- 논문이 집중한 문제
해당 논문은 Temporal Action Localization, Action Proposal Generation, Dense Video Captioning 세가지 task의 성능을 향상 시키기 위한 pretrain 기법을 소개하는 논문이다. 본 논문에서 제한하는 기법을 이용한 video encoder 는localization algorithms의 주요 part 중 하나이며, 이후 다른 모델들의 성능을 향상시킬 것이므로 해당 문제의 중요성을 언급한다.
많은 최근의 연구에서 video를 untrimmed video를 입력으로 하기 위해 downsampling하는 과정을 거친다. 보통은 precomputed clip features 을 위한 모델을 encoder 모델로 선택하는데, 해당 논문은 temporal localization task 에 적합하게 precomputed feature를 개선한다.
이를 좀 더 자세하게 말하자면, 기존의 연구들은 Trimmed Action Classification(TAC) task를 위한 pretrained 모델을 통해 video encoder를 구성하는데, 이러한 방식으로 구성된 encoder는 localization task에 적합하지 않다. TAC task 에서는 action이 포함된 foreground segments와 background segment가 유사하기 때문이다.
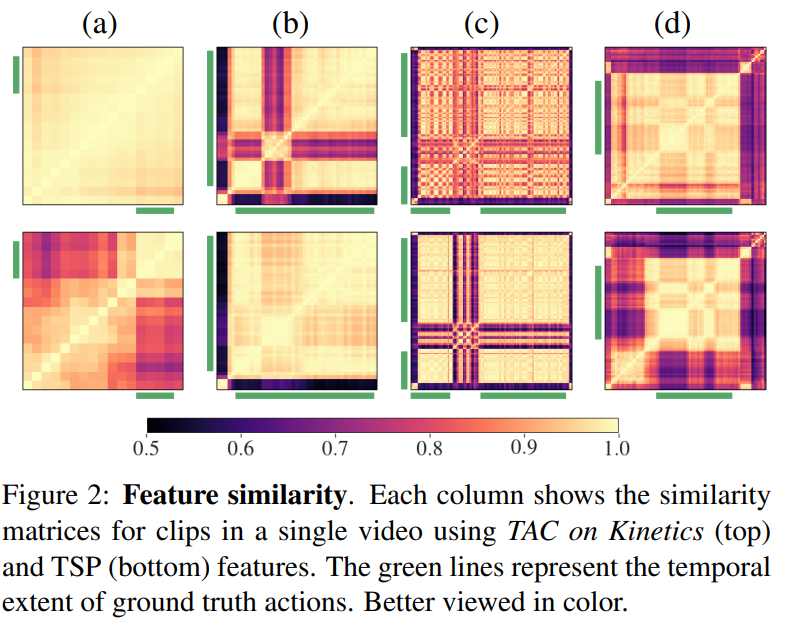
위의 그림에서 확인할 수 있듯이, 기존의 encoder 접근 방식은 segment를 action에 따라 나누기 어렵다. 직관적으로, 기존의 encoder 접근방식인 TAC는 전체의 짧은 영상동안 하나의 action을 진행하기 때문이다. 이러한 특성 때문에 각 action 간의 분류를 가능하게 할 수는 있지만, action과 background 요소를 구분하는것은 불가능할 수 있다. 그러나 TAL(Temporally Action Localization) 문제는 action과 background를 구별하는 것이 중요하기 때문에 이에 대한 개선이 필요하다.
2. 해결 방법
기존의 방식의 encoder 를 TAC-pretrained encoder 라고 하자. TAC-pretrained encoder 는 video의 positive sample (action/forground )만을 입력으로 다루었다.
untrimmed video를 입력으로 받는 encoder는 1) action 구별 능력 뿐만 아니라, 2) action과 background를 구별하는 능력도 있어야 한다.
이를 위해 제안한 pretrain 기법은 다음과 같다.
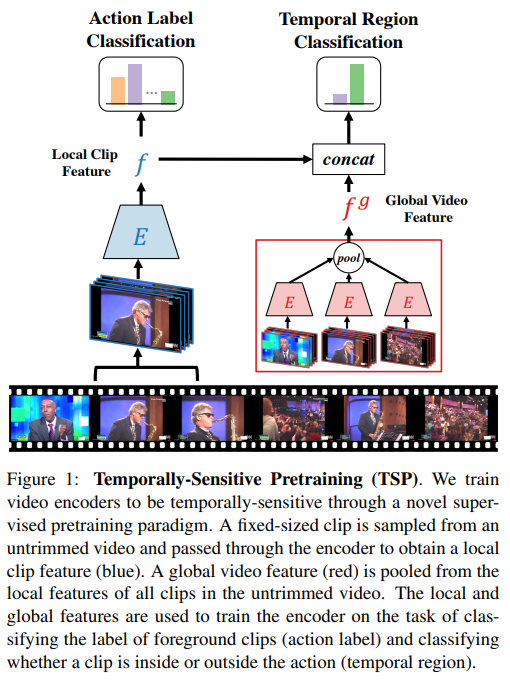
TSP encoder는 Local 과 global feature 로 비디오를 encoding 한다. 우선 Local feature는 untrimmed video의 feature를 F size의 feature로 인코딩 한다. 이 과정을 통해 비디오 V의 클립 X_i에서는 f_i개의 feature가 생성 되는데 이러한 feature들의 max pooling 값이 global video featre (GVF) 가 된다. 본 논문에서 GVF는 비디오에서 foreground와 background를 구별하는 vector로 작용한다고 한다. 해당 논문에서는 모든 비디오를 30fps 기준으로 재가공하여 2frame 간격으로 추출된 clip을 사용하였다.
3. 실험 및 분석
봅 논문은 4가지 관점 기준으로 ablation study를 진행하였다. 각 주제는 다음과 같다. target localization task, encoder architecture, localization algorithm, and pretraining dataset.
첫째: target task에 얼마나 적절한지.
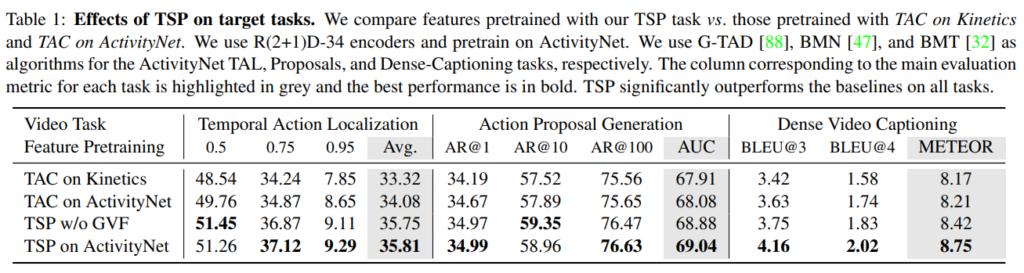
처음 제시한 3가지 target task( Temporal Action Localization, Action Proposal Generation, Dense Video Captioning) 에 대한 성능 향상 실험을 진행하였다. (아쉬운점: GVF의 필요성이 명확히 들어나지 않음)
둘째: TSP for different video encoders
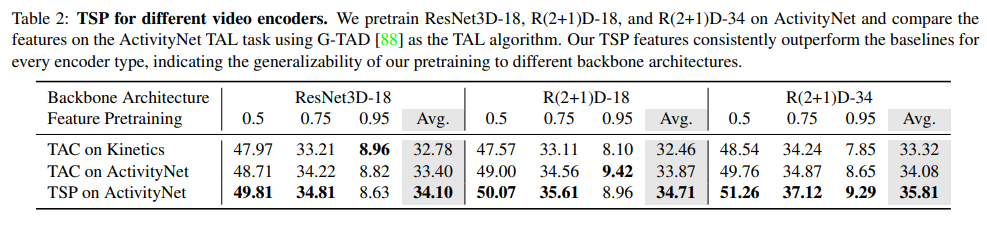
ResNet3D-18, R(2+1)D-18, and R(2+1)D-34 세가지 모델을 사용하여 성능을 측정하였으며, 일반적으로 ResNet3D-18 < R(2+1)D-18 < R(2+1)D-34 순으로 성능이 좋다. 실험시 해당 feature encoder를 도입하였을 때 일반적인 모델간의 성능 차이와 유사한 정도로 성능 향상이 일어나, 더 좋은 encoder 모델사용시 더 좋은 성능을 보일 것이라 예측가능하다고 소개하였다. (아쉬운점: 비교한 모든 모델이 resnet기반 모델임)
셋째: Study 3: TSP with other localization algorithms
TAL( Temporal Action Localization ) 테스크에 G-TAD 와 BMN localization algorithms을 이용하였을때 두 모델 모두 성능향상을 보여 제안하는 방식이 일반적임을 확인할 수 있다 소개 하였다. ( 아쉬운점: 두 모델의 구조적 차이점, 왜 두 모델로 비교했는지 밝히지 않음)
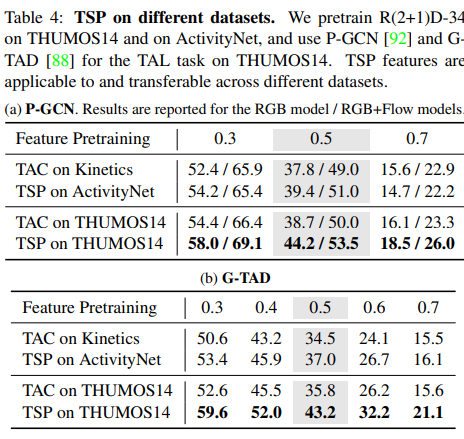
넷째: TSP on different datasets
THUMOS14, ActivityNet 데이터셋으로 각각 pretrain 후 test 진행.
(THUMOS14 vs ActivityNet : THUMOS14 데이터셋이 더 작고, 각 영상에서 background의 비율의 큼.)
untrimmed video라는게 검색을 해도 잘 나오지 않던데 혹시 어떤 개념인지 간단하게 설명해주실 수 있나요?
하나의 label값의 clip으로 구성된 영상이 아닌 foreground와 background 영역의 구별이 필요한 영상입니다. 예를들어 말타기 영상이라면 foreground(말타기)와 background (승마장, 말발굽 등등)
“이를 좀 더 자세하게 말하자면, 기존의 연구들은 Trimmed Action Classification(TAC) task를 위한 pretrained 모델을 통해 video encoder를 구성하는데, 이러한 방식으로 구성된 encoder는 localization task에 적합하지 않다. TAC task 에서는 action이 포함된 foreground segments와 background segment가 유사하기 때문이다.”
로 설명해주셨는데 이는 하나의 action만을 포함하고 있는 trimmed 비디오에서의 action localization보다 두 개 이상의 action이 포함되어 있는 untrimmed 비디오에서 특정 action을 localization하는 것이 적합하다는 것으로 이해하면될까요?
기존의 연구는(TAC) video의 foreground 의 label에 해당하는 분류를 위주로 진행했다면
TAL는 foreground 의 label 뿐만 아니라 하나의 비디오에서 foreground 영역과 background 영역을 구별하는 task도 수행해야한다는 뜻 입니다!