

이전에는 Convolution Neural Network가 대다수였던 것에 비해 최근에는 Transformer 구조가 Computer Vision 내의 여러 분야에서 좋은 성능을 보이며 주목을 끌고 있습니다. 이러한 와중에 Google에서는 MLP 구조만으로 CNN 혹은 Transformer의 비견될 성능을 보이는 MLP-Mixer를 제안하였고 이를 리뷰하고자 합니다.
1. Mixer Architecture
1.1 Principle
MLP-Mixer 구조를 설명드리기 앞서 현대의 딥러닝 기반 Vision 방법론들의 특성에 설명 드리려 합니다. 현대의 딥러닝 기반 Vision 방법론들은 Local 영역에서 mixed feature를 만들거나 (1), 서로 다른 Local 영역 사이에서 mixed feature를 만드는 (2) 특징들을 보유하고 있습니다. 예를 들어 CNN의 경우, Receptive field를 넓히기 위한 NxN(N>1) Convolution 연산과 pooling 연산이 특징 (2)를 나타내며, 1×1 Convolution 연산의 경우 특징 (1)을 나타냅니다. 그리고 Kernel의 크기가 입력 크기만큼 커진다면 특징 (1)과 (2)를 동시에 보유하게 됩니다. 다른 예로 Vision Transformer와 같은 self-attention 기반의 구조의 경우, patch를 projection하여 embedding 하는 과정이 특징 (1)을 나타내며 이를 활용한 self-attention layer는 특징 (2)를 나타냅니다. 현대에 주로 쓰이는 앞선 두 경우 모두 특징 (1)과 (2)를 나타내는 것처럼 MLP-Mixer도 두 가지 특징을 만족시키도록 설계되었습니다.
1.2 Mixer
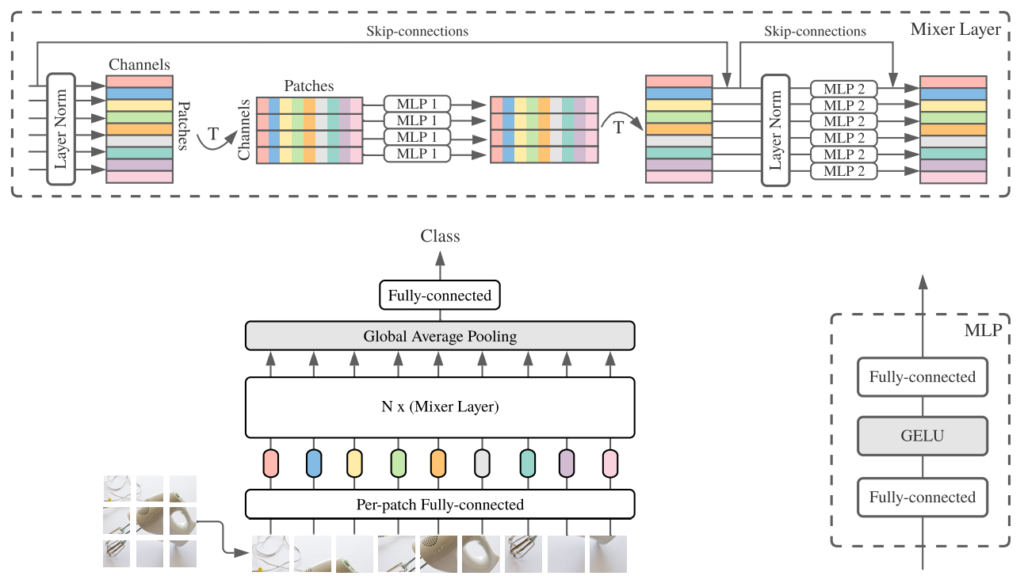
MLP-Mixer는 Fig 2와 같이 구성되어 있습니다. Image에서 NxN 개의 patch로 분리하고 이를 weight를 공유하는 FC Layer에 입력으로 주어 embedding 합니다. Embeding된 vector 들은 Mixer Layer로 들어가 Layer Norm 과정 및 Transpose된 후, channel 위치 별로 MLP 연산을 우선 거치게 됩니다. MLP 연산 시, 공유된 weight를 지니게 됩니다. 이와 같은 동일한 channel 위치 별 연산을 Token mixing 이라고 불리우며, 이를 통해 앞서 언급했던 특징 (2)를 만족시킬 수 있게 됩니다. 이후, 다시 Transpose 되고, 이번에는 각 patch 별로 Layer Norm 후, MLP 연산을 다시 거치게 되며 이때도 각 MLP의 weight는 공유됩니다. 이 과정은 Channel mixing 이라고 불리우며 특징 (1)을 만족시키는 연산에 해당됩니다. 이처럼 두 Mixer Layer 내부에서 두 가지 특징을 만족 시키도록 설계되었으며 여러 번의 Mixer Layer를 통과한 후 class를 예측하게 됩니다.
1.3 Revisiting in Mixer Layer
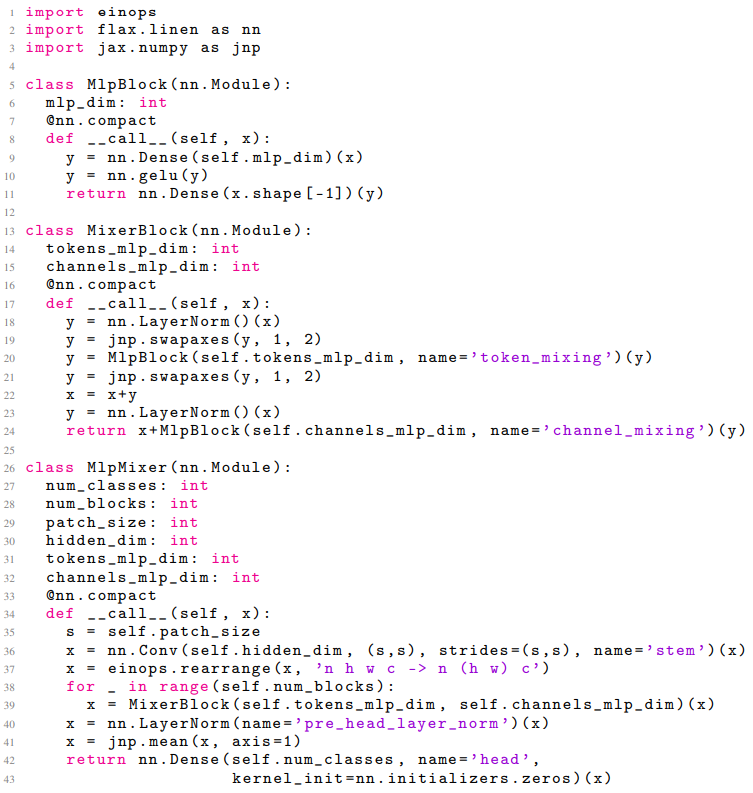
해당 논문을 리뷰하신 다른 분의 유튜브를 참고하던 중, MLP-Mixer 구조의 대한 다른 관점을 소개해주시어 리뷰에 추가해봅니다. 기억에 남았던 부분이 FC Layer가 weight를 공유하는 부분에 대한 재고였습니다. 이는 Patch를 embedding 하기 위한 첫 FC Layer 와 Mixer Layer 내 MLP 둘 다 Convolution 연산에 해당 한다는 것입니다. 첫 FC Layer의 경우, 결국 NxN의 Patch로 나눠 weight를 공유하는 FC Layer의 입력으로 들어가는 것이 stride가 N인 NxN Convolution 연산과 같습니다. 또한 Mixer Layer 내의 Token mixing의 경우 공유된 weight로 channel 별로 연산하는 것이 Depthwise Convolution 연산과 같으며 Channel mixing의 경우 반대로 한 픽셀에서 channel 방향으로 연산되기에 1×1 Convolution 연산과 같습니다. 또한 CNN의 창시자인 Yann LeCun 교수도 이와 같은 말을 남겼으며, 실제 논문에 나와있는 Mixer Layer 코드 또한 MLP 연산을 위해 Convolution method를 사용한 것으로 보아 MLP-Mixer는 온전히 Convolution free가 아닌 것을 알 수 있습니다.
2. Experiments
2.1 Specifications of the Mixer architectures
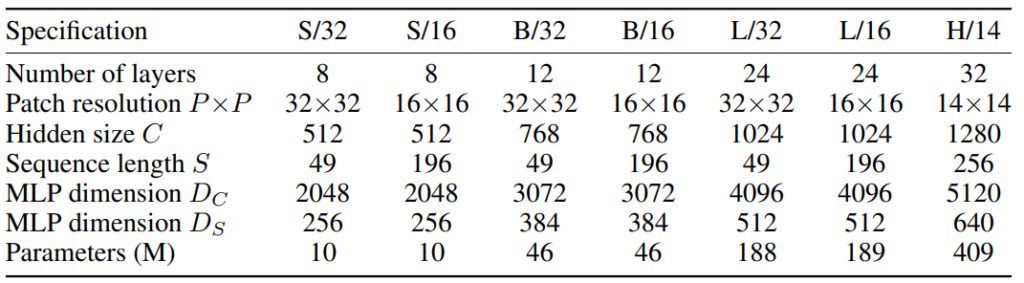
실험 결과에 대해 설명하기에 앞서 해당 논문에서 실험을 위해 사용한 구체적인 세팅에 대해 설명드리겠습니다. ViT와 같이 여러 형태의 구조를 두어 실험을 하였으며 여기서 S는 Small, B는 Base, L은 Large, H는 Huge를 의미합니다. Hidden size C는 patch를 입력으로 첫 FC Layer를 통과한 뒤의 channel 수를 의미하며, Sequence length S는 patch의 수를 의미합니다. 그리고 MLP dimension D_{C}와 D_{S}는 각각 Mixer Layer 내의 MLP 연산 후의 channel 수를 의미합니다.
2.2 Main Result
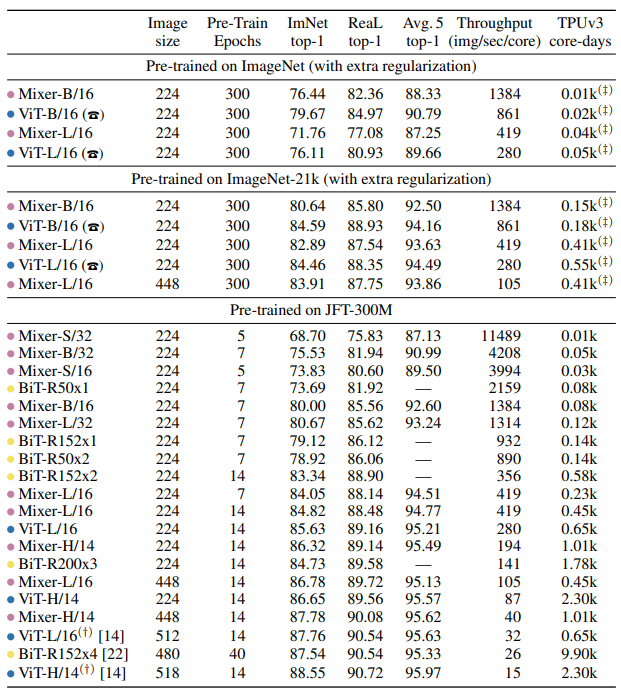
pre-training dataset scales
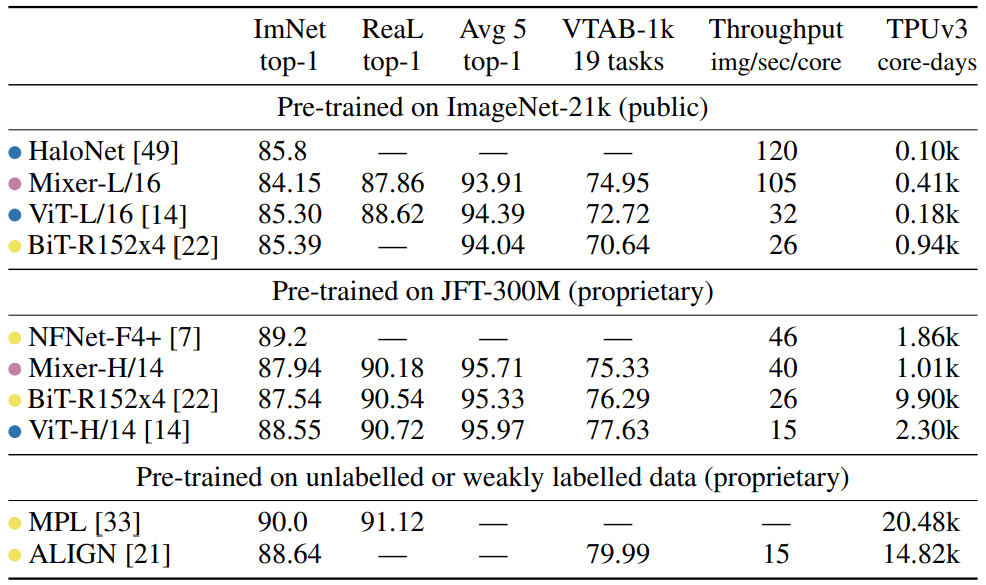
Table 2와 Table 3은 MLP-Mixer와 다른 방법론 간의 성능차이를 나타냅니다. 논문에서는 MLP로만 구성되었으나 CNN 기반 방법론이나 Transformer 기반 방법론들과의 성능차이가 많이 나지 않는다고 나와있었으나, 결국 MLP-Mixer에서 사용한 MLP 연산들은 Convolution 연산과 동일한 과정이기에 Table 2에서 다른 CNN 기반 방법론들과 성능차이도 별로 나지않고 Throughput 또한 비슷한 것으로 생각되며, CNN기반 방법론들과 Transformer 기반 방법론들이 서로 비슷한 성능을 내고 있기에 Table 3에서 온전히 Convolution-free하지 못한 MLP-Mixer와 Transformer 기반 방법론들이 비슷한 성능을 낼 수 있었던게 아닌가 싶습니다.
3. References
[1] https://arxiv.org/pdf/2105.01601.pdf
[2] https://www.youtube.com/watch?v=KQmZlxdnnuY
MLP로만 구성되었으나 CNN 기반 방법론이나 Transformer 기반 방법론들과의 성능차이가 많이 나지 않는다고 하였는데 MNIST data의 경우 CNN을 통해 위치정보로 인식률을 높였다면, 지금의 복잡한 데이터들을 대응하기에는 기존 CNN의 receptive field가 너무 작다고 해석할 수 있을까요?
좋은 리뷰 감사합니다