1편에 이어서 글을 작성해보려고 합니다.
Positional Encoding
기존의 NLP 문제를 풀기 위해 사용했던 RNN 모델들은 문장 속 단어의 순서와 위치 정보를 다 고려하여 학습을 진행하였습니다.
하지만 Transformer는 RNN 구조가 아니기 때문에 입력 문장 속 단어들의 위치 정보를 고려하며 학습하지는 않고 있습니다. 이 문제를 해결하기 위해 입력으로 들어온 임베딩 벡터에 positional encoding이라는 벡터를 더해줍니다.
positional encoding vector는 단어 임베딩 벡터와 동일한 사이즈를 가지고 있으며, 각 셀의 값은 -1 ~ 1 사이의 값을 가진다고 합니다.
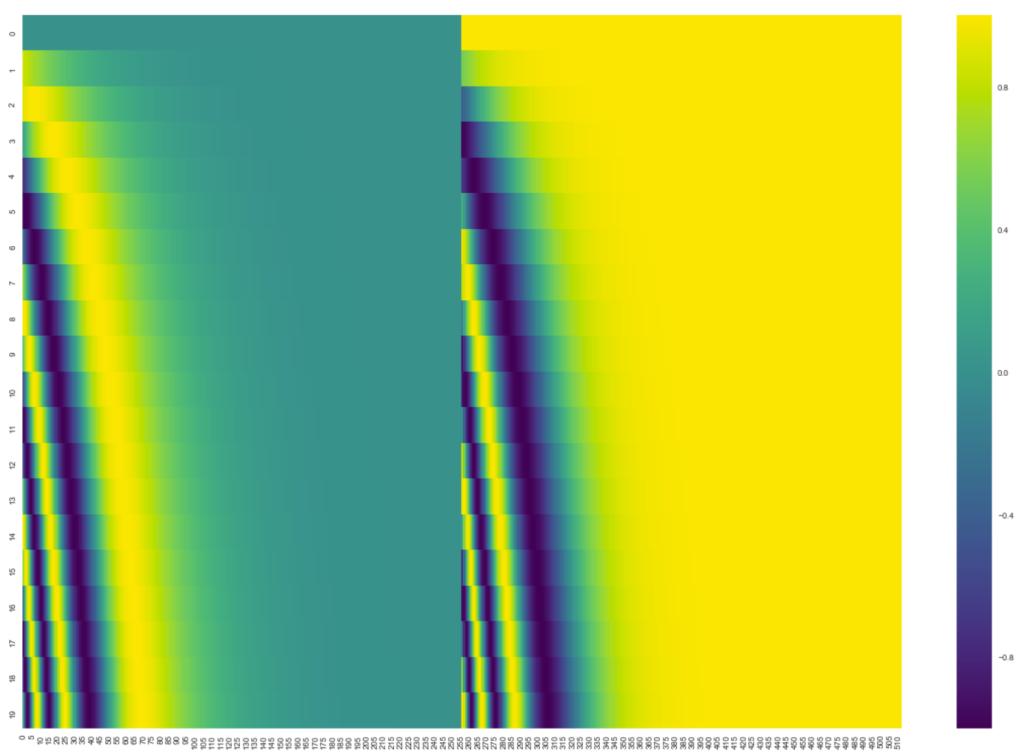
그림1은 positional encoding 벡터를 시각화 한 그림으로, y축은 단어의 개수(총 20개)를 나타내며 x축은 해당 positional encoding vector의 길이 (512)를 의미합니다.
중간을 기준으로 좌측과 우측이 다르게 보이는데, 이는 positional encoding vector를 만들 때 sin 함수와 cos함수로 생성했기 때문입니다.
positional encoding vector를 만드는 방식으로 sin과 cos함수 외에도 여러 다양한 방법들이 존재하지만, 해당 논문에서 최종적으로 sin/cos 함수를 사용한 이유는 모델이 학습 때 보았던 제일 긴 문장보다 더 긴 문장이 입력으로 들어오더라도 문제없이 positional encoding을 생성할 수 있기 때문입니다.
Decoder
디코더의 구조는 인코더의 구조와 매우 유사해서 디코더의 구조에 대해서만 살짝 설명하고 그 다음에 디코딩 전체에 대한 진행과정에 대해서 알아보겠습니다.
디코더는 인코더와 마찬가지로, 6개의 디코더 블럭으로 이루어져있습니다. 인코더 블럭 내에는 attention layer와 forward layer로 총 2개가 존재하지만 디코더 블럭은 attention layer와 forward layer 사이에 1개의 layer가 더 추가됩니다.
여기서 눈여겨 보실 점은 먼저 디코더의 attention layer는 encoder의 attention layer와 조금 다른데, 인코더의 경우 attention layer의 처음 입력으로 positional encoding 벡터가 포함된 word embedding vector가 더해진 벡터를 사용하였다면, 디코더의 경우에는 output sequence 내에서 현재 위치의 이전 위치 벡터들만을 사용합니다.
이러한 방식은 self-attention 계산 과정에서 softmax를 취하기 전에, 현재 단계 이후의 위치들에 대한 마스킹(-inf 연산)을 해주면 가능합니다.
또한 디코더에서 새로 추가되는 레이어는 “encoder-decoder attention” layer로 불리며 입력으로 이전 디코더 레이어의 query와 인코더 블럭들의 output에서부터 나온 key, value 값을 받아 multi head attention을 하는 레이어입니다.
위에 gif는 인코더 블록들을 통해 나온 output 벡터로 key와 value 벡터들을 만들며, 이를 디코더의 첫번째 블록에 태웁니다. 그리고 첫번째 디코더 블록에서 나온 output이 2번째 디코더의 입력으로 들어가며 동시에 인코더의 key와 value 벡터들을 다시 한번 사용하여 multi head attention을 수행합니다. 이 과정을 디코더 블럭의 끝으로 갈 대까지 계속 진행합니다.
그 후에 output 결과가 나왔다면 위에 gif와 같이 이전 output 결과를 decoder 첫번째 블록에 입력으로 사용하며 다시 인코더에서 나온 key와 value 벡터들이 사용됩니다. 이러한 과정은 문장의 끝에 해당하는 end of sentence가 나올때가지 수행합니다.
이렇게 디코더 블록들을 통과하면 최종적으로는 벡터가 하나 나오게 됩니다. 이러한 벡터를 단어로 바꾸기 위해 그림2와 같이 Linear layer와 Softmax를 사용합니다.
간략하게만 말씀드리면 Linear layer를 통해 벡터의 차원을 더 크게 늘리는데 이때 차원의 쵲오 크기는 학습 데이터에서 가르치고 싶은 단어의 총 개수와 일치하면 됩니다. 예를 들어 모델이 총 10,000개의 영어 단어를 학습한다고 하면, Linear layer를 통과해서 나온 벡터의 크기는 10,000이 되어야 한다는 것이죠.
그 다음에 이 벡터를 softmax 처리해줌으로써 확률 값으로 나타내며, 이 중 가장 확률이 높은 값으로 argmax하면 해당 위치에 사용할 단어가 나타나게 되는 것입니다.
Loss
Loss 함수로는 아주 간단하게 Cross entropy loss를 사용했다고 합니다.
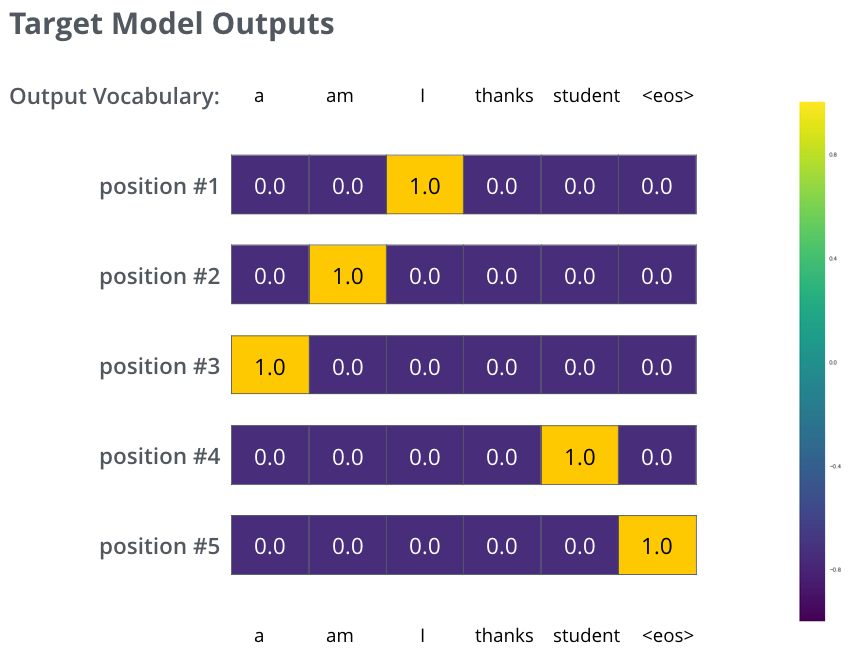
그림 3번은 transformer 모델이 학습하기 위한 GT를 나타낸 것으로 디코더의 아웃풋은 결국 모델이 학습한 단어사전의 길이(ex: 1만개)만큼의 크기를 가지는 확률분포입니다.
그래서 첫번째 단계에서는 I에 위치한 셀에 확률 값이 1에 가깝도록 학습해야하며, 두번째 단계에서는 am에 위치한 셀에 확률이 1에 가깝고 나머지는 0에 가깝도록 확률 분포를 학습하는 것이죠.
실험 결과에 대한 분석은 NLP 관련 분야에 대해 문외한이며 image 기반 transformer에 대한 논문을 읽기 전에 사전 지식 쌓기로 읽어본거라 nlp 결과 내용에 큰 관심이 없어서 해당 내용은 패스하도록 하겠습니다.
안녕하세요,
정민 연구원님, 1편에 이어지는 좋은 글 감사합니다.
읽으며 한 가지 이해한 내용을 정리해보았는데, 그 부분이 맞는지 확인하고 싶습니다.
Decoder의 Self-Attention에서 마스킹을 적용하는 이유에 대한 내용입니다.
Encoder와 Decoder 모두 Self-Attention 구조를 사용하지만,
Decoder에서는 현재 시점 이후의 단어를 보지 않도록 마스킹을 한다고 하셨습니다.
저는 이 부분을 Autoregressive 구조를 구현하기 위한 장치라고 이해했습니다.
즉, Decoder는 다음 단어를 예측해야 하므로 미래 정보를 미리 보면 안 되고,
이를 방지하기 위해 마스킹이 필요하다는 의미로 받아들였습니다.
혹시 이런 흐름이 맞는지 궁금합니다