- 소개 [Link]
본 논문은 video에서 action part를 찾는 task 를 위한 논문이다(Temporal action localization task 이하, TAL).
기존의 Weakly Supervised 기반의 TAL 방법론들은 비디오 단위의 레이블을 이용하여 문제를 해결하고자 하였고, 일반적으로 비디오를 짧은 세그먼트나 frame으로 나누어 top-k 방식을 통해 학습한 분류기로 action or not 을 분류하여 Localization을 진행하였다.
저자는 일반적인 방식에서 사용하던 top-k 방식이 구별하기 어려운 action instances(clip이나 frame같은 단위, 이하 instance)의 영향력을 줄이는 등, 직접적인 action instance(행동성, actionness)를 찾는 것에 좋지 않은 영향을 미친다고 한다.
이러한 기존 방식의 행동성에 대한 능력 저하는, context error 와 actionness error 라는 결과를 도출하며, 각 결과는 다음과 같다.

- context error:
어떠한 instances가 실제로는 actionness를 갖지 않지만, 비디오의 전반적인 내용(context)을 담고있을 때, 이를 혼동하는 오류 - actionness error:
classifier가 action을 포함한 instance에서 반응하지 않는 오류.
저자들은 저자들이 정의한 위와같은 오류를 해결하기 위하여, context information과 action instance 구별을 위한 학습을 잘 진행하는 task에 의존적이지 않은 learning framework를 제시하였다. (최근의 attention을 이용한 filtering 방법론이 background를 제거하여 context 정보 손실을 만든다는 단점을 언급하였는데, 지난번 TSP 논문과 마찬가지로 background 정보(non-action) 또한 중요하게 다루는 것이 흥미로웠다. )
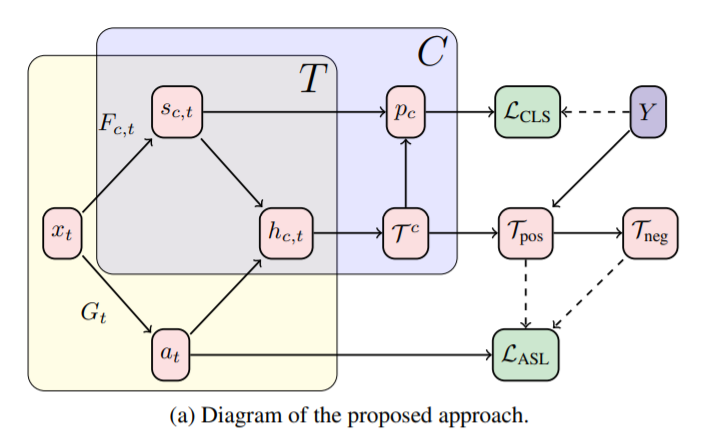
본 논문은 supervised 방식의 object detection task와 temporal localization task를 통한 학습 방식을 제안하였으며, Action Selection Learning (ASL)이라 명명하였다.
2. 작동 방식
v = {x_1 … x_t} (t 개의 instance(x_n)으로 구성된 비디오 v)
각 비디오 V는 video level의 label{1,…C}을 갖음
- C
그림2의 C는 video level label을 이용한 학습이다. (SEAM에서 보았던 weakly supervised 학습법처럼) class activation sequence 를 이용한다. - T
그림 2의 T는 actionness의 감지를 위한 학습이다. 이는 제안하는 ASL의 핵심이다. 제안하는 방식의 핵심 아이디어는 다음과 같다. <<main idea: class예측에 사용된 top-k개의 instances는 context instance와 action instance를 모두 갖고있다. 그러나 context instance는 class-specific하고 action instance는 모든 class에 걸쳐 유사하다.>>
이러한 아이디어를 가지며 해당 모델은 다음과 같이 구현되었다.
– actionness 감지를 위한 G 모델과 그 output a
– class 감지를 위해 사용되었던 F 모델과 그 output s
두 output값을 h(a, s) =βa + (1 − β)s 와 같은 방식으로 혼합하여 G모델이 입력 instance x 가 모든 ground true class 에 속하는 지에 대해 예측하는 방향으로 학습하도록 하는것을 목적으로 한다.
본 모델의 학습을 위해서도 위와같이 video level label을 이용하나, C처럼 단순 video level label classification 방식이 아니다.
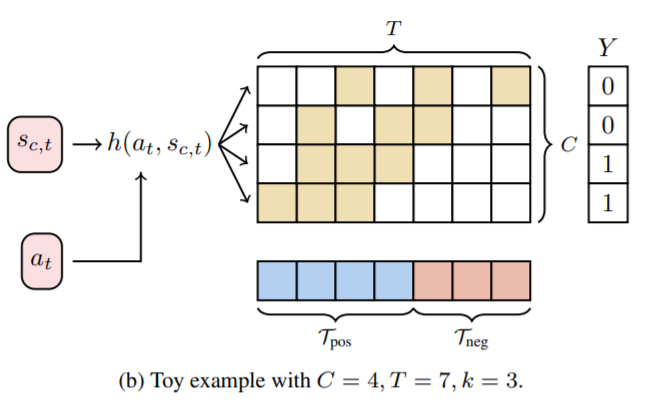
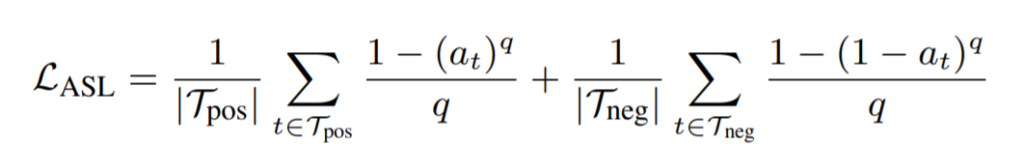
3. 실험
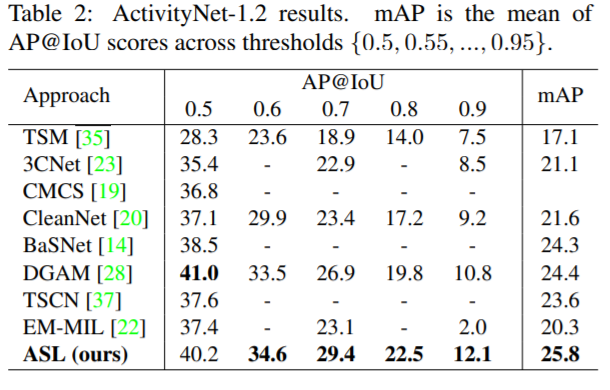
본 논문은 TSL에 많이 사용되는 THUMOS-14 와 ActivityNet-1.2 데이터셋에 대해 실험하여 좋은 성능을 보였다.
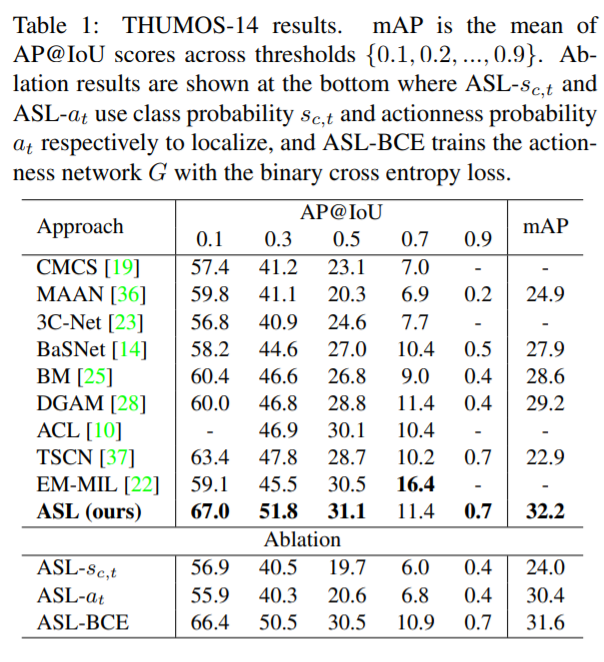
지난번에 TSP를 발표해주셨는데요. 설명해주신 바를 이해 했을 때, 두 구조 모두 Action에 대해 foreground와 background를 나누는 구조로 받아들였습니다.
그러면 혹시 해당 구조와 TSP의 차이는 어떤 것인가요?