논문 소개
본 논문은 에서 다루는 contrastive Learning는 self-supervised learning 에서 주로 사용되는 학습 기법으로, 군집 내의 (positive pair)간의 유사도를 높이고, 군집 간의 (negative pair) 유사도를 낮추어 학습하는 기법이다. 이때 대부분의 연구들은 labeled data를 기준으로 augmentation(랜덤 crop, 회전, 색감 변화)등으로 positive pair를 생성하여 학습에 이용한다. 이러한 과정에서 몇몇 연구는 비디오의 앞 뒤 프레임을 촬영각도로 augmentation된 positive pair로 이용한다. 그러나 이 또한 동일한 비디오 내에서 주로 이루어 진다. 본 논문은 동일 비디오가 아니더라도 다른 비디오를 통해 positive pair를 구성하여 higher-level semantics, categorical information을 감지하도록 하는 효과를 기대하고자 한다고 소개한다. 여기서 higher-level이란, 기존의 augmentation(색감, 회전, 사이즈 조정, 촬영각 변화)(예를들어 “부엌의 푸들”이미지는 augmentation 후에도 부엌의 푸들이다.)에서 기대할 수 없는 의미론적인 특징(개를 의미하는 고차원적인 특징)을 의미한다.
related work
Cycle-consistency learning라는 해당 학습법은 3D scene understanding 분야에서 영향을 받았다고 한다. cycle-consistency를 유지하기 위해 forward와 backward를 동시에 진행하는 학습법이라고 하는데. encoder(E)와 decoder(D)가 있을때, y = E(X) 이면 D(y) = X 로 일관성이 유지되어야 한다는 개념이다.
본론
contrastive learning을 진행할때 보통 고려되는것은 “군집 내 유사도”와 “군집 간 유사도”이다. 군집 내부 요소끼리는 유사도가 높아여 하고 군집 간의 유사도는 낮아야 하며 대표적으로는 triplet loss가 있다.
본 논문은 제안하는 학습법을 위해 두가지 Loss를 이용한다 (intra-video loss, cycle loss)
1. Intra video loss
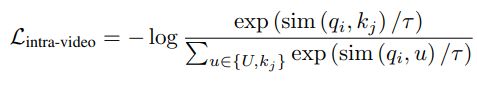
해당 식은 하나의 video의 프레임 Ii, Ij에 대해서 Ii의 feature qi가 Ij와는 유사하고, 다른 비디오의 특징값 u와는 유사도가 낮은 방향으로 학습되도록 한다.
2. cycle loss
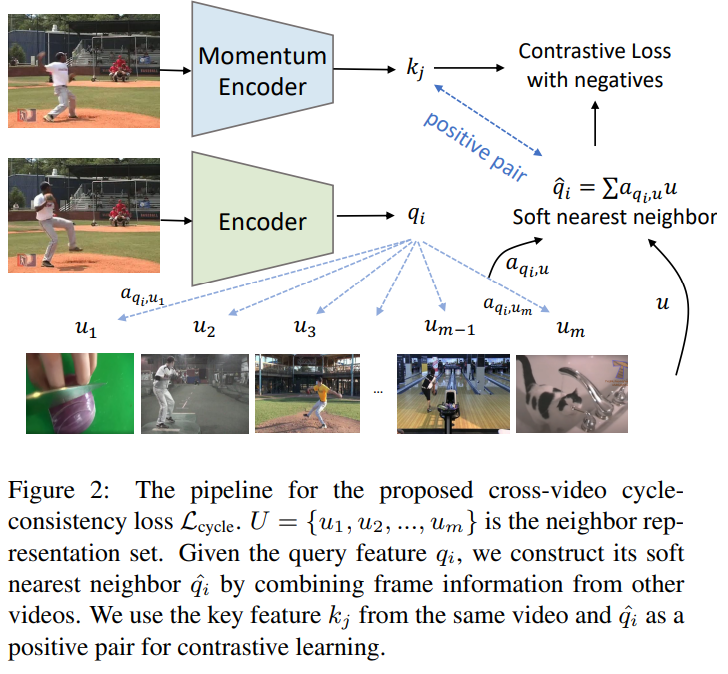
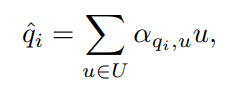
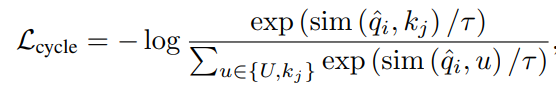
제안하는 목적식을 설명하면 다음과 같다. 우선, video V가 포함되지 않은 candidate set인 U에서 비디오 V의 frame feature q의 nearest neighbor q^을 계산한다. 해당 논문은 cycle-consistency를 학습하기 위해 q^가 q의 invariance learning set에 속하게 하도록 학습시킨다. 즉 nearest neighbor로 계산된 q^가 V의 프레임과의 유사도가 높아지도록 학습하는 것이다. related work의 표현을 그대로 사용하고자 한다면 2번식의 a(알파)가 일종의 encoder, 유사도 metric가 일종의 decoder인 샘이다. (수식 이해를 위해 주의할점. 2번식과 3번식의 u는 약간 다르다. 2번식의 u는 매 train iteration마다 랜덤샘플링되며, 랜덤 샘플링 이후 남은 샘플들을 eq 5에 사용한다. 차라리 2번식에서 유사도가 낮게 나온 샘플을 3번식의 negative sample로 사용하면 어떨까 라는 생각도 했지만, 유사도 계산이 어려워서 그런것 아닐까(2번식의 u의 encoded 값이 모두 꽤 높은 유사도를 갖는 등)라는 예측을 할 수 있을것같다.)
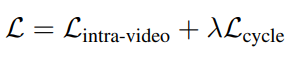
실험
실험은 R2V2(Random Related Video View)라는 비디오 데이터 셋을 학습에 사용하였다. R2V2는 2.7M의 비디오를 갖으며, subset인 R2V2-S는 109k개의 비디오(438k의 frames)를 갖는다. 해당 데이터셋은 비디오당 4 frames을 제공한다. Visual Object Tracking, image classification, video action recognition과 같은 다양한 task에 적용하여 contrastive learning methods. SOTA모델과 비교하며 확장 가능성을 보였다.
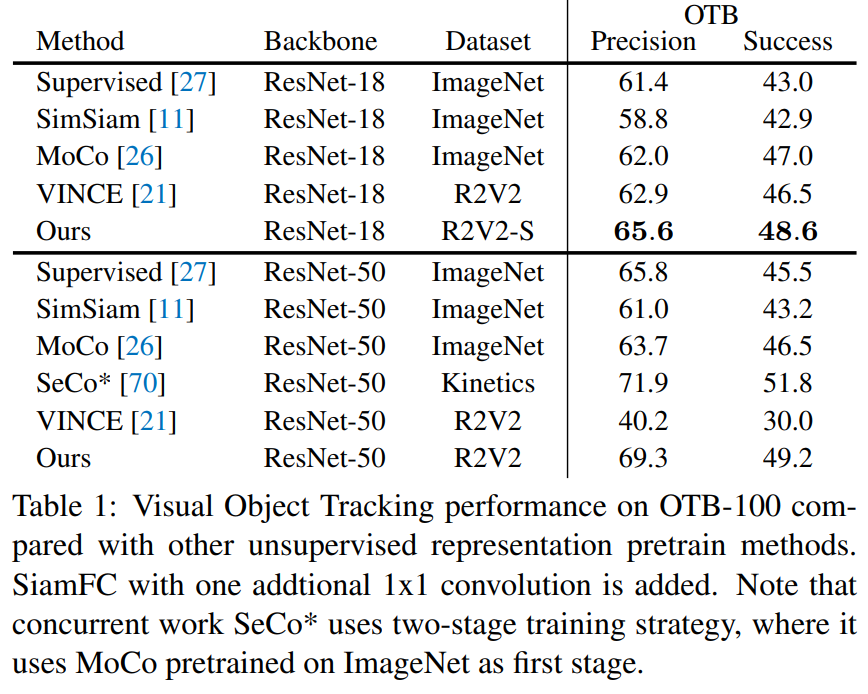
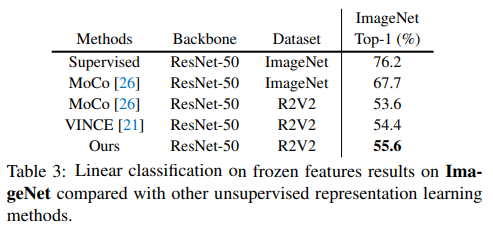
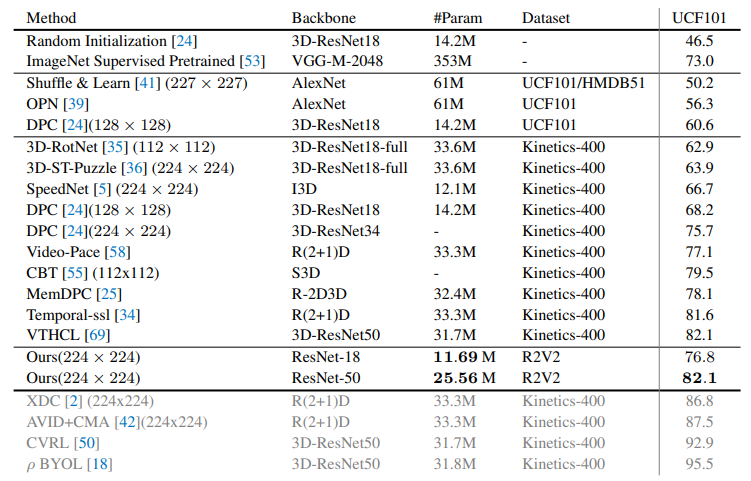
다양한 확장 실험과 ablation study가 있어 매우 자세하다는 느낌을 받았다. 본 논문은 cycle loss를 제안하여 visual structures에 대한 표현력을 기르고자 하였다. (단순 visual 유사도(부엌의 푸들)가 아닌, 개, 고양이와 같은 상위 개념적 유사도) 만약 상위 유사도를 갖는것을 정성적으로 보여주었다면(CAM 등으로) 더욱 눈이 가는 설명이 되지 않았을까 한다.
리뷰를 읽던 중 잘 읽히지 않는 부분이 있는데,
본문 내용 중 “우선, video V가 포함되지 않은 candidate set인 U에서 비디오 V의 frame feature q의 nearest neighbor q^을 계산한다.” 라는 내용에서 V의 frame feature가 q이면 q의 nearest neighbor q를 계산한다는 말은 무슨 의미인가요?
q의 nearest neighbor가 자기 자신인 q인건가요?
그리고 “2번식의 a가 일종의 encoder” 라고 하셨는데 이 a가 알파를 뜻하는 것인가요..?
네 우선 a는 알파가 맞습니다. 알파 주석 추가하겠습니다.
U라는 후보군에서 q와 유사한 q^ 데이터를 찾는다는 뜻으로, 일종의 positive pair를 U의 요소로 구성한다는 뜻 입니다. q가 video V에 속한 프레임이라면 후보군 U에는 V가 포함되지 않는다는 뜻으로,
기존 방식과 다르게, positive pair를 다른 비디오의 프레임에서 찾는다는 의미입니다!
아 q가 아니라 q^ 이었군요. 노트북으로 봐서 q^ 를 q로 봤네요ㅎ..
q^를 이렇게 치면 q처럼 보여서ㅋㅋ..