안녕하세요. 이번주 리뷰는 간단하게 YOLO-ACN에 대해서 하겠습니다. 해당 논문을 리뷰하게된 이유는 저희가 이번에 논문 리비전 중인 MLPD에 참고가 될까해서 인데요. 음… 글쎄요.
먼저 이논문은 YOLO V3에서 영감을 얻어서 시작한 연구라고 합니다. 그리고 speed, accuracy, small objects, occluded object를 효과적으로 처리했다고 하는데 한번 살펴봅시다.

아키텍쳐입니다. 인풋이미지로 RGB만을 받고, 크게 3가지로 나뉜 네트워크를 이용하여 object detection task를 수행합니다.
- Feature extraction
- Feature fusion
- Forecast result
이 과정에서 총 4가지의 방법을 제시합니다.
- Attention mechanism
- CIoU
- Soft-NMS
- Seperable depthwise convolution
결론적으로 얘기하자면, attention기법을 사용하여 small object를 더 잘 찾게 하였고, 좀 더 정확한 BBOX regression을위해 CIoU와 soft-NMS를 사용하였습니다. 그리고 모델이 좀 더 가벼워지도록 Depthwise seperable convolution을 사용하였습니다.
이렇게 해서 결과가 기존 single-stage 모델인 SSD513보다 2.9배 정도 높은 정확도를 보였으며 이는 two-stage 모델인 R-CNN과 비슷한 수준입니다. 또한, 작은물체에 대해 mAP가 기존 YOLOv3보다 더 높았으며, 적외선 영상에서도 좋은 성능을 보였습니다.
사실 리뷰하게된 이유중 가장 큰 이유는 적외선 영상에서도 좋은 성능을 보였기 때문인데요. KAIST dataset에서 적외선 영상만을 사용하여 학습하였을때, YOLOv3 이겼으며, 이를 통해 universality 가 높고, 스몰오브젝트, occluded object에 강인하다고 주장합니다.
다시 아키텍쳐로 돌아가서 설명을 이어가봅시다.

feature extraction하는 부분중 residual block은 위와같이 1×1 ConV를 거치고, depthwise seperable convolution을 지난다음 위와같은 방법으로 attention 기법을 적용하였습니다. 이 때, depth wise conv를 사용하는 것은 모델의 경량화를 위한 것이라고합니다. 해당 논문에 설명은 생략되어있고 레퍼런스로 달려있는데 저는 일단 관심이 가지않아서 읽어보지 않았습니다.

채널 attention module은 위와같이 2개의 다른 pooling을 적용하고 합친 후 FC layer를 통과시키는 식으로 attention weight를 생성합니다.

Spatial attention module에서는 인풋 피쳐맵이 max pooling과 average pooling을 거치고 conv layer에 태워지며 spatial한 정보를 합칩니다.

다시 아키텍쳐로 돌아가서… 해당 attention이 적용된 res block들을 거치며 해상도를 점점 줄여가며 high-level feature들을 뽑아내고 Upsampling을 거쳐 위의 그림과같이 concatenate해줍니다. 즉, feature map들을 각기 다른 resolution에서 합쳐주며 다양한 스케일의 object를 검출할 수 있게 합니다.
그렇게 합쳐진 Feature map들은 CBH Conv에 태워지고 최종 prediction값들을 배출하는데, 이때, CBH는 어려운 개념이 아니라 Convolution/Batch norm/hard-swish 3개를 통칭하는 말 입니다.
특이한 점으로는 activation을 hard-swish를 썻는데요. 이는 기존 욜로v3에서 Leacky-ReLU보다 속도를 개선하기 위함이라고 합니다.
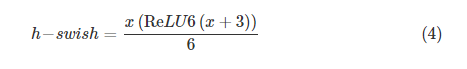
Hard-swish는 위와같이 정의되구요. ReLU6는 upper limit이 6이란 뜻 입니다. 그리고 3칸 왼쪽으로 shift시키고요. 그리고 이값을 sigmoid와 비슷한 형태를 띄게 하기위해 6으로 나누어줍니다.

이번에는 intersection area에 대해서 이야기 해보겠습니다. IoU라는 개념은 익숙하실텐데요. IoU만을 사용하면 겹쳐지는 면적은 중요하게 작용하지만, BBOX가 어떠한 위치에 있는지는 무시될 수 있습니다. 즉, 위의 그림처럼 BBOX가 다양한 위치에서 intersection area를 만드는데 IoU를 사용하면 해당 정보를 고려하지 못합니다.
그래서 YOLOv3에서는 GIoU라는 개념을 사용합니다.
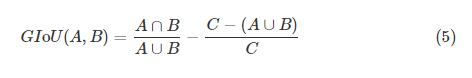
GIoU는 다음과같이 정의되며, C는 A박스와 B박스에 의해서 포함되는 가장큰 사각형의 면적을 의미합니다. 이렇게 정의를하면 위의 그림에서 3가지 경우 모두 IoU는 같지만 GIoU는 다르게 됩니다.
그러나 이러한 GIoU도 한계가 있다고 논문에서는 주장합니다. 그 이유는 GT bbox와 예측된 bbox가 good alignment direction을 가질때 IoU를 계산하는 과정에서 발산할 수 있기 때문이라고합니다. 그래서 좀 더 수렴을 빠르게하는 CIoU를 제안합니다.
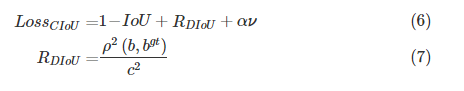
CIoU에서는 위와 같이 정의되며, 이때, DIoU에서 c값은 2개의 바운딩박스로인해 만들어지는 가장작은 사각형의 대각선길이를 의미합니다. 그리고 로우는 바운딩박스의 센터의 거리를 나타내는 함수입니다. 마지막으로 v는 bbox들의 AR의 유사성을 측정하는 텀입니다.
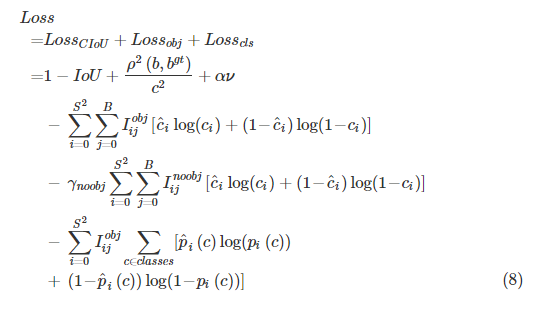
IoU대신 CIoU를 썻다는 점을 제외하고 LOSS들은 일반적인 detection에서 사용되는 loss들이 사용되었습니다.
이번에는 기존 NMS를 어떻게 개선했는지 이야기 해보겠습니다.
기존 NMS는 low-confidence인 경우에 제거를 하는데 이렇게되면 문제점이 occluded object에 대한 bbox까지도 제거할 가능성이 있습니다.
또한, manually thereshold를 설정하는 것도 기존 NMS의 단점이었습니다.
이에 Soft-NMS를 사용하였는데요. 수식은 아래와 같습니다.
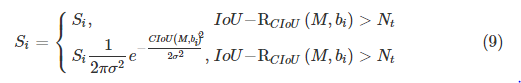
이때 S는 현재 BBOX의 스코어이고 b는 predict된 bbox의 스코어입니다. 그리고 M은 가장 높은 스코어를가진 bbox의 스코어이며, N은 2개의 bbox가 오버랩되었는지 판단하는 threshold입니다.
이 식이 의미하는 것은 만약 predict된 bbox와 가장 높은 스코어를 가진 bbox의 오버랩된 곳이 많을수록 suppression이 강해지고, confidence 스코어는 작아집니다. 이렇게하게되면 predicted boxes를 좀 더 suppression하고, occluded objects에 좀 더 focus할 수 있어서 occlusion 문제를 어느정도 해소할 수 있습니다.
앞의 3개 컬럼은 bbox loss이구 뒤에는 스코어들입니다. 잘 수렴했고 성능도 올랐다 이런거같은데… 사실 왜 굳이 페이지 아깝게 넣었는지 잘 모르겠습니다.

정성적으로도 잘 나왔다고 얘기하네요.
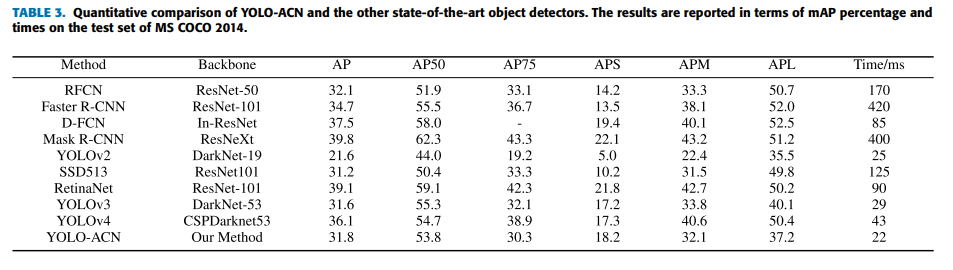
object크기에따라서 AP를 따로 뽑는 실험도 했네요.
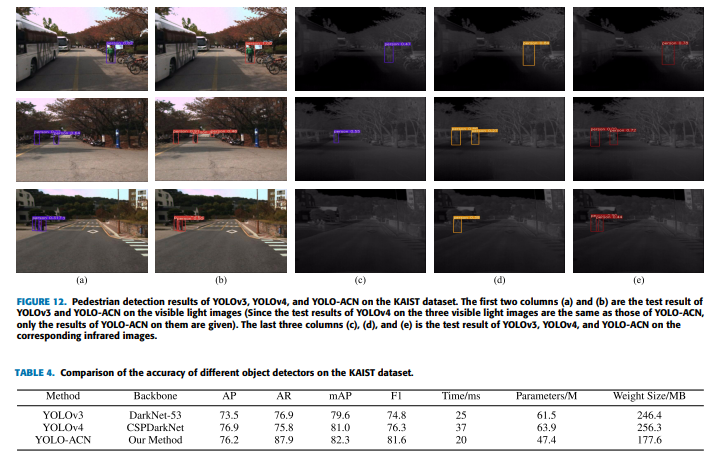
카이스트셋에서의 실험인데 Parameter의 개수와 weight의 사이즈가 다른 비교 모델군에비해 줄어들었음에도 불구하고 성능은 더 좋네요.
이상 리뷰 마치겠습니다.
글 잘 읽었습니다.
질문이 있는데, 먼저 채널 어텐션 모듈에서 fc layer를 사용한다고 나와있는데, max pooling한 feature map과 avg pooling을 한 feature map을 합친다는 의미는 단순히 sum을 하는 것인가요?
그리고 fc layer를 통과하여 나온 출력이 2 종류의 feature map이고 이를 합쳐서 sigmoid 함수를 적용하는 것처럼 보이네요. 여기서 궁금한 점이 fc layer의 output은 1D vector인데 이를 2 종류의 feature map으로 나누는 방식은 어떻게 되나요? fc layer를 각각 따로 태워서 만드는 것이 아닌 하나의 fc layer에서 2종류의 feature map을 만든다는 것이 쉽게 와닿지 않네요.
빠른 논문 리뷰 감사합니다.
먼저, 이 논문 풀네임이 뭔가요? 저자가 기여라고 주장한 부분이 뭔지 궁금합니다.
기여가 IoU랑 NMS 개선한 부분이겠죠?
근데 IoU과 GIoU 차이를 생각해보면 대각 방향의 후보군들에는 제약은 두는 방법이라고 생각이 듭니다. 논문에 앞에서 말한 제약을 준 이유에 대해 좀 더 명확한 사유 혹은 실험 결과를 제시한 내용이 있을 까요???
NMS에서도 수식 9번의 상하 조건부 수식이 동일한데… 어느 때 뭘 쓰라는 건지 모르겠네요… 설명을 믿으면 될까요??