Before Reivew
지난주에 작성하던 Gradient Descent optimization review를 계속 이어서 진행하겠습니다. 본격적으로 시작하기 전에 지난에 작성했던 Review를 다시 복습해보도록 하겠습니다.
- Development of Gradient Descent

Vanilla SGD로부터 크게 두가지의 흐름을 지난 Review에서 살펴봤습니다.
첫번째는 Momentum항을 추가하여 학습에 가속을 붙게하고 local minima로 부터 갇힐 위험을 줄여주는 방법 (Momentum , NAG)
두번째는 Adaptive Learning rate로 모든 Parameter에 같은 learning rate를 적용하는 것이 아닌 , parameter의 update 빈도수에 따라 제각각 다른 Learning rate를 적용해주는 방법 (AdaGrad , RMSProp , AdaDelta)
이번 Review에서는 Adaptive Learning rate의 방법인 AdaDelta에 대해 알아보고 Momentum과 Adaptive learning rate를 혼합시킨 Adam을 살펴보도록 하겠습니다.
Gradient Descent Optimization algorithms
Adadelta
Adadelta는 지난주에 다루었던 Adagrad의 확장판입니다. Adagrad의 문제점이 어떤 문제였는지 빠르게 짚어보고 가겠습니다. Adagrad에서 parameter들이 얼마나 자주 update 되었는지 기록하기 위해 G_{t} 라는 vector를 정의해주었습니다. 다만 이 G_{t} 구해주는 과정에서 G_{t}=G_{t-1}+(\nabla_{\theta_{t} } J(\theta_{t} ))^{2} Gradient의 제곱항이 계속 더해지므로 \frac{\eta }{\sqrt{G_{t}+\epsilon } } 값이 계속 작아지면서 step이 멈춰버리는 단점이 존재했습니다. RMSProp는 이런 단점을 G_{t} 구해주는 과정에서 decaying factor \gamma 값을 곱해줘서 조절해주고 있었습니다.
- G_{t+1}=\gamma G_{t}+(1-\gamma )(\nabla_{\theta } J(\theta ))^{2}
- s_{t+1}=\gamma s_{t}+(1-\gamma )\triangle \theta^{2}
- \triangle \theta =\frac{\sqrt{s_{t}+\epsilon } }{\sqrt{G_{t}+\epsilon } } \odot \nabla_{\theta } J(\theta_{t} )
- \theta_{t+1} =\theta_{t} -\triangle \theta
Adadelta의 전체적인 방향은 RMSProp와 비슷합니다. G_{t}를 구해주는 과정이 동일하지만 parameter를 update 해줄 때 이제 learning rate \eta 를 사용하지 않습니다. s_{t} 라는 vector를 이용하여 learning rate를 대체하고 있는데 G_{t}는 parameter가 얼마나 자주 갱신됐는지를 담고 있는 vector라면 s_{t}는 parameter가 얼만큼 갱신이 됐는지 parameter의 누적 변화량을 담고 있다고 보시면 됩니다.
한가지 의문이 들어야 하는 부분은 그냥 RMSProp 처럼 \frac{\eta }{\sqrt{G_{t}+\epsilon } } 이렇게 learning 쓰면 되지 뭐하러 s_{t} 계산을 해서 메모리와 computation을 낭비하나 이런 의문이 들지만 저자가 이제 얘기하길 어떤 단위를 맞춰주기 위한 작업이라고 합니다.
\theta_{t+1} =\theta_{t} -\triangle \theta 이 부분을 다시 살펴보면 \nabla \theta 의 단위가 \theta_{t} 랑 같게 맞춰야 하지 않겠느냐 이런 관점에 Adadelta를 살펴보면 \nabla_{\theta_{t} } J(\theta_{t} ) 이녀석의 단위는 우선 \theta_{t} 와 같을 수가 없습니다. 미분을 했기 때문입니다. \frac{1}{\sqrt{G_{t}+\epsilon } } 의 단위는 Loss 함수의 2차 Gradient의 제곱근이기 때문에 \nabla_{\theta_{t} } J(\theta_{t} ) 이친구와 단위가 같게 됩니다. 둘은 분자 분모에 위치하고 있기때문에 상쇄가 됐고 이제 \sqrt{s_{t}+\epsilon } 이 친구의 단위만 따져 보면 되는데 s_{t+1}=\gamma s_{t}+(1-\gamma )\triangle \theta^{2} 보시다시피 단순히 \theta_{t} 변화량의 제곱의 루트가 씌워진 형태이므로 단위는 \theta_{t} == \sqrt{s_{t}+\epsilon } 이렇게 되고 결국 update 과정에서 단위가 통일되게 됩니다.
찾아보면서 확인해봤을 때 실제로는 Adadelta가 Adagrad에 비해 무조건 좋은 것은 아닌가 봅니다. Adagrad가 더 잘 될때도 있고 Adadelta가 더 잘 될때도 있다고 합니다.
Adam
이제 바로 그 유명한 Adam입니다. 쉽게 설명하면 두가지로 나눠진 흐름을 다시 한데 묶어놓은 방법론입니다. Momentum으로 얻을 수 있는 이점과 Adaptive learning rate를 이용해서 얻을 수 있는 이점을 동시에 챙긴 균형잡힌 Optimizer라고 생각하시면 됩니다.
- m_{t}=\beta_{1} m_{t-1}+(1-\beta_{1} )\nabla_{\theta } J(\theta )
- v_{t}=\beta_{1} v_{t-1}+(1-\beta_{1} )(\nabla_{\theta } J(\theta ))^{2}
- \hat{m}_{t} =\frac{m_{t}}{1-\beta^{t}_{1} } , \hat{v}_{t} =\frac{v_{t}}{1-\beta^{t}_{2} } — (1)
- \theta_{t+1} =\theta_{t} -\frac{\eta }{\sqrt{\hat{v}_{t} } +\epsilon } \hat{m}_{t}
paramter를 update 해주는 과정은 전과 비슷합니다. Gradient 부분에 \hat{m}_{t} 이 들어가있는 것을 제외하고는 이전과 동일합니다. 다만 \beta_{1} =0.9,\beta_{2} =0.999,\epsilon =10^{-8} 이렇게 값을 취해주면 학습 초기에 parameter update가 너무 크게크게 발생합니다. 대입해보면 금방 확인할 수 있습니다. 그렇기 때문에 (1)에서 값을 보정해주는 것입니다. 이는 학습 초기에만 너무 step이 튀지 않게끔 조절해주는 역학을 하면 학습이 나중에 진행되면 크게 상관이 없다고 합니다. 핵심은 momentum의 개념과 Adaptive learning rate의 개념을 동시에 사용했다는 점 입니다.
Visualization of algorithms
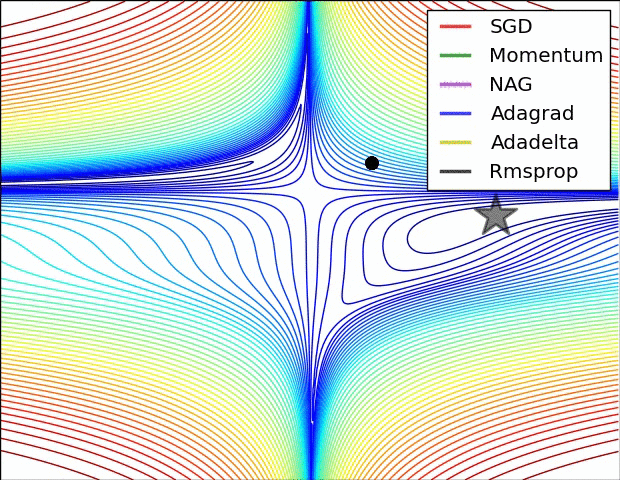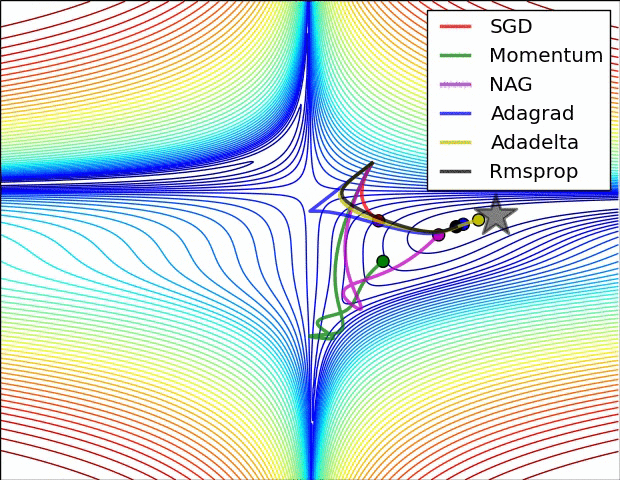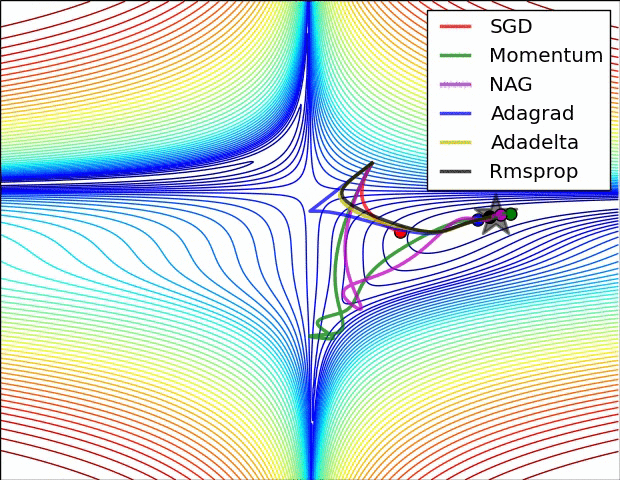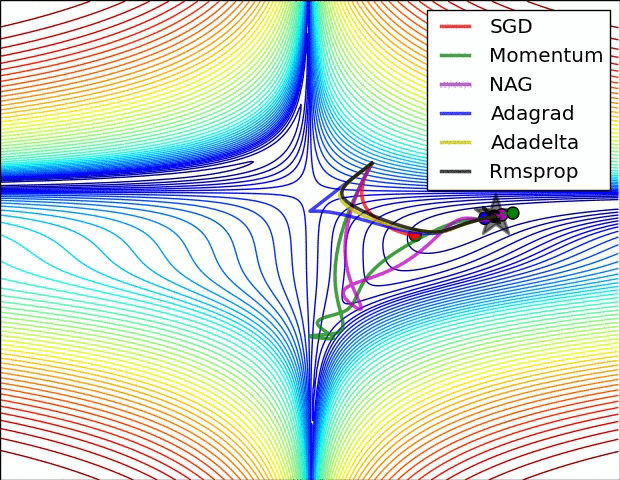
Gradient Descent algorithm들의 큰 흐름을 살펴보았고 이제 본 Paper에 실려있던 그림을 확인해보겠습니다. 위의 그림을 살펴보면 optimizer 별로 loss surface상에서 경로들을 비교하면서 확인할 수 있습니다. 모두 같은 point에서 시작했지만 다른 경로로 minima에 수렴하고 있습니다. Adagrad , Adadelta , Rmsprop 같은 경우는 즉시 수렴하는 것을 확인할 수 있고 , momentum과 NAG는 조금 방향을 헤매는 것을 확인할 수 있습니다. momentum과 NAG사이에서도 NAG가 좀 더 빠르게 수렴하는 것을 확인할 수 있는데 Review1에서 확인했던 이유이지 않나 싶습니다.
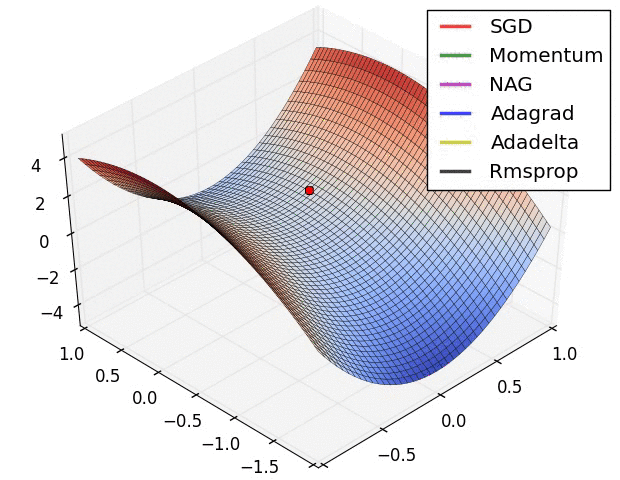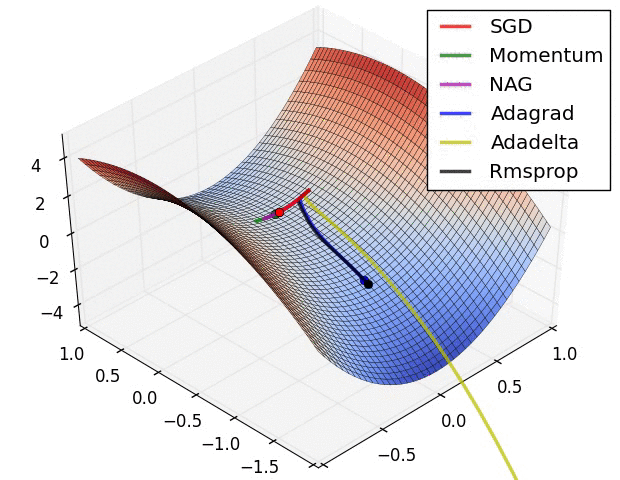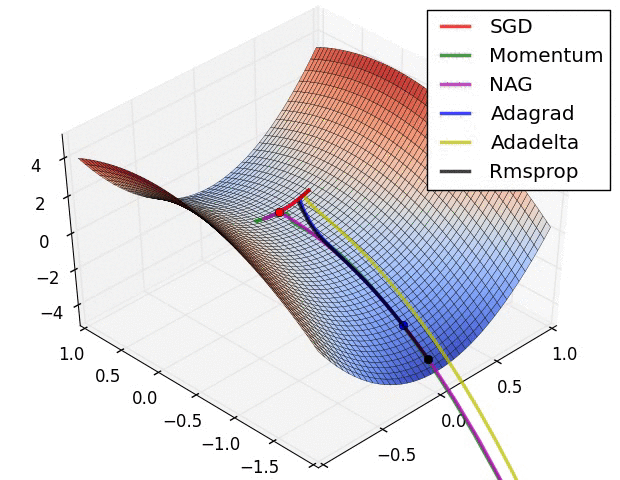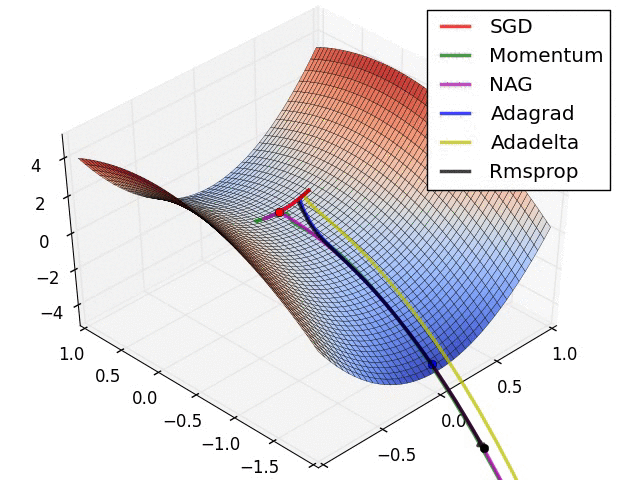
SGD를 제외하고서는 모두 saddle point에서 탈출 하는 것을 확인할 수 있습니다.
Additional strategies for optimizing SGD
- Shuffling and Curriculum Learning
일반적으로 model을 학습을 시킬 때 어떤 data에 대한 편향을 가지지 않도록 하기 위해서 training dataset을 제공하는 것이 중요했습니다. 따라서 우리가 data를 건내줄때 일반적으로 shuffle을 시켜서 주는 것이 당연했습니다. 이러한 방법이 SGD에 도움이 된다고 합니다.
또한 이렇게 데이터를 무작위로 섞어서 주지않는 방법도 있다고 합니다. Curriculum learning이라는 것인데 일반적으로 사람이 초급 수준의 학습부터 대학 수준의 학습내용까지 긴 기간을 가지고 학습하는 경우 처럼, 이를 머신러닝의 학습에 적용하는 것입니다.즉 , 커리큘럼 학습은 처음에는 모델한테 쉬운 샘플만 보여주다가 점차 어려운 샘플을 보여주는 것입니다. 학습 시에 전체 데이터를 한번에 학습시키는 것보다 처음에는 쉬운 데이터 그 다음으로 어려운 데이터 순으로 제공하는 것을 의미합니다.
- Batch Normalization
학습을 용이하게 하기 위해 종종 data들의 정규화를 진행해주곤 합니다. 이러한 정규화된 분포의 특성을 layer들을 통과하면서 잃어 버리게 되고 학습의 저하를 일으키게 합니다.이때 Batch Norm을 적용해줌으로써 각 Layer에 들어가는 input data들이 동일한 분포를 가질 수 있도록 해줍니다. 결과적으로 수렴속도가 빨라지고 , 모델의 성능에도 좋은 효과를 볼 수 있다고 합니다.
- Early stopping
모델이 너무 많은 Epoch를 돌다 보면 training dataset에 overfitting 되어버리기 때문에 validation error를 측정하다가 개선의 여지가 보이지 않으면 학습을 중단하는 것을 의미합니다.
- Gradient noise
다음과 같이 gradient에 Gaussian noise를 첨가해주는 것을 의미합니다.
g_{t,i}=g_{t,i}+N(0,\sigma^{2}_{t} ) , \sigma^{2}_{t} =\frac{\eta }{(1+t)^{\gamma }}
자세히 이유는 다루고 있지 않는데 , 이렇게 noise를 첨가해주면 network가 좀더 initialization에 robust 해진다고 합니다. 모델이 local minima를 탈출할 기회를 더 많이 가진다고 해서 그렇다고 합니다. 개인적인 생각으론 noise가 minima에 빠져있는 상황에 일종의 action을 주는 event 같은 느낌인 것 같습니다.
Conclusion
2주에 걸쳐 gradient descent optimization algorithm에 대해서 알아봤습니다. 처음에 가장 기본적인 gradient descent의 세가지 방법론을 알아봤고(batch , stochastic , mini-batch) gradient descent가 가지는 한계점에 대해서 살펴봤습니다. 그 한계점에 기반해서 Gradient Descent를 보완시킨 여러가지의 optimizer들을 수식을 통해 작동원리를 파악했고 이러한 optimizer 전략외의 다른 방법들 또한 아주 알아 볼 수 있었습니다.
Review를 진행하면서 Gradient Descent Optimization 부분에 관해서 과거 연구자들의 고민의 발자취 들을 살펴볼 수 있었던 Paper였습니다. Review 읽어주셔서 감사합니다.
SGD 이후 optimizer에 대해 설명해주셨는데, pytorch 코드에서 사용 시 SGD 함수의 존재하는 momentum과 같은 변수를 조정하면 설명해주신 momentum optimizer 처럼 사용할 수 있을까요?
네 단순하게 SGD에서 momentum parameter(default=0)만 설정해주면 momentum 방식으로 SGD가 작동하는 것을 확인할 수 있습니다. 통상적으로 0.9 정도의 momentum factor를 사용한다고 하네요 momentum factor가 제가 review에 적어놓은 감마 값에 해당하는 factor입니다.