

이전 Action Retrieval을 위해서 ActivityNet을 다운 받고 다운로드 페이지 정도의 내용만 이해하여 사용하였었으나 올해 CVPRW 에서 열리는 ActivityNet Challenge에 참여할 예정이기에 보다 ActivityNet 데이터 셋에 자세히 알고자, 이전 투고되었던 논문을 읽고 리뷰합니다.
1. Building ActivityNet
1.1 Defining the Activity lexicon
Object를 중심으로 나타나는 데이터 셋은 주로 한 이미지에 특정 Object가 표현되어 있기만 하면 됩니다. 그러나 이와 달리, ActivityNet에서 나타내고자하는 Activity들은 단순히 한 이미지만 보고 판단하기에는 모호한 점이 많으며, Activity를 잘 판단하기 위해서는 여러 이미지를 보고 이들 간의 semantic한 정보를 고려하는 것이 필요로 하게 됩니다. 이러한 제약사항이 많은 이유로 ActivityNet이 나오기 이전에는 Activity를 구체적으로 표현하거나 풍부했던 데이터 셋이 없었습니다.
ActivityNet은 위와 같은 문제점을 인식하고 보다 Activity를 구체적으로 나누어 각 Activity에 대해 풍부한 데이터를 제공하고자 우선 Activity taxonomy를 구성해 만들어졌던 Activity lexicon 를 활용하였습니다. 여기서 taxonomy란 어떤 것에 대한 분류법이란 뜻으로, lexicon은 분류 후 만들어진 사전이란 뜻으로 이해하시면 되겠습니다.
Activity taxonomy를 구성하고자 American Time Use Survey에서 실행한 조사결과를 토대로 ATUS taxonomy를 활용했습니다. ATUS taxonomy는 사회적 상호작용과 Activity가 발생되는 장소라는 두 가지 차원에 총 2000개가 넘는 Activity들이 분류되어 있으며, 이를 통해 만들어진 ATUS lexicon은 Personal Care, Work-Related, Education, Household와 같은 18가지의 최상위 분류로 구성되어집니다. 그리고 최상위 분류 하위에는 해당 최상위 분류를 보다 세밀하게 나눈 두 차원 이상의 하위 항목이 존재합니다.
ActivityNet은 이와 같은 ATUS lexicon에서 서로 다른 7가지 최상위 분류에서 총 203가지의 하위 항목을 선택하였습니다. 최상위 분류는 각각 Personal Care, Eating and Drinking, Household, Caring and Helping, Working, Socalizing and Leisure, Sports and Exercises 이며 Fig 2는 이 중 Household에 대해 하위 항목을 포함해 네 가지의 계층 구조를 나타냅니다.
1.2 Collecting and annotating human activities

앞서 나눈 하위 항목의 Activity를 기준으로 비디오를 찾고 annotation 과정을 진행하기 위해 우선 YouTube에서 비디오를 모았습니다. 모을 때는 text 기반으로 비디오를 검색하였으며, WordNet 기반으로 query expansion 기법을 사용해 보다 많은 비디오가 검색되었습니다. 이후, 비디오에서 Untrimmed 비디오에 대해 labeling을 했으며, test 기반 검색의 오차로 발생한 연관되지 않은 비디오는 제거하였다고 합니다. 여기서 Untrimmed 비디오란 특정 하나의 행동 혹은 단일 배경의 사건으로만 구성되지 않고 배경이 바뀌는 여러 행동 혹은 사건으로 구성된 비디오를 의미합니다. 이후 Untrimmed 비디오 내에서 특정 Activity에 대한 instance를 찾아내어 trimmed 비디오 labeling을 진행하였다고 합니다. 특이한 점으로는 semi-auto 방식으로 annotation을 진행했다길래 어떤 방법인가 했는데, Amazon Mechanical Turk(AMT)에 외주 맡겼다고 합니다.
1.3 ActivityNet at a Glance
ActivityNet은 위와 같은 과정으로 진행되었으며, YouTube에서 다운로드 시 각 비디오 별로 최대의 해상도로 설정되었습니다. 또한 총 메모리를 고려하여 20분보다 짧은 비디오 만으로 구성되었으며, 평균 5~10분 정도의 길이로 구성되었습니다. 또한 절반 정도는 HD 해상도(1280×720)이며 대다수는 30FPS 입니다. 그리고 한 Untrimmed 비디오에서 trimmed 비디오는 평균적으로 1.41개 정도이며, 이는 temporal segment로 표시되었습니다.
2. Experiments
2.1 Video Representation
제안된 ActivityNet 데이터 셋에서 여러 feature의 성능을 나타내기 위해 다음과 같은 feature를 사용하였습니다.
- Motion Feature (MF)
비디오에서 local한 영역의 motion 패턴을 찾아내는 feature로 HOG, HOF, HBH라는 알고리즘이 사용되었습니다. 이러한 local descriptor들을 모아 Fisher Vector로 기술해 사용하였습니다.
- Static Feature (SF)
특정 장면에 대한 spatial 정보를 포함하는 feature로 SIFT 기반 Fisher Vector가 사용되었습니다.
- Deep Feature (DF)
이 당시에는 비디오에서 3D convolution 모델이 잘 사용되지 않던터라 AlexNet이 사용된 듯 합니다. AlexNet에 연결된 fully connected layer의 feature map을 각각 활용하여 fc-6, fc-7, fc-8로 표현되었으며, 여러 프레임에서의 feature map을 averaging하여 temporal 정보가 합쳐졌습니다.
2.2 Benchmarks
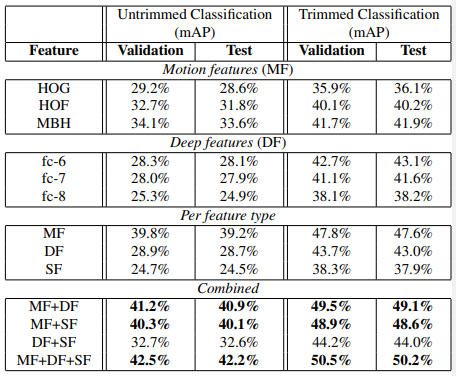
총 두 가지 task, Untrimmed Classification과 Trimmed Classification에 대해 Benchmarking이 진행되었으며, 앞서 언급한 feature를 활용했습니다.
Untrimmed Classification의 경우 총 203가지의 Activity 종류의 27801개의 비디오를 사용했으며, 그 중 50%는 train, 나머지는 절반씩 validation, test로 선정되었습니다. 그리고 각 feature에 대한 분류기로는 SVM이 사용되었으며 mAP의 평가지표가 사용되었습니다. 이 task의 경우, 단일 feature로는 motion이 embedding된 MF가 가장 높은 성능을 보였으며, feature를 융합해서 쓰더라도 MF가 포함되어 있어야 성능향상을 보였습니다. 이는 semantic한 정보, 즉 연속된 프레임 간의 motion 정보로 정해지는 Activity의 특성 상, motion 정보가 다른 정보에 비해 가장 큰 영향을 미치는 것을 암시합니다.
Trimmed Classification의 경우, 203가지의 Activity 종류 별로 평균적으로 각각 193가지 비디오를 사용했으며, 앞선 경우와 마찬가지로 SVM이 사용되었습니다. 그리고 경향성 또한 마찬가지로 motion 정보를 포함한 MF가 가장 성능이 좋고 가장 영향력있는 것을 보였습니다.
3. Reference
[1] https://openaccess.thecvf.com/content_cvpr_2015/papers/Heilbron_ActivityNet_A_Large-Scale_2015_CVPR_paper.pdf