제가 이번에 리뷰할 논문은 OCRNet입니다. segmentation을 할 때 사용할 모델인 OCRNet에 대한 논문이라 리뷰를 하게 되었고, 기존의 OCRNet에 transformer 방식을 적용한 내용을 포함하고 있습니다. 내용은 기존의 OCRNet에 대한 설명을 위주로 작성하였습니다.
픽셀의 라벨은 픽셀이 속한 객체의 카테고리라는 것이 기반이 되었다. object-contextual representations는 객체가 대응하는 분류의 representation을 이용하여 이미지의 특징을 짓는다. OCR은 다음 3단계로 구성된다
1. GT를 이용해 object region을 학습
- contextual 픽셀을 각각 대응하는 class의 soft object regions로 나눈다. deep network로부터 coarse soft segmentation을 계산한다. 이때 학습은 gt를 이용하는 supervision으로 이뤄진다.
2. object region에 대응하는 픽셀들의 representations를 모아서 object region representation을 계산
3. 각 픽셀마다 각각의 object region과의 관계를 계산하고 object-contextual representation(OCR)과 픽셀의 representation을 늘린다.
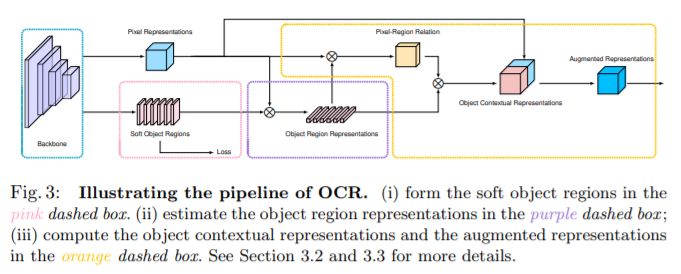
위의 1~3을 transformer encoder-decoder방법을 이용하면
1. 위의 1,2 과정은 decoder의 cross-attention모듈로 합친다.
- 픽셀을 분류하는( object region을 생성하는) linear projection은 Category Queries, object region representations는 cross-attention의 출력이다.
2. encoder에 추가한 cross-attention모듈
- key와 value는 decoder의 출력이고 queries는 각 위치에서의 representation이다.
contextual pixel을 object region으로 구조화하고 픽셀과 object regions의 관계를 이용한 다는 점이 기존 방식과의 차이점이다.

Formulation

yi 는 Pi 에서의 object contextual representation Wik 는 i번째 픽셀과 k번째 object region의 관계를 나타내고, fk 는 k번째 object region에서의 representation, δ()와 ρ()는 transformation functions이다.
- 이미지 I를 K soft object region {M1,M2,…,MK}으로 구조화한다.
object region MK 는 class k에 대응하고, 2D map(혹은 coarse segmentation map)으로 표현되고, 대응하는 픽셀이 class k에 속하는 degrees를 나타내는 것으로 구성된다. backbone에서 나온 representation으로 K object reions를 계산하고, GT를 이용하는 supervision으로 학습되며 이때 cross-entropy loss를 이용한다.
- Object region representations를 구한다.
kth object region에 속하는 degrees를 가중치로 모든 픽셀에 준 representations를 합친다. Xi 는 픽셀 Pi 의 representation이고 ![]() 는 Pi 가 kth object region에 속하는 degree를 정규화 한 것이다. 각 object region normalize MK 에 spatial softmax를 이용해 정규화한다.
는 Pi 가 kth object region에 속하는 degree를 정규화 한 것이다. 각 object region normalize MK 에 spatial softmax를 이용해 정규화한다.

- 각 픽셀과 각 object region의 관계를 계산한다.
k(x, f) = ɸ(x)T φ(f)로 정규화되지 않은 관계 함수이고, ɸ()와 φ()는 2개의 transformation 함수이다.

- Augmented representations
Pi 의 마지막 representation은 original representation xi와 object contextual representation인 yi 두 파트로 업데이트 된다. g()는 transform 함수로 original과 object contextual를 fuse하기 위해 사용한다.

** δ(), ρ(), ɸ(), φ(), g()는 모두 1×1 conv → BN → ReLU를 실행한 것 **
Architecture
- Backbone
backbone은 dilated ResNet-101 또는 HRNet-W48을 이용한다. dilated ResNet-101을 이용하면 coarse segmentation을 예측하는 첫 번째 representation과 3×3 conv을 통과한( 512 output channels) final representation을 OCR module의 input으로 사용하고 HRNet-W48은 final representation만 OCR module의 input으로 사용한다.
- OCR module
coarse segmentation(soft object region)을 예측하기 위해 linear function(1×1 conv)을 사용하고, pixel-wise cross-entropy loss를 사용하여 supervised를 수행한다. δ(), ɸ(), φ(), ρ(), g()는 모두 1×1 conv → BN → ReLU를 실행한 것으로 δ(), ɸ(), φ() output은 256 channels이고 ρ(), g() output은 512 channels로 구현된다.
Empirical Analysis
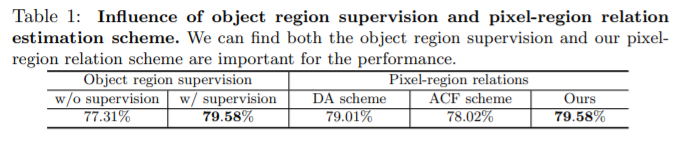
- Object region supervision _ gt를 이용하지 않고 auxiliary loss를 추가한 w/o supervision보다 gt를 이용한 w/ supervision 성능이 좋다. (supervision의 중요성 리포팅)
- Pixel-region relation _ pixel representation과의 관계를 추정할 때 region representation을 이용한 결과(Ours)가 그렇지 않은 경우보다 성능이 좋다. (object region을 고려하는 것의 장점)
object region을 이용하면 특정 이미지에 있는 object의 특징을 나타낼 수 있으므로 pixel representation만 이용하는 것 보다 더 정확한 관계를 나타낼 수 있다.
Ground-truth OCR _ object region과 pixel-region relation 형성에 gt segmentation을 이용해 segmentation을 수행한다.
– object region형성에 gt를 사용할 때 : li(ith 픽셀의 정답 라벨) ≡k 이면 mki = 1, 그렇지 않으면 mki = 0
– pixel region형성에 gt를 사용할 때 : li ≡k 이면 wik = 1, 그렇지 않으면 wik = 0
Experiments: Semantic Segmentation
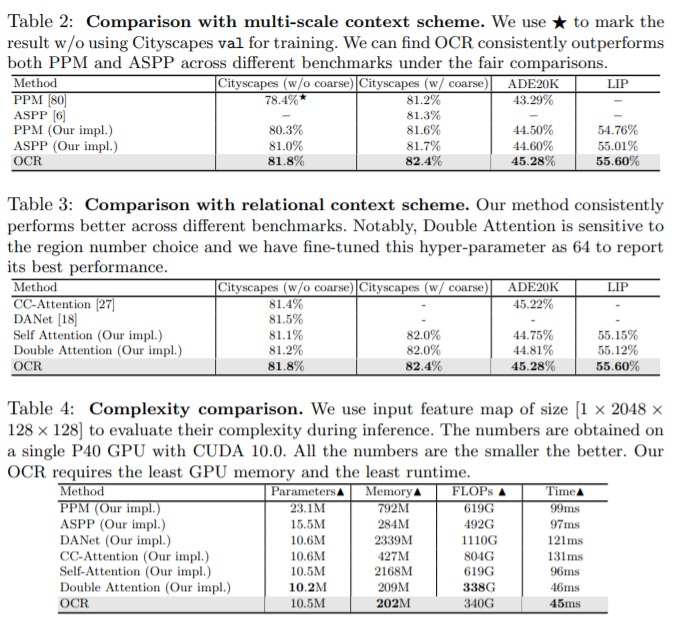
- 다른 schemse와 비교
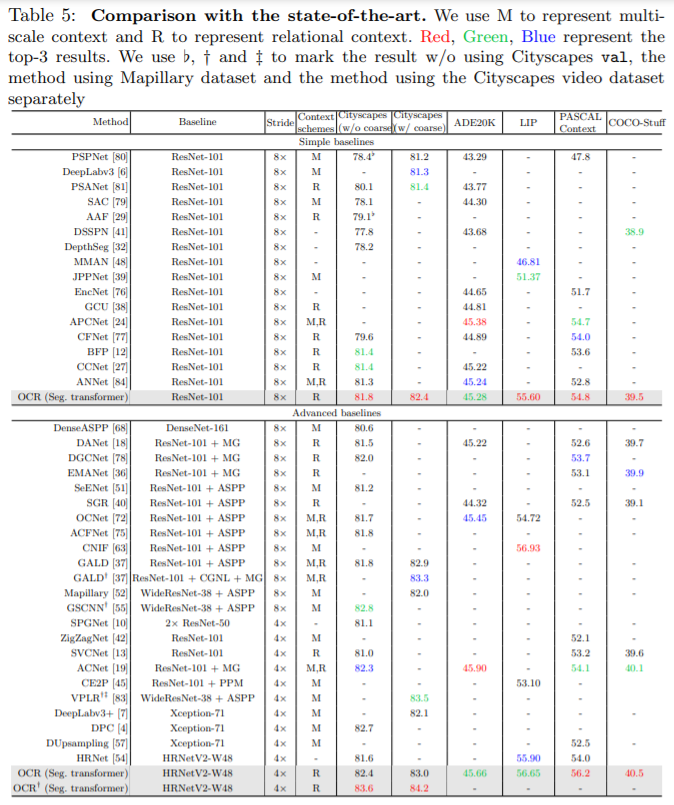
- SOTA와 비교
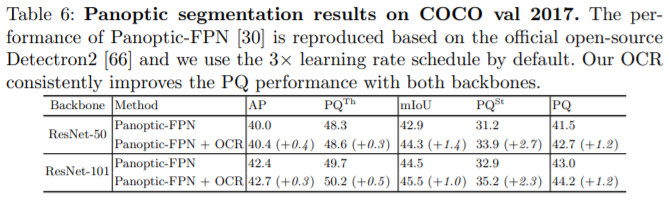
Experiments: Panoptic Segmentation
Conclusions
각 픽셀의 label은 해당 label에 대응하는 object에 속하는 픽셀들이고, 픽셀 representation은 각 픽셀이 대응하는 object region representation의 특징을 나타내며 pixel representation을 늘리는 것이기 때문에 이 방법이 성공했다.
이 논문의 contribution은 기존의 pixel간의 관계가 아닌 pixel과 object region의 관계를 고려하였다는 것과 이러한 방식으로 구한 object contextual representation을 이용하여 성능을 향상시켰다는 것으로 정리할 수 있을 것 같습니다.