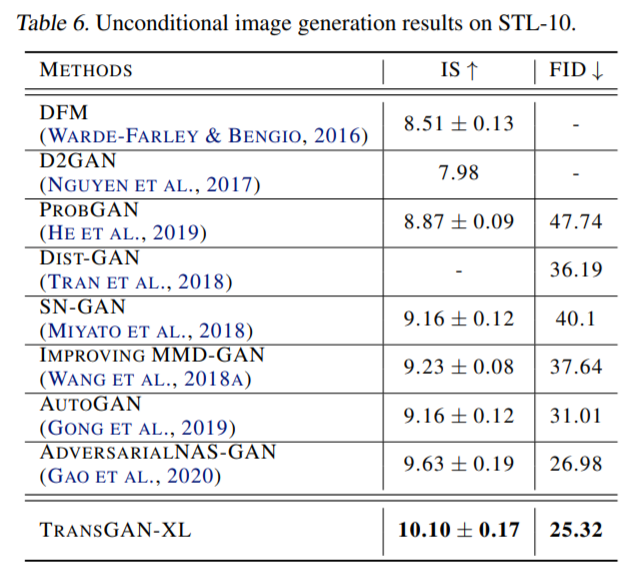
보시면 TransGAN이 CNN-based GAN들을 모두 제치고 SOTA를 달성하게 됩니다. 근데 왜 stylegan v2에 대한 성능을 안보였는지는 잘 모르겠네요...? stylegan v2가 이전 CIFAR-10에서도 제일 좋은 성능을 보였는데, STL-10에서도 좋은 모습을 보였을 것으로 생각되는데 이상하게도 해당 논문에서 보여주지는 않습니다 흠...
아무튼 CIFAR-10에 비해 STL-10은 2배 더 큰 데이터 셋 크기를 지니고 있으며, 이러한 large data가 여타 CNN based GANs과 달리 transformer-based architecture인 TransGAN에게 더 긍정적인 영향을 준 것 같다고 저자는 말합니다.
Generation on Higher Resolution
마지막으로 TransGAN의 고해상도 출력 영상을 평가하기 위하여 CelebA dataset을 사용하였다고 합니다. 근데 이것도 조금 웃긴게 64×64 크기의 출력 영상을 만들고는 고해상도라고 하네요. 아무튼 TransGAN의 정량적 결과는 FID가 12.23으로 2017년에 나온 DCGAN과 비교하였을 때 조금 더 나은 수치를 보입니다.(DCGAN은 12.5 FID score)
결론
일단 CNN을 전혀 사용하지 않은 체, 순수하게 Transformer 만으로 이루어진 GAN이라는 점에서 의미가 깊으며, 다양한 실험을 통해 여러 학습 전략에 따른 transformer based architecture가 어떻게 성능이 향상되는지를 보인 좋은 논문이라고 생각합니다.
하지만 아무래도 초기 연구이다보니, 생성하는 영상의 해상도가 32 또는 64밖에 안된다는 점에서 아직 갈 길이 멀다고 볼 수 있겠네요.
리뷰 잘 봤습니다.
제가 찾은 gan+transformer는 https://arxiv.org/pdf/2103.01209.pdf 이 논문이였는데
비슷한 논문이 또 있었네요 다음엔 이논문….ㅎㅎ
으로 대찬님이 리뷰해주신다는거죠?^^