이번 논문은 처음으로 VIO에서의 end-to-end 방법을 제안한 VINet을 리뷰하고자 합니다. 이전 소개한 리뷰인 Selective sensor fusion의 근간이 되는 방법으로 vision은 CNN으로 inertial은 seq-to-seq 방법을 이용하는 방법을 사용합니다.
Intro
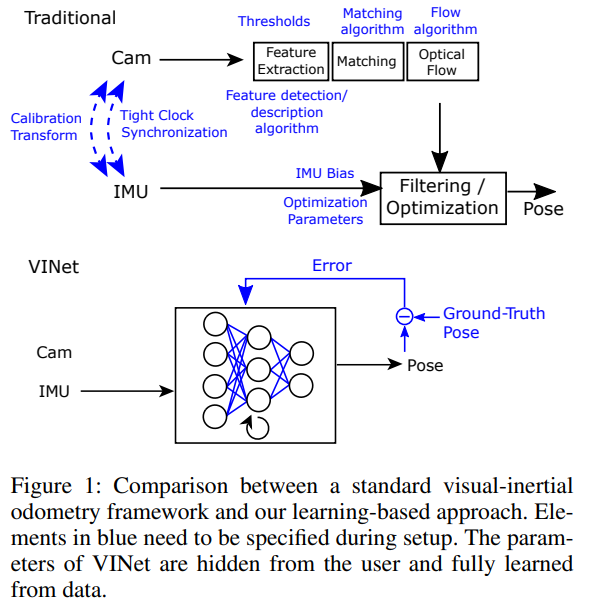
기존의 방법론들은 Figure 1의 상단과 같은 흐름을 가집니다. 전통적인 기법들은 수작업이 요해지는 카메라와 IMU 센서간의 동기화와 캘리브레이션이 성능에 매우 큰 영향을 끼칩니다. 이런 부분에서 저자는 학습을 통해 파라미터를 업데이트함으로써 러닝 기반의 VIO는 수작업, 튜닝이 필요한 부분을 제거 할 수 있기에 매우 유연하며 발전 가능성이 있는 방법이라고 주장합니다.
해당 논문의 기여는 아래와 같습니다.
- End-to-end의 학습 가능한 VIO를 처음 발표
- RNN과 CNN을 결합한 아키텍쳐를 제안
- 미분 가능한 포즈 결합 예측 층으로 SE(3)의 매니폴드를 예측하도록 함.
- 전통적인 기법과 비교.
++ 러닝 기반으로는 처음 제안된 논문이라, DNN이 들어간 방법은 다 기여라고 보시면 됩니다. 논문에서는 RNN과 역전파까지 소개합니다.
Method
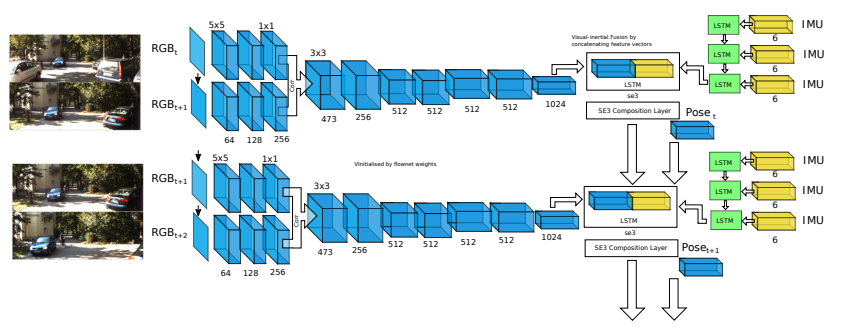
이번 논문은 딥러닝에 대해 이미 알고 있는 우리에게는 너무나 간단한 논문입니다. 높은 차원을 가진 영상과 6차원의 가속도 데이터(선형/회전)를 가진 IMU Dataf를 각각 CNN과 LSTM에 태워 임베딩 시키고 결합시켜 다시 LSTM에 태워 카메라의 6DoF를 예측하는 방법을 사용합니다. (해당 방법론에서는 6DoF ~ 3차원의 위치 벡터, 4차원의 회전 벡터(쿼터니언)를 출력 값으로 사용합니다.)
추가적으로 영상과 IMU 센서 취득 시간을 고려하여 네트워크를 설계합니다. IMU 센서의 데이터 취득 주기는 100Hz로 영상 센서의 데이터 취득 시간을 10Hz로 가정 했을 때, 대략 10배로 빠른 속도로 정보를 획득합니다. 저자는 이런 특징을 이용하여 IMU 센서는 별개로 작은 크기의 LSTM을 태워 영상 데이터가 취득될 사이에 10개의 데이터를 이용합니다. 두 장의 영상이 취득되면 CNN에 태워져 optical flow 정보와 유사한 값과 결합되어 core LSTM에 태워져 frame-to-frame의 pose se(3)을 예측합니다. VIO는 점진적으로 se(3)을 예측하여 SE(3)을 예측합니다.
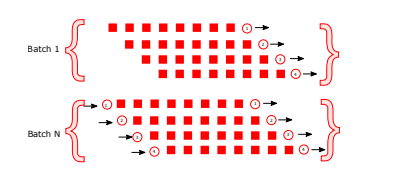
또한 연속적인 정보를 사용하기 때문에 정보가 계속 누적되다보면 메모리를 초과하게 됩니다. 그렇기에 해당 방법론은 batch 단위로 정보를 슬라이딩 윈도우로 나눠 학습에 사용합니다.(++ 그냥 우리에게는 당연한 방법이지만, 처음 end-to-end가 제안된 논문임)
Loss 수식은 frame-to-frame 간 포즈 차이를 계산하는 손실 함수로 통해 파라미터 최적화를 학습합니디. w은 rotation vector, v는 translation vector에 해당합니다.
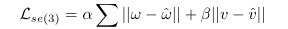
하지만 VO는 프레임간 점진적으로 계산된 포즈를 계산하여 현재 포즈 SE(3)를 알아내는 것이 목표입니다. 저자는 추가로 full concatenated pose SE(3)에 대한 손실 함수를 추가함으로써, 국소적인 예측과 전체적인 예측에 대해서도 학습하도록 합니다. 쿼터니언 q와 global translation vector T에 해당합니다.
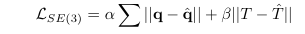
두 Loss는 아래와 같은 알고리즘으로 전달되어집니다.

재밌는 부분이 SE(3) Loss는 두 센서가 결합된 벡터가 태워지는 Core LSTM에만 전달하고 se(3) Loss는 모든 층에 전달되어집니다.
Experiment
실험에 사용된 데이터는 KITTI(실외/차량), EuRoC-MAV(실내/MAV)이 사용되었습니다.
실험에 비교 방법론은 Open Keyframe VISual-inertial odometry(OK-VIS)를 이용하였습니다. 실험은 두 센서간의 보정 및 동기화가 이뤄지지 않을 경우에 강인성을 증명하고자 합니다.
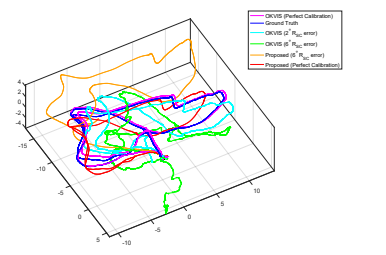
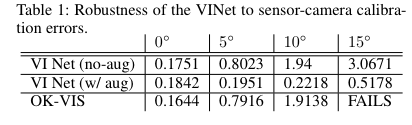
위의 그림과 표와 같이 VINet은 기존 정통적인 기법보다 성능이 떨어집니다. 하지만 두 센서간 보정이 틀어진 경우에 VINet은 상대적으로 성능이 보전되는 것을 확인 할 수 있습니다. 이는 수동적인 노력이 필요한 보정에 러닝 방법이 좀 더 자유롭다는 증명이 되기도 합니다.
My OP
러닝 기반의 VIO의 방향을 제시한 논문이기에 의미가 크긴하다… 근데 처음에 제안된 방향이 센서 강인성이였다니… 이전에 읽거나 다음 러닝 기반의 VIO들은 센서 강인함에 대해 그대로 가져가는지 잘봐야겠다.